Paddle
 Paddle copied to clipboard
Paddle copied to clipboard
PArallel Distributed Deep LEarning: Machine Learning Framework from Industrial Practice (『飞桨』核心框架,深度学习&机器学习高性能单机、分布式训练和跨平台部署)

### bug描述 Describe the Bug ### 代码 ```python import paddle x1 = paddle.Tensor(np.arange(9).reshape(3, 3)) y1 = paddle.Tensor(np.arange(12).reshape(3, 4)) z = paddle.matmul(x1, y1) ``` ### 报错内容 ```bash NotFoundError: Operator matmul_v2 does...
### bug描述 Describe the Bug ### 报错信息 ```bash Error Message Summary: ---------------------- NotFoundError: There are no kernels which are registered in the dist operator. [Hint: Expected kernels_iter != all_op_kernels.end(), but...
### 请提出你的问题 Please ask your question 你好 我试图在问答模型中使用自建数据集 数据集训练集为`(context, question, start, end)`, 测试集为`(context, question)` 我尝试了`paddle.io.Dataset`和`paddlenlp.datasets.MapDataset`, 都会在传入`paddle.io.DataLoader`的时候失败 可以提供一个案例么, 从`[(context,question,start,end)...]`列表对开始 步步建立数据集 我找到的教程要么是内置dataset 要么就是其他任务的,主要是视觉任务 我水平有限参考不出来 感谢
### 问题描述 Please describe your issue I'm training a custom dataset on the SETR model but it throws the same error though the GPU has enough memory. I've tried reducing...
### 需求描述 Feature Description Now many unit tests use `assertTrue(np.allclose(x, y), "error message")` to compare two tensors, but its error message is helpless. Because `assertTrue` cannot tell developer the details,...
### bug描述 Describe the Bug Now many Paddle-TRT unit-tests include FP16 testing. However, the approach is to compare the results generated from Paddle-Inference with FP32 computation and the results generated...
## 最近把一个torch模型改为paddle,参加一下比赛。发现训练速度要比torch慢了很多。 两个模型的差别不大,主要就是把一些用torch的运算改为paddle的了。 ## 训练的时候,发现,程序能跑。但是,相比于torch慢了很多(两者的所有超参数都是保持一致的,数据集什么的都一致)。 于是我认为可能是数据加载的时候有拉胯了。 这是torch运行速度以及占用   这是paddle运行速度以及占用  我把模型训练以及验证的部分全部注释掉。发现确实慢。 当我使用paddle.set_device("cpu")时,发现没有任何提升。 ## 于是我认为可能是paddle处理的就慢, 于是把数据处理中的paddle操作。  类似上图的,中间都用np进行处理了。  右侧用paddle框架的加载速度直接速度提升了3倍。运来只有100it/s多的迭代速度 但是再次进行训练时,速度仍然没有得到改善。 于是我认为,是模型里面存在大量的paddle计算操作,所以很慢。 后来发现了这个帖子https://gitee.com/paddlepaddle/Paddle/issues/I3S49J 跟我想的基本一致,paddle跟numpy之间的转换效率低。而torch这点做的挺不错。 希望你们能快点进行优化,这已经是2.3版本的了,你们说会解决,还没解决。 同样的数据集。网络torch一轮训练5小时,paddle得训练13个小时,即使用V100来训练,也会很大程度上的浪费资源。这可不是开玩笑的效率低。希望你们可以重视并优化。
### 问题描述 Issue Description  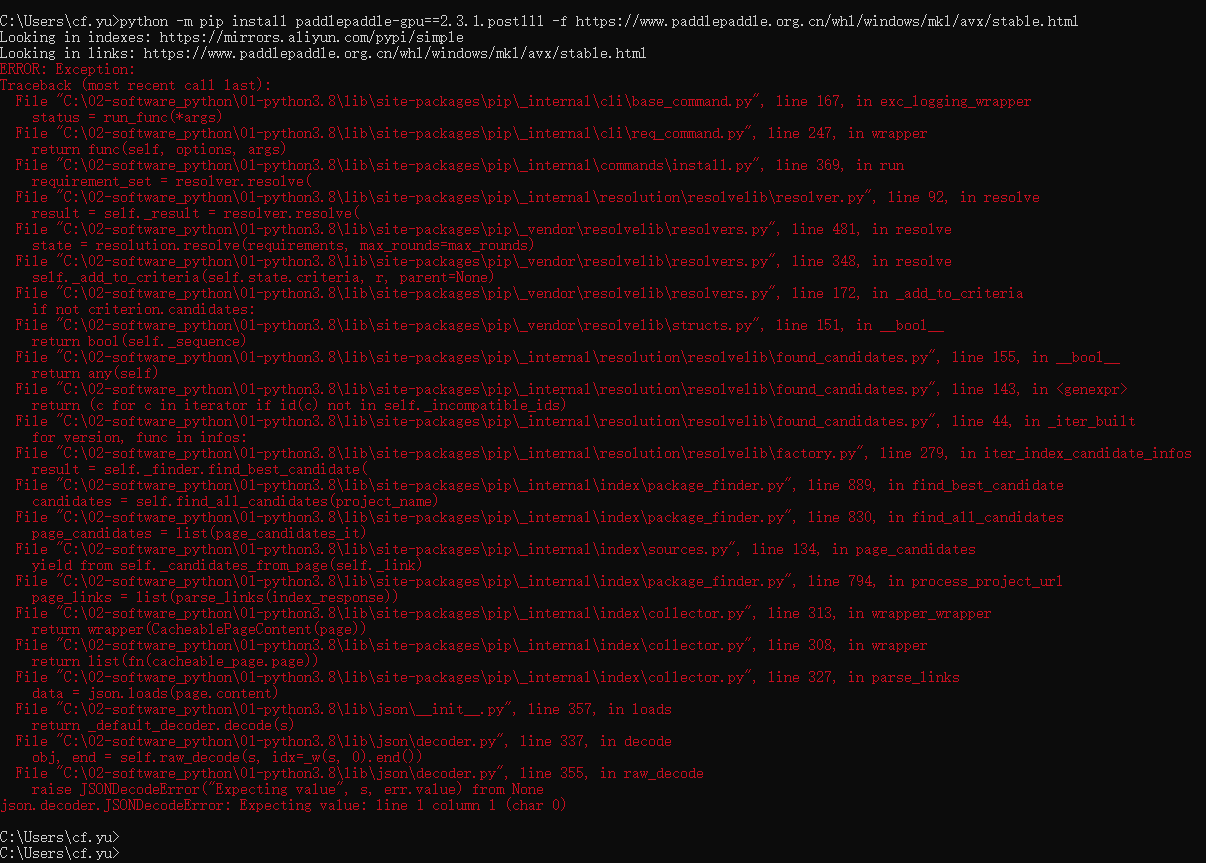 ### 版本&环境信息 Version & Environment Information C:\Users\cf.yu>python -m pip install paddlepaddle-gpu==2.3.1.post111 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html Looking in indexes: https://mirrors.aliyun.com/pypi/simple Looking in links: https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html ERROR: Exception:...
DPIN(https://arxiv.org/abs/2106.05482 )并没有开源数据集和代码,在比赛任务页面也并没有提供相关资料,而任务要求为“按照论文数据,预计以DIN模型作为对比,AUC获得性能提升复现后合入PaddleRec套件,并添加TIPC”,请问在哪里获取相关数据集?或者使用什么公共数据集(因为引入了位置信息,一般的公共数据集并不适用这个任务)。
### 问题描述 Issue Description 使用ABS构建CPU型paddle时报错 ``` /home/kevin/python-paddlepaddle/src/build/third_party/gloo/src/extern_gloo/gloo/transport/tcp/device.cc: 在函数‘std::shared_ptr gloo::transport::tcp::CreateDevice(const attr&)’中: /home/kevin/python-paddlepaddle/src/build/third_party/gloo/src/extern_gloo/gloo/transport/tcp/device.cc:152:39: 错误:聚合‘std::array hostname’类型不完全,无法被定义 152 | std::array hostname; | ^~~~~~~~ make[5]: *** [gloo/CMakeFiles/gloo.dir/build.make:496:gloo/CMakeFiles/gloo.dir/transport/tcp/device.cc.o] 错误 1 make[5]: 离开目录“/home/kevin/python-paddlepaddle/src/build/third_party/gloo/src/extern_gloo/build” make[4]: *** [CMakeFiles/Makefile2:184:gloo/CMakeFiles/gloo.dir/all] 错误...
Metadata
Owner
Metadata
PArallel Distributed Deep LEarning: Machine Learning Framework from Industrial Practice (『飞桨』核心框架,深度学习&机器学习高性能单机、分布式训练和跨平台部署)