在cpt-bk分支编译的nemu跑linux kernel时出错
如图。我使用的命令是:
./cpt-bk/build/riscv64-nemu-interpreter $SPEC06_BBL -D $SPEC06_CPT_DIR -w mcf -C run_spec -b --simpoint-profile --interval 100000000

How about running linux with the master branch? cpt-bk branch is out of maintaining.
We will add SimPoint profiling and checkpointing functions to master branch soon.
How about running linux with the master branch? cpt-bk branch is out of maintaining.
We will add SimPoint profiling and checkpointing functions to master branch soon.
None of the errors occur in master branch (log f357d0c). We hope you tackle the problems soon.
It is scheduled and will be ported and tested in a few weeks.
If it is urgent for you, you can port simpoint related functions from cpt-bk to master yourself. And it would be appreciated if you port these funtions and send a patch to us.
Well, i try by changing the command as: ./cpt-bk/build/riscv64-nemu-interpreter -D $SPEC06_CPT/429_mcf_peak -w peak -C run_spec -b --simpoint-profile --interval 100000000 $SPEC06_BBL
But the same errors are reported again:
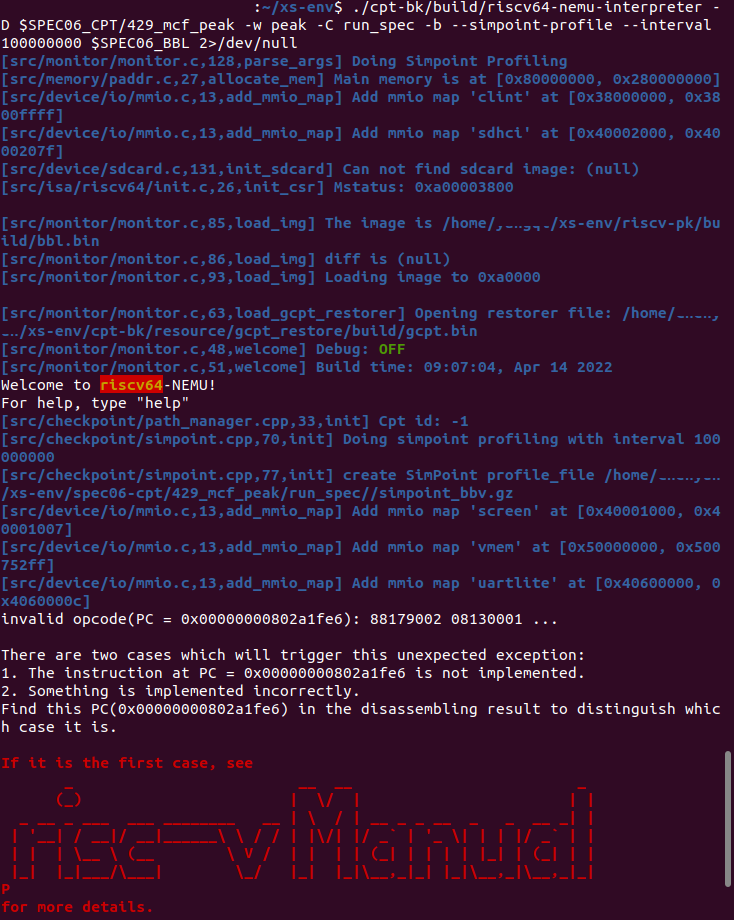
看起来应该是$SPEC06_BBL这个bbl文件不对,没有改workload的起始地址,没有在workload里使用NEMU自定义指令让NEMU进入checkpoint模式。 我们使用普通的emulation workload,用cpt-bk分支的NEMU做profiling能复现同样的问题,workload做下面说的处理之后就正常了。
“workload 的生成 因为checkpoint的原理,我们不支持在 M 态下生成checkpoint(Issue #54), 因此 workload 需要运行在 S 态或 U 态下运行,比如 Linux 上运行 SPEC2006。构建的方法可以参考 Linux Kernel for XiangShan in EMU 。
NEMU 生成 checkpoint 时,需要添加一段恢复程序 gcpt.bin,在 (0x80000000, 0xa0000)。因此在生成 workload 时,需要避开这一段空间,将起始地址设置在 0x800a0000 。如在 riscv-pk/bbl/bbl.lds 中,修改为 . = MEM_START + 0xa0000 。
NEMU 默认不会进入 checkpoint 模式,需要使用 NEMU 自定义指令进行模式转换。
RTFSC: nemu_trap
具体如下:”
看起来应该是$SPEC06_BBL这个bbl文件不对,没有改workload的起始地址,没有在workload里使用NEMU自定义指令让NEMU进入checkpoint模式。 我们使用普通的emulation workload,用cpt-bk分支的NEMU做profiling能复现同样的问题,workload做下面说的处理之后就正常了。
“workload 的生成 因为checkpoint的原理,我们不支持在 M 态下生成checkpoint(Issue #54), 因此 workload 需要运行在 S 态或 U 态下运行,比如 Linux 上运行 SPEC2006。构建的方法可以参考 Linux Kernel for XiangShan in EMU 。
NEMU 生成 checkpoint 时,需要添加一段恢复程序 gcpt.bin,在 (0x80000000, 0xa0000)。因此在生成 workload 时,需要避开这一段空间,将起始地址设置在 0x800a0000 。如在 riscv-pk/bbl/bbl.lds 中,修改为 . = MEM_START + 0xa0000 。
