Paddle
 Paddle copied to clipboard
Paddle copied to clipboard
Published
20 hours ago •
 PaddlePaddle
PaddlePaddle
develop版本paddle.autograd.grad()报错
bug描述 Describe the Bug
develop版本下,paddle.autograd.grad()报错:SystemError: (Fatal) Null autograd_meta gotten from unsafe_autograd_meta() 2.3版本下可正常运行 代码见:https://github.com/PaddlePaddle/PaddleScience/pull/142 报错位置:
for i in range(losses.shape[0]):
grad = paddle.autograd.grad(losses[i], W, retain_graph=True)
norms.append(paddle.norm(self.loss_weights[i] * grad[0], p=2))
其他补充信息 Additional Supplementary Information
No response
hi, @LDOUBLEV 提供了一个复现:
import paddle
import paddle.nn as nn
from functools import partial
import numpy as np
from paddle.nn.initializer import Assign
class GradNorm(nn.Layer):
def __init__(self, net, n_loss, alpha, weight_attr=None):
super().__init__()
self.net = net
self.n_loss = n_loss
self.loss_weights = self.create_parameter(
shape=[n_loss],
attr=Assign(weight_attr if weight_attr else [1] * n_loss),
dtype=self._dtype, is_bias=False)
self.set_grad()
self.alpha = float(alpha)
self.initial_losses = None
def nn_func(self, ins):
return self.net.nn_func(ins)
def __getattr__(self, __name):
try:
return super().__getattr__(__name)
except:
return getattr(self.net, __name)
def get_grad_norm_loss(self, losses):
if isinstance(losses, list):
losses = paddle.concat(losses)
if self.initial_losses is None:
self.initial_losses = losses.numpy()
W = self.net.get_shared_layer()
if self.loss_weights.grad is not None:
self.loss_weights.grad.set_value(paddle.zeros_like(self.loss_weights))
norms = []
for i in range(losses.shape[0]):
grad = paddle.autograd.grad(losses[i], W, retain_graph=True)
norms.append(paddle.norm(self.loss_weights[i]*grad[0], p=2))
norms = paddle.concat(norms)
print("norms: ", norms)
loss_ratio = losses.numpy() / self.initial_losses
inverse_train_rate = loss_ratio / np.mean(loss_ratio)
print("inverse_train_rate: ", inverse_train_rate)
mean_norm = np.mean(norms.numpy())
constant_term = paddle.to_tensor(mean_norm * np.power(inverse_train_rate, self.alpha), dtype=self._dtype)
print("constant_term: ", constant_term)
# grad_norm_loss = paddle.norm(norms - constant_term, p=1)
grad_norm_loss = paddle.sum(paddle.abs(norms-constant_term))
self.loss_weights.grad.set_value(paddle.autograd.grad(grad_norm_loss, self.loss_weights)[0])
return grad_norm_loss
def reset_initial_losses(self):
self.initial_losses = None
def set_grad(self):
x = paddle.ones_like(self.loss_weights)
x *= self.loss_weights
x.backward()
self.loss_weights.grad.set_value(paddle.zeros_like(self.loss_weights))
def get_weights(self):
return self.loss_weights.numpy()
def renormalize(self):
normalize_coeff = self.n_loss / paddle.sum(self.loss_weights)
self.loss_weights = self.create_parameter(
shape=[self.n_loss],
attr=Assign(self.loss_weights * normalize_coeff),
dtype=self._dtype, is_bias=False)
class FCNet(nn.Layer):
def __init__(self,
num_ins,
num_outs,
num_layers,
hidden_size,
activation='tanh'):
super(FCNet, self).__init__()
self.num_ins = num_ins
self.num_outs = num_outs
self.num_layers = num_layers
self.hidden_size = hidden_size
if activation == 'sigmoid':
self.activation = paddle.sigmoid
elif activation == 'tanh':
self.activation = paddle.tanh
else:
assert 0, "Unsupported activation type."
