PaddleDetection

PaddleDetection copied to clipboard
YOLOX_nano自有数据集训练,loss_cls波动不收敛,AP几乎为0
问题确认 Search before asking
Bug组件 Bug Component
Training
Bug描述 Describe the Bug
我使用yolox-nano训练自有的数据集(COCO格式),是无人机的航拍图像,目标比较小,总共有10类。在配置文件里面修改了base_lr=0.001,batch_size=64,输入尺寸416,单卡训练,关闭了mosaic数据增强(之前使用base_lr=0.01并且开启mosaic就会出现这个问题,所以我尝试调小lr并关闭mosaic,但并没有解决)
出现loss_cls不收敛,且bbox-mAP几乎为0的情况

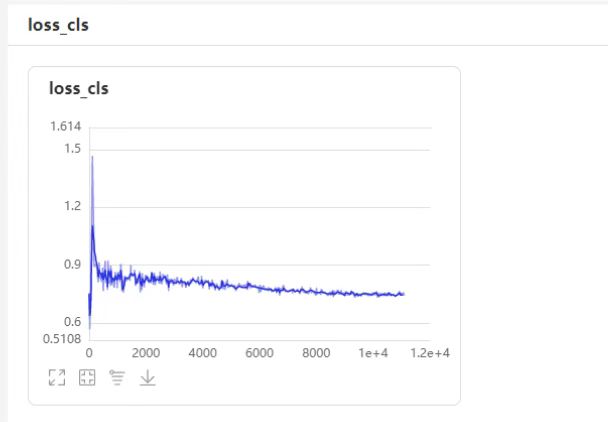 同样的数据集使用picodet模型训练是没有问题的,loss都能正常收敛
同样的数据集使用picodet模型训练是没有问题的,loss都能正常收敛
复现环境 Environment
-OS:Windows -PaddlePaddle:2.2.2 -PaddleDetection:release/2.5 -Python:3.7 -CUDA:11.2 -CUDNN:8.5
Bug描述确认 Bug description confirmation
- [X] 我确认已经提供了Bug复现步骤、代码改动说明、以及环境信息,确认问题是可以复现的。I confirm that the bug replication steps, code change instructions, and environment information have been provided, and the problem can be reproduced.
是否愿意提交PR? Are you willing to submit a PR?
- [ ] 我愿意提交PR!I'd like to help by submitting a PR!
同环境版本下,我大致按照你的改动训了是可以训出来mAP的,1epoch有0.036 mAP。visdrone 的模型已开放详见visdrone,且visdrone上已做过对比实验,yolox精度低于ppyoloe很多。
更改了yolox_nano_300e_coco.yml为以下:具体改动点也可以自行和coco原版对比
_BASE_: [
# '../datasets/coco_detection.yml',
'../datasets/visdrone_detection.yml', # wget https://bj.bcebos.com/v1/paddledet/data/smalldet/visdrone.zip
'../runtime.yml',
'./_base_/optimizer_300e.yml',
'./_base_/yolox_cspdarknet.yml',
'./_base_/yolox_reader.yml'
]
depth_mult: 0.33
width_mult: 0.25
log_iter: 100
snapshot_epoch: 2 # 10
weights: output/yolox_nano_300e_coco/model_final
pretrain_weights: https://paddledet.bj.bcebos.com/models/yolox_nano_300e_coco.pdparams
### model config:
# Note: YOLOX-nano use depthwise conv in backbone, neck and head.
YOLOX:
backbone: CSPDarkNet
neck: YOLOCSPPAN
head: YOLOXHead
size_stride: 32
size_range: [10, 20] # multi-scale range [320*320 ~ 640*640]
CSPDarkNet:
arch: "X"
return_idx: [2, 3, 4]
depthwise: True
YOLOCSPPAN:
depthwise: True
YOLOXHead:
depthwise: True
### reader config:
# Note: YOLOX-tiny/nano uses 416*416 for evaluation and inference.
# And multi-scale training setting is in model config, TrainReader's operators use 640*640 as default.
worker_num: 4
TrainReader:
sample_transforms:
- Decode: {}
- Mosaic:
prob: 0.0 # 1.0 in YOLOX-tiny/s/m/l/x
input_dim: [640, 640]
degrees: [-10, 10]
scale: [0.5, 1.5] # [0.1, 2.0] in YOLOX-s/m/l/x
shear: [-2, 2]
translate: [-0.1, 0.1]
enable_mixup: False # True in YOLOX-s/m/l/x
- AugmentHSV: {is_bgr: False, hgain: 5, sgain: 30, vgain: 30}
- PadResize: {target_size: 640}
- RandomFlip: {}
batch_transforms:
- Permute: {}
batch_size: 48 # 8 # 64 will OOM on single P40 GPU
shuffle: True
drop_last: True
collate_batch: False
mosaic_epoch: 30 #285
EvalReader:
sample_transforms:
- Decode: {}
- Resize: {target_size: [416, 416], keep_ratio: True, interp: 1}
- Pad: {size: [416, 416], fill_value: [114., 114., 114.]}
- Permute: {}
batch_size: 8
TestReader:
inputs_def:
image_shape: [3, 416, 416]
sample_transforms:
- Decode: {}
- Resize: {target_size: [416, 416], keep_ratio: True, interp: 1}
- Pad: {size: [416, 416], fill_value: [114., 114., 114.]}
- Permute: {}
batch_size: 1
epoch: 36
LearningRate:
base_lr: 0.001 # 0.01
schedulers:
- !CosineDecay
max_epochs: 36 # 300
min_lr_ratio: 0.05
last_plateau_epochs: 3 # 15
- !ExpWarmup
epochs: 1 # 5
然后单卡训练:
CUDA_VISIBLE_DEVICES=0 python3.7 tools/train.py -c configs/yolox/yolox_nano_300e_coco.yml --amp --eval
我有遇到过类似的问题,我是自己的数据,一开始训练ap是有上升的,后面数据做了一些改动,再训练就不会动了。然后换其他的模型,和数据重新跑一次,再切回来就好了,不知道什么问题,可能是中间过程有什么cache影响了吧?