Multi-GPU operation seems to be problematic
I can confirm that 29500 is not being used.....
Traceback (most recent call last):
File "/data1/xxx/chat/LMFlow/service/app.py", line 35, in
Thanks for your interest in LMFlow! I guess the problem is caused by misspecification of master port and master addr. Could you please try set
export MASTER_ADDR=127.0.0.1
export MASTER_PORT=29500
and launch app.py again to see if the problem still exists? Thanks 😄
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=1 --master_port 29500 app.py
Currently, multi-gpu inference may encounter issues. I'll suggest using a single GPU. Thanks!
@shizhediao I know your reply above sort of already says, 'no' but just in case something's changed, do you think it is practically possible to do RAFT on {fine-tuned Falcon-7b} model with {GPT-NEO-7B or DistilBert Reward Model} (which I have already fine-tuned) using 4 GPUs - each 22 GB ?
Tried everything, but it all stops with an error (right after _clean_text and _discard_sample stage.)
Btw, in my latest run, the code just stops -without any error - such a silent heartbreak!
Is it ok when using only a single GPU? From the screen capture, I cannot see any errors. It may be related to deepspeed. Could you try other configs like removing zero strategy or zero2 instead of zero3.
Hi @shizhediao Thanks for your reply.
I began with single-GPU (~24GB); it stopped in here:
I then switched to AWS g5x.12 which has 4-GPU / ~24 GB each.
It then passed beyond the above point.
The thing is it loads the fine-tuned model only in GPU-0:
Tried loading the model manually to other GPU, manual allocation/feed in data to reward model to fine-tuned model using to.(cuda: 1/2/3).
But at the following specific code (in raft_trainer.py), the code automatically takes the model back to GPU-0:
Yesterday, I tried with both deepseed zero-2 and zero-3: yeah, it doesn't show any error, but simply exits the processs (Screenshot above).
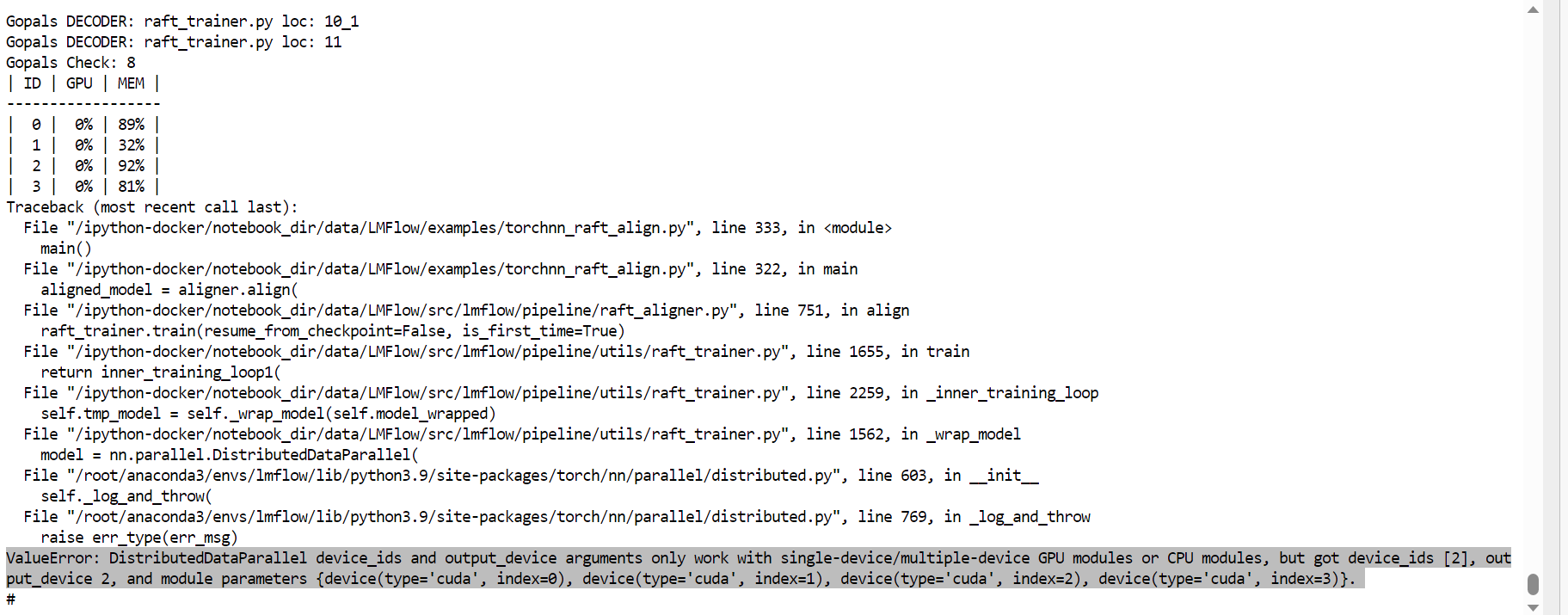
Btw, I also tried using torch.nn.distribution
This is the error I get:
Could you check the RAM usage? From the first picture, the killing might be caused by out of RAM
Hi @shizhediao , thanks for your reply.
Btw, I'm testing this on raft_batch_size = 8
For the following: I've first used ds_config_zero2.json
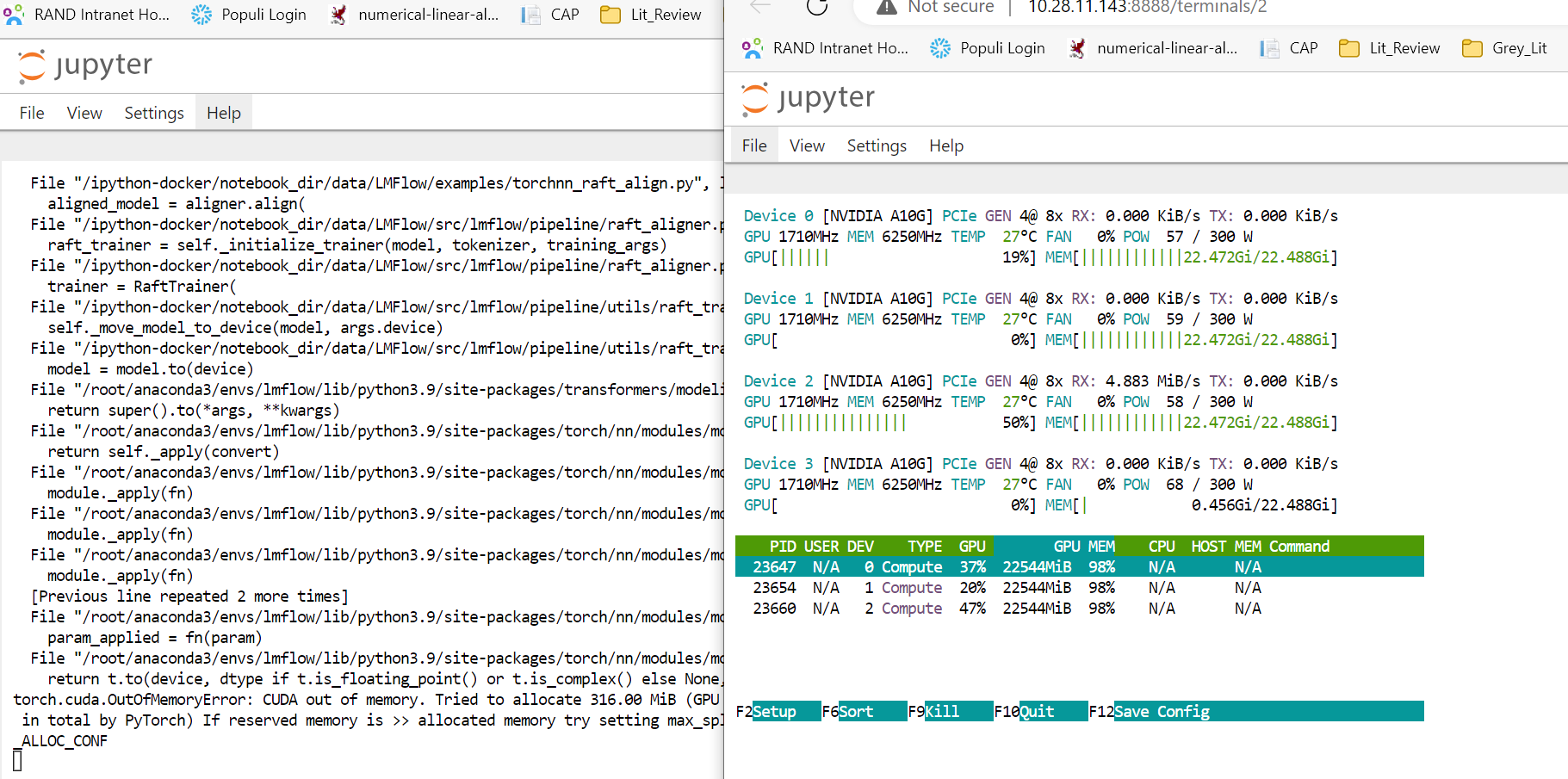
The process stops with CUDA out of memory error