NEMU 默认不会进入 checkpoint 模式,需要使用 NEMU 自定义指令进行模式转换。
RTFSC: nemu_trap
具体如下:”
可以尝试一下tracing 分支,tracing分支的速度应该会快很多。tracing和cpt-bk分支的命令行参数有很小的区别:https://xiangshan-doc.readthedocs.io/zh_CN/latest/tools/simpoint/
@shinezyy 先用的tracing分支,但是做profiling一直出错,见下面的图,就换成了cpt-bk分支。 后来发现加-r参数指定gcpt.bin可以解决tracing分支的这个报错。

@shinezyy 先用的tracing分支,但是做profiling一直出错,见下面的图,就换成了cpt-bk分支。 后来发现加-r参数指定gcpt.bin可以解决tracing分支的这个报错。
-r之后需要加-I参数吗,不加的话会有下面这样的报错,加的话只有20m以下可以生成bbv.gz,是nemu版本的问题吗

没有加-l参数,完整的命令如下:
./build/riscv64-nemu-interpreter ~/xs-linux/riscv-pk/build/bbl.bin
-D /home/hmt/spec_cpt -w spec_$WORKLOAD -C profiling
-b --simpoint-profile --cpt-interval $INTERVAL -r ./resource/gcpt_restore/build/gcpt.bin
看打印,是NEMU申请内存失败?内存不足?
没有加-l参数,完整的命令如下: ./build/riscv64-nemu-interpreter ~/xs-linux/riscv-pk/build/bbl.bin -D /home/hmt/spec_cpt -w spec_$WORKLOAD -C profiling -b --simpoint-profile --cpt-interval $INTERVAL -r ./resource/gcpt_restore/build/gcpt.bin 看打印,是NEMU申请内存失败?内存不足?
是的,看打印是这样的,但增大内存又会引入memory不对齐的问题,方便留个联系方式交流下吗?谢谢
“增大内存”,具体怎么做的? "引入memory不对齐的问题",这个有log吗?没有遇到过。 如果是讨论这个问题的话,这里就比较好吧,有记录,将来可以给别人做参考。
没有加-l参数,完整的命令如下: ./build/riscv64-nemu-interpreter ~/xs-linux/riscv-pk/build/bbl.bin -D /home/hmt/spec_cpt -w spec_$WORKLOAD -C profiling -b --simpoint-profile --cpt-interval $INTERVAL -r ./resource/gcpt_restore/build/gcpt.bin 看打印,是NEMU申请内存失败?内存不足?
是的,看打印是这样的,但增大内存又会引入memory不对齐的问题,方便留个联系方式交流下吗?谢谢
“增大内存”,具体怎么做的? "引入memory不对齐的问题",这个有log吗?没有遇到过。 如果是讨论这个问题的话,这里就比较好吧,有记录,将来可以给别人做参考。
好的,抱歉内存的问题我解决了。 我也是tracing发现报错后用NEMU master分支下readme中的uniform checkpoint可以运行才发现要加入-r参数,不过这样的话最后做checkpoint也需要加-r参数吗,不加的话会有“riscv64-nemu-interpreter: src/monitor/monitor.c:298: init_monitor: Assertion `restorer != NULL' failed.”的报错;加上后也没有生成.gz而是NEMU又做了一次simpoint profiling然后退出了 还有一个比较好奇的是用ready-to-run的linux-0xa0000.bin做simpoint profiling不会生成bbv.gz吧,因为没有NEMU_trap状态的转换,所以NEMU只是输出helloworld后进入hanging了,并没有进入simpoint profiling状态
没有加-l参数,完整的命令如下: ./build/riscv64-nemu-interpreter ~/xs-linux/riscv-pk/build/bbl.bin -D /home/hmt/spec_cpt -w spec_$WORKLOAD -C profiling -b --simpoint-profile --cpt-interval $INTERVAL -r ./resource/gcpt_restore/build/gcpt.bin 看打印,是NEMU申请内存失败?内存不足?