self._weights = []
self._biases = []
self._weights_attr = [None for i in range(num_layers)]
self._bias_attr = [None for i in range(num_layers)]
self.make_network()
def make_network(self):
print("make net")
for i in range(self.num_layers):
if i == 0:
lsize = self.num_ins
rsize = self.hidden_size
elif i == (self.num_layers - 1):
lsize = self.hidden_size
rsize = self.num_outs
else:
lsize = self.hidden_size
rsize = self.hidden_size
w_attr = self._weights_attr[i]
b_attr = self._bias_attr[i]
# create parameter with attr
w = self.create_parameter(
shape=[lsize, rsize],
dtype=self._dtype,
is_bias=False,
attr=w_attr)
b = self.create_parameter(
shape=[rsize], dtype=self._dtype, is_bias=True, attr=b_attr)
# add parameter
self._weights.append(w)
self._biases.append(b)
self.add_parameter("w_" + str(i), w)
self.add_parameter("b_" + str(i), b)
def nn_func(self, ins):
u = ins
for i in range(self.num_layers - 1):
u = paddle.matmul(u, self._weights[i])
u = paddle.add(u, self._biases[i])
u = self.activation(u)
u = paddle.matmul(u, self._weights[-1])
u = paddle.add(u, self._biases[-1])
return u
def get_shared_layer(self):
return self._weights[-1]
loss_func = [paddle.sum, paddle.mean, partial(paddle.norm, p=2), partial(paddle.norm, p=3)]
def cal_gradnorm(ins,
num_ins,
num_outs,
num_layers,
hidden_size,
n_loss=3,
alpha=0.5,
activation='tanh',
weight_attr=None):
net = FCNet(
num_ins=num_ins,
num_outs=num_outs,
num_layers=num_layers,
hidden_size=hidden_size,
activation=activation)
for i in range(num_layers):
net._weights[i] = paddle.ones_like(net._weights[i])
grad_norm = GradNorm(net=net, n_loss=n_loss, alpha=alpha, weight_attr=weight_attr)
res = grad_norm.nn_func(ins)
losses = []
for idx in range(n_loss):
losses.append(loss_func[idx](res))
losses = paddle.concat(losses)
weighted_loss = grad_norm.loss_weights * losses
loss = paddle.sum(weighted_loss)
loss.backward(retain_graph=True)
grad_norm_loss = grad_norm.get_grad_norm_loss(losses)
print(grad_norm.loss_weights.grad)
return grad_norm_loss
def randtool(dtype, low, high, shape):
"""
np random tools
"""
if dtype == "int":
return np.random.randint(low, high, shape)
elif dtype == "float":
return low + (high - low) * np.random.random(shape)
if __name__ == '__main__':
np.random.seed(22)
xy_data = randtool("float", 0, 10, (9, 2))
res = cal_gradnorm(paddle.to_tensor(xy_data, dtype='float32'), 2, 3, 2, 1, activation='tanh', n_loss=4, alpha=0.5)
print(res.item())
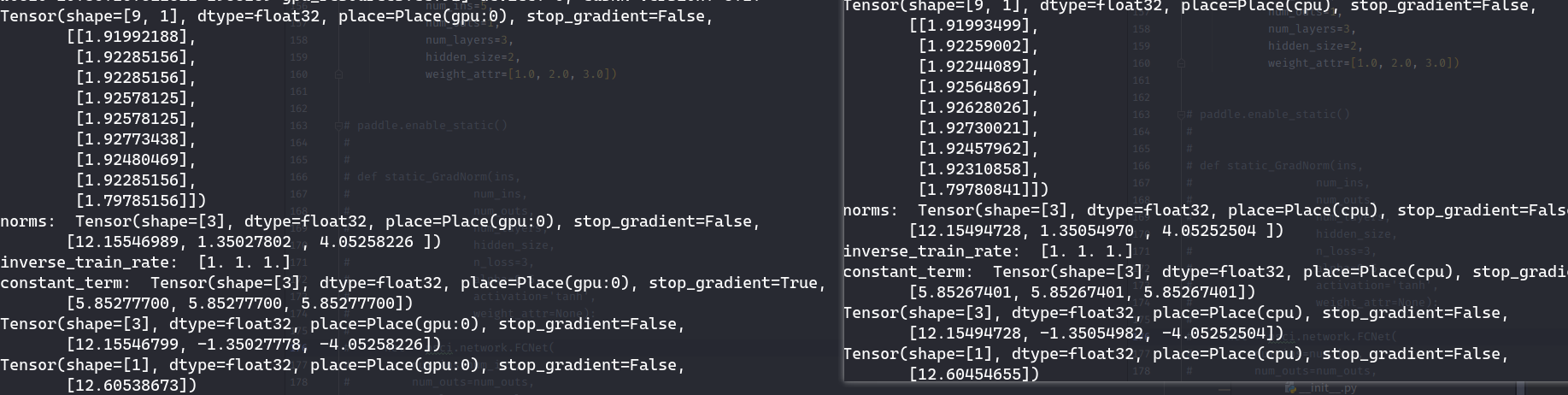
develop版本运行结果:
 2.3版本:
2.3版本:

@Asthestarsfalll 2.3版本是老动态图,develop分支是新动态图。 出现这个问题的原因是新动态 ones_like API的输出Tensor的 stop_gradient=True (默认),而老动态图输出 Tensor 的 stop_gradient=False。 下面修改可以解决问题:
for i in range(num_layers):
net._weights[i] = paddle.ones_like(net._weights[i])
net._weights[i].stop_gradient = False # 增加这一行