This is the exact point where the error occurs (in raft_aligner.py) (sorry had to add in some consoling print statements for myself :D):
Following is the resource use just before the error occurs:
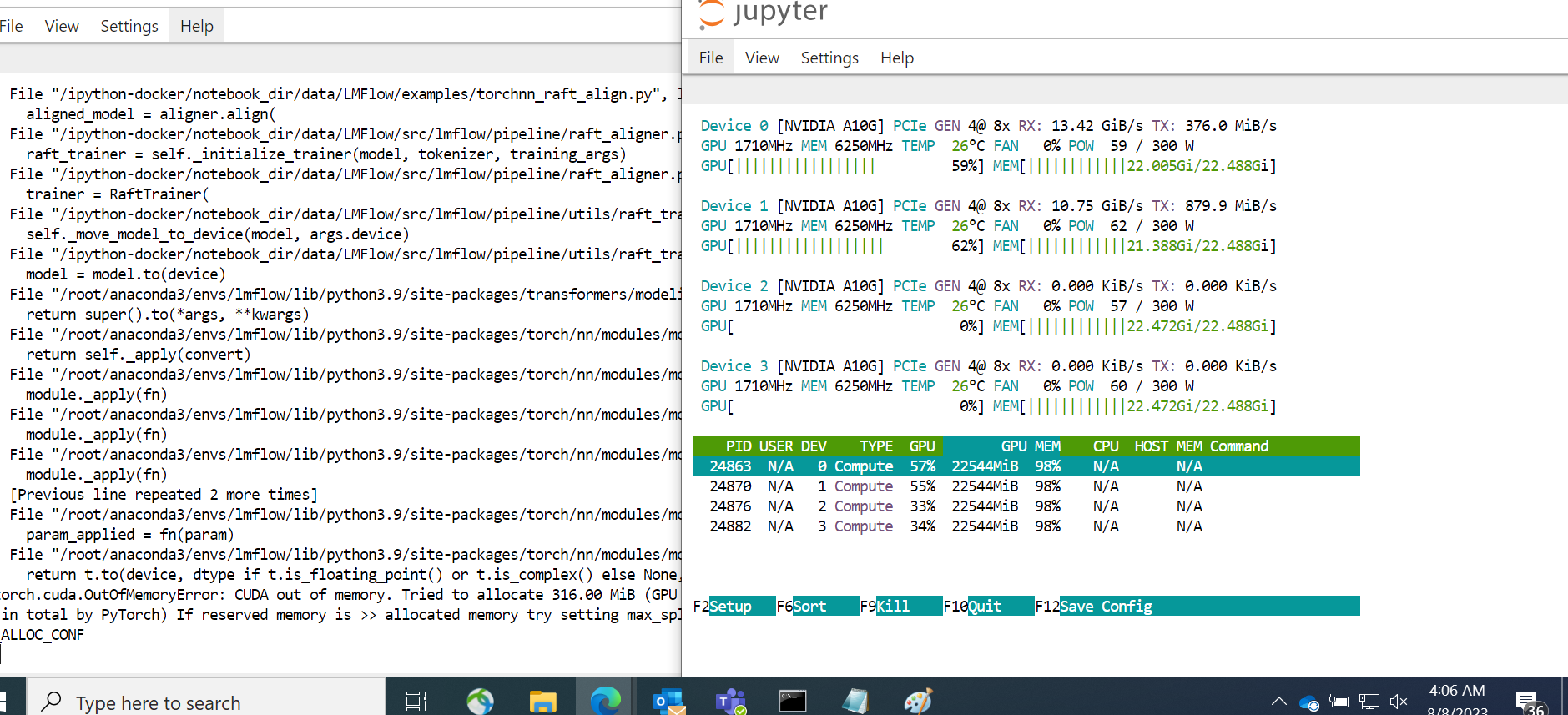
I also tried to run the code with ds_config_zero3.json
It stops with following:
Memory check before the error:
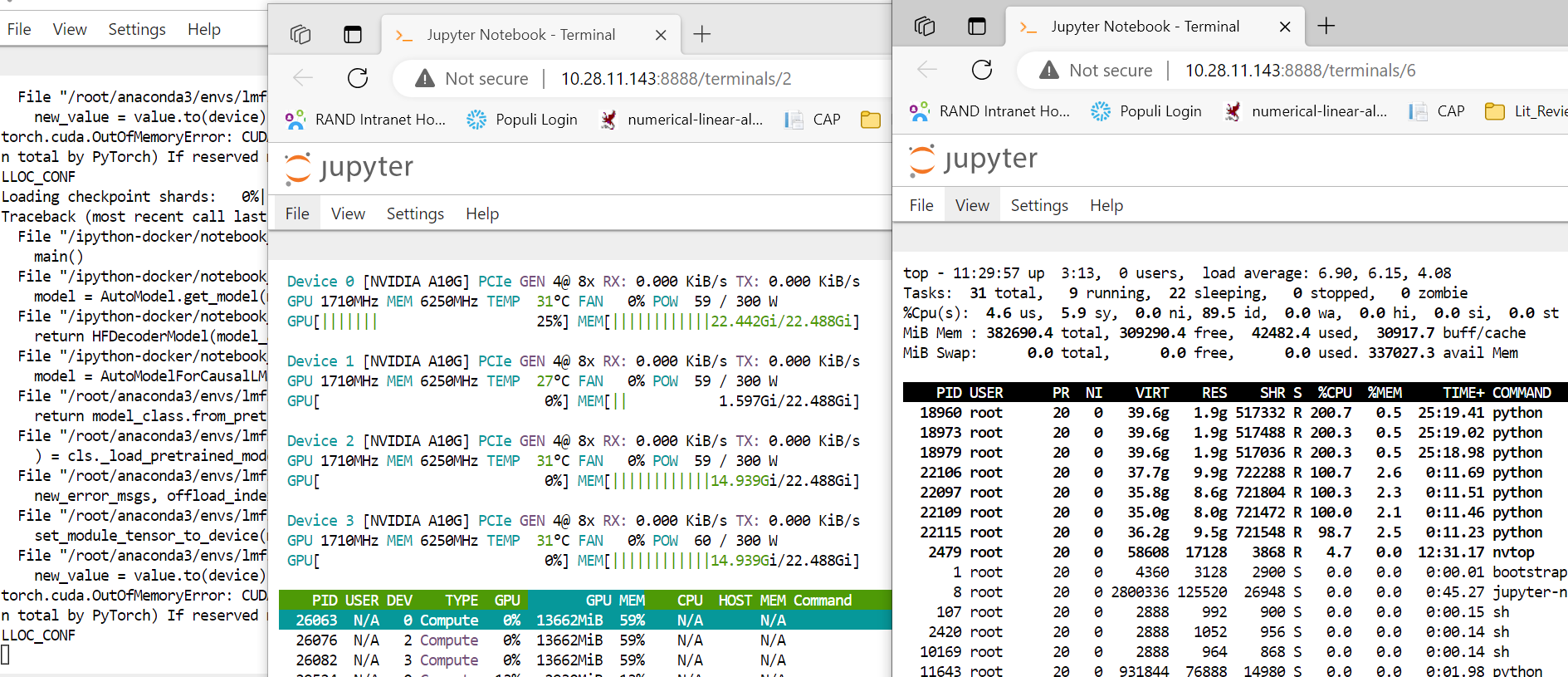
I did a quick re-run (With zero-3) to capture the instantaneous cpu/ram usage when the error occurs:
Here's the resourse use (closer to when we get the error: but hadn't got the error at this point [_the memory seems to be exhausted here]
Then the memory comes back again, before the error message comes in
**So two questions here:
- @shizhediao do you think this is the issue here?
- do you see any possibility I can still use 4 GPU (24gb each); 'm especilly concerned about the model loading to GPU0 and frying it up. Any idea how we can use all 4 GPU?**
Thank you so much!
_
@shizhediao Today, I tried running the program in an instance that has higher RAM. (But with same number/size of GPU).
I got pretty similar results.
I also tried running the program using accelerate launch (for which I stripped of the deepspeed line in run_raft.sh; created another test_runner.py file that would execute run_raft.sh and subsequently, raft_align.py).