是的,看打印是这样的,但增大内存又会引入memory不对齐的问题,方便留个联系方式交流下吗?谢谢
“增大内存”,具体怎么做的? "引入memory不对齐的问题",这个有log吗?没有遇到过。 如果是讨论这个问题的话,这里就比较好吧,有记录,将来可以给别人做参考。
好的,抱歉内存的问题我解决了。 我也是tracing发现报错后用NEMU master分支下readme中的uniform checkpoint可以运行才发现要加入-r参数,不过这样的话最后做checkpoint也需要加-r参数吗,不加的话会有“riscv64-nemu-interpreter: src/monitor/monitor.c:298: init_monitor: Assertion `restorer != NULL' failed.”的报错;加上后也没有生成.gz而是NEMU又做了一次simpoint profiling然后退出了 还有一个比较好奇的是用ready-to-run的linux-0xa0000.bin做simpoint profiling不会生成bbv.gz吧,因为没有NEMU_trap状态的转换,所以NEMU只是输出helloworld后进入hanging了,并没有进入simpoint profiling状态
是的,-r要加的。 尝试了一下ready-to-run下的linux-0xa0000.bin做simpoint profiling,确实是没有生成可用的simpoint_bbv.gz,最后打印hanging就停住了。因为不清楚linux-0xa0000.bin是怎么生成的,猜测是运行hello world前没有做nemu_trap 指令(0x6b)的处理,所以不进profiling mode,运行结束后也没有通过GOOD_TRAP正常结束NEMU运行。 “加上后也没有生成.gz而是NEMU又做了一次simpoint profiling然后退出了”,这个是指处理你自己的workload时遇到的情况?workload前加了nemu_trap 指令(0x6b)的处理?
没有加-l参数,完整的命令如下: ./build/riscv64-nemu-interpreter ~/xs-linux/riscv-pk/build/bbl.bin -D /home/hmt/spec_cpt -w spec_$WORKLOAD -C profiling -b --simpoint-profile --cpt-interval $INTERVAL -r ./resource/gcpt_restore/build/gcpt.bin 看打印,是NEMU申请内存失败?内存不足?
是的,看打印是这样的,但增大内存又会引入memory不对齐的问题,方便留个联系方式交流下吗?谢谢
“增大内存”,具体怎么做的? "引入memory不对齐的问题",这个有log吗?没有遇到过。 如果是讨论这个问题的话,这里就比较好吧,有记录,将来可以给别人做参考。
好的,抱歉内存的问题我解决了。 我也是tracing发现报错后用NEMU master分支下readme中的uniform checkpoint可以运行才发现要加入-r参数,不过这样的话最后做checkpoint也需要加-r参数吗,不加的话会有“riscv64-nemu-interpreter: src/monitor/monitor.c:298: init_monitor: Assertion `restorer != NULL' failed.”的报错;加上后也没有生成.gz而是NEMU又做了一次simpoint profiling然后退出了 还有一个比较好奇的是用ready-to-run的linux-0xa0000.bin做simpoint profiling不会生成bbv.gz吧,因为没有NEMU_trap状态的转换,所以NEMU只是输出helloworld后进入hanging了,并没有进入simpoint profiling状态
是的,-r要加的。 尝试了一下ready-to-run下的linux-0xa0000.bin做simpoint profiling,确实是没有生成可用的simpoint_bbv.gz,最后打印hanging就停住了。因为不清楚linux-0xa0000.bin是怎么生成的,猜测是运行hello world前没有做nemu_trap 指令(0x6b)的处理,所以不进profiling mode,运行结束后也没有通过GOOD_TRAP正常结束NEMU运行。 “加上后也没有生成.gz而是NEMU又做了一次simpoint profiling然后退出了”,这个是指处理你自己的workload时遇到的情况?workload前加了nemu_trap 指令(0x6b)的处理?
是的,在workload前加了NEMU_TRAP处理,结束后也有GOOD_TRAP退出NEMU,加上--dont-skip-boot参数可以正常生成cpt.gz,没有的话输出的log和profiling的输出是一样的,还有就是这个cpt-interval的参数要如何选择才能只有workload生成相应的cpt.gz?
怀疑你的NEMU_TRAP处理不大对。
看了一下NEMU的code,--dont-skip-boot应该能够代替NEMU_TRAP,所以你加了--dont-skip-boot就可以了。

下面这段是riscv-rootfs/rootfsimg/run.sh内容: cat ~/xs-linux/riscv-rootfs/rootfsimg/run.sh #!/bin/sh echo "===== Start running SPEC2006 =====" echo "======== BEGIN sjeng ========" set -x md5sum /spec/sjeng_base.riscv date -R /spec_common/before_workload cd /spec && ./sjeng_base.riscv ref.txt date -R set +x echo "======== END sjeng ========" echo "===== Finish running SPEC2006 =====" /spec_common/after_workload
里面的before_workload/after_workload分别是让NEMU进入profiling模式的处理和正常退出程序执行的处理。 对应的code参考Xiangshan文档 https://xiangshan-doc.readthedocs.io/zh_CN/latest/tools/simpoint/ 中间的代码,2个程序区别的地方是让NEMU进入profiling用: nemu_signal(DISABLE_TIME_INTR); nemu_signal(NOTIFY_PROFILER); 让NEMU正常退出程序执行用: nemu_signal(GOOD_TRAP);