I configured accelerate with both ds_config_zero2 and ds_config_zero3 as well as without deepspeed.
Also combined with load fine-tuned model with/without 8bit, with/with toech_dtype=torch.bloat16, and with/without device_map = "auto".
This is the result with ds_config_zero2 (without any additional model load settings) (i.e. no 8-bit, torchdtype, etc.) (accelerate lauch test_runner.py):
This is the result with ds_config_zero3
This is the result with ds_config_zero2 plus additional model load settings (i.e. load in 8bit=true)
All of the above stops with CUDA OOM error
Also, tried accelerate launch with ds_config_zero3 (plus, load model in 8bit; and device_map=auto)
This time around, it stops with following error:
Seems that CUDA OOM is the problem. Is it possible to use a GPU with larger memory? May be @WeiXiongUST could provide some practical suggestions.
@shizhediao Today, I tried running the program in an instance that has higher RAM. (But with same number/size of GPU).
I got pretty similar results.
I also tried running the program using accelerate launch (for which I stripped of the deepspeed line in run_raft.sh; created another test_runner.py file that would execute run_raft.sh and subsequently, raft_align.py).
I configured accelerate with both ds_config_zero2 and ds_config_zero3 as well as without deepspeed.
Also combined with load fine-tuned model with/without 8bit, with/with toech_dtype=torch.bloat16, and with/without device_map = "auto".
This is the result with ds_config_zero2 (without any additional model load settings) (i.e. no 8-bit, torchdtype, etc.) (accelerate lauch test_runner.py):
This is the result with ds_config_zero3
This is the result with ds_config_zero2 plus additional model load settings (i.e. load in 8bit=true)
All of the above stops with CUDA OOM error
Also, tried accelerate launch with ds_config_zero3 (plus, load model in 8bit; and device_map=auto) This time around, it stops with following error:
You may check this issue 545 and try out the separate implementation, which only loads one model at a time to reduce the requirement of memory resource. We shall update the implementation in lmflow soon.
This issue has been marked as stale because it has not had recent activity. If you think this still needs to be addressed please feel free to reopen this issue. Thanks