cblas_sgemv switches algorithm way too early
While benchmarking cblas_sgemv against other implementations, I found it apparently switches between algorithms at around a size of 96.
That results in a massive drop in performance from being almost 10 times faster than a naive implementation to being half as slow. It only becomes competitive again for very large element counts (thousandths)
This is with precompiled dll from OpenBLAS-0.3.10-x64.zip, running in Windows 10
Chart below is from a run on a Ryzen 5 2400G, but I got a similar results on a core i5-8265U
https://imgur.com/a/PvjGrB3
Probably not algorithm as such, but switching from single-threaded to all threads it can get, which indeed would currently happen at 96x96 (interface/gemv.c). This should already be somewhat better than the original GotoBLAS behaviour of throwing all cores at any problem no matter its size, but the more cores you have the worse it will look at intermediate problem sizes. EDIT: The metric got changed in https://github.com/xianyi/OpenBLAS/pull/759 a few years ago, maybe this (or some later change) introduced an unwanted side effect.
BTW unfortunately the image does not load for me, did you use the simple gemv test from the benchmark directory or your own code ?
I used an own benchmark.
You are right, it is attempting to use all CPU cores (even hyper-threaded ones), but AFAICT the threads mostly end up starved of memory access judging by the task manager CPU (not very scientific), just one or two threads have significant CPU usage.
When setting the OPENBLAS_NUM_THREADS environnement variable to 1, the drop disappears.
With 2 threads the performance drop is recovered around 500 elements, but that's barely before hitting memory starvation at around 1000 elements, and it never unambiguously went above the performance achieved with just one thread.
So using just one thread seems to always works best on my low end CPUs... I guess I need better RAM ;)
BLAS Level2 is always memory access bound. What is done pessimal for multicore scenario is having write areas other than properly aligned pages for each core.
FWIW I have been able to test on a Xeon E3-1240v6 server with fast RAM, and this is the first CPU where multi-thread was beneficial, though only achieving twice the performance of a single thread. However the massive drop at size 96 is still there, and only recovered for sizes 800 to about 2000 (after that memory bandwidth limit kicks in, and multi-thread does no better)
Sounds unbelievable. Normally performance bias setting controls how restricted is one thread, at zero there is no gain spinning up second.
Could you check with lstopo that you really restrict to hyperthreads and not to cores? It happens thay get numbered 12121212 or sometiems 11112222.
To test between single and multi threading, I only adjusted OPENBLAS_NUM_THREADS, I have not adjusted affinity.
Below is the chart of execution time ratio between single thread (OPENBLAS_NUM_THREADS set at 1) and dual (OPENBLAS_NUM_THREADS set at 2) or multi (OPENBLAS_NUM_THREADS left empty) on that E3-1240v6, bare metal Windows, sgemv with a square matrix, beta of zero. Other CPUs I tested earlier on reach their memory limit before multi-thread gets a chance to shine.
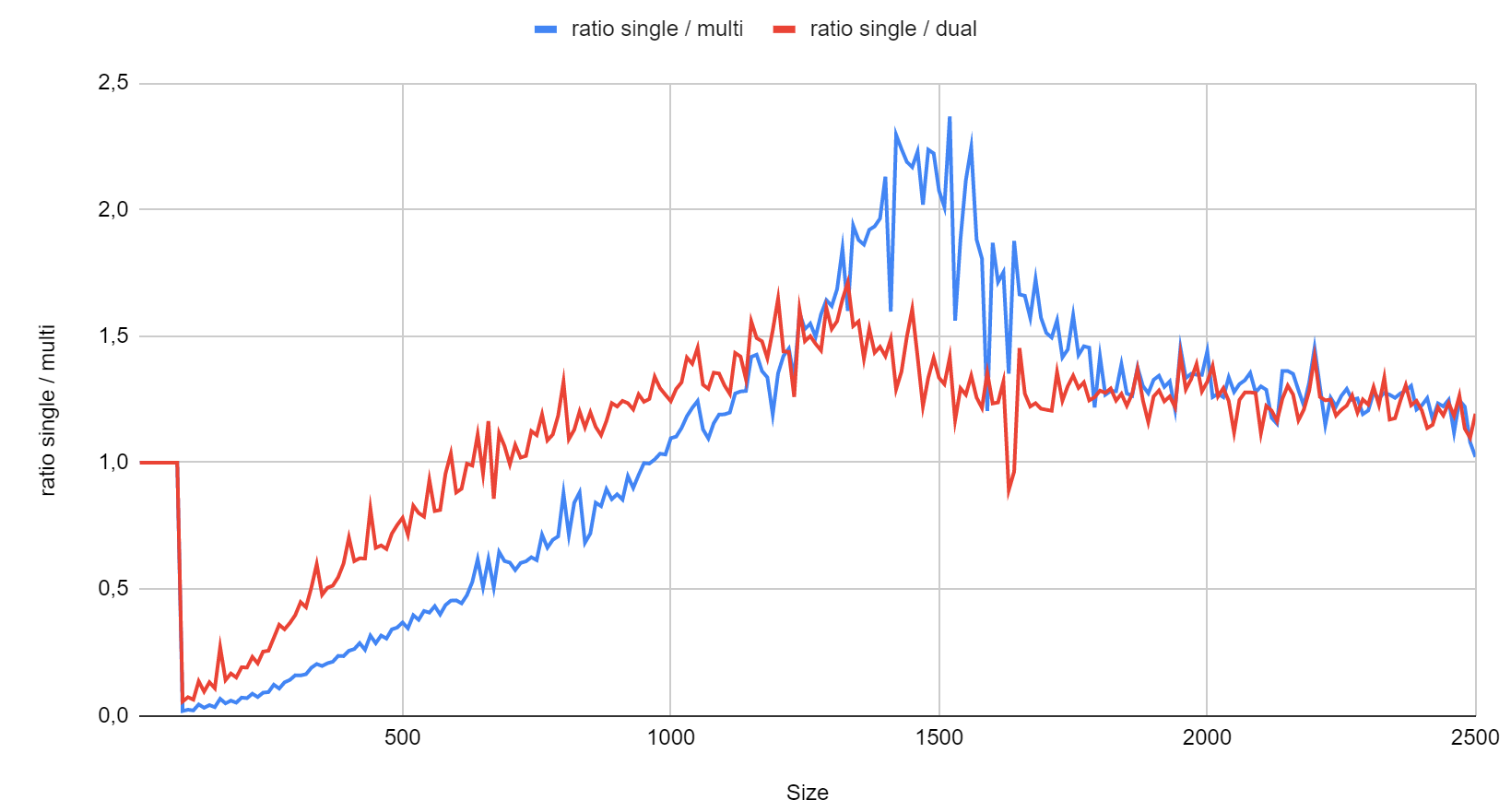
Then it falls into cores. You mean m=n=1000 ? its like 4 megs in 4 megs out.... What it looks like - you finally start to spill out of L3 cache and access main memory, in perfect world L3 size could be used to tame crowd of threads, but it is not done now. btw how does gemm perform in same situation?
Yes, m=n=1000, that's 4 MB + 4 kB in (matrix + vector) and 4 kB out With gemm, you mean matrix-matrix ? I guess size 1000 will be completely memory-bound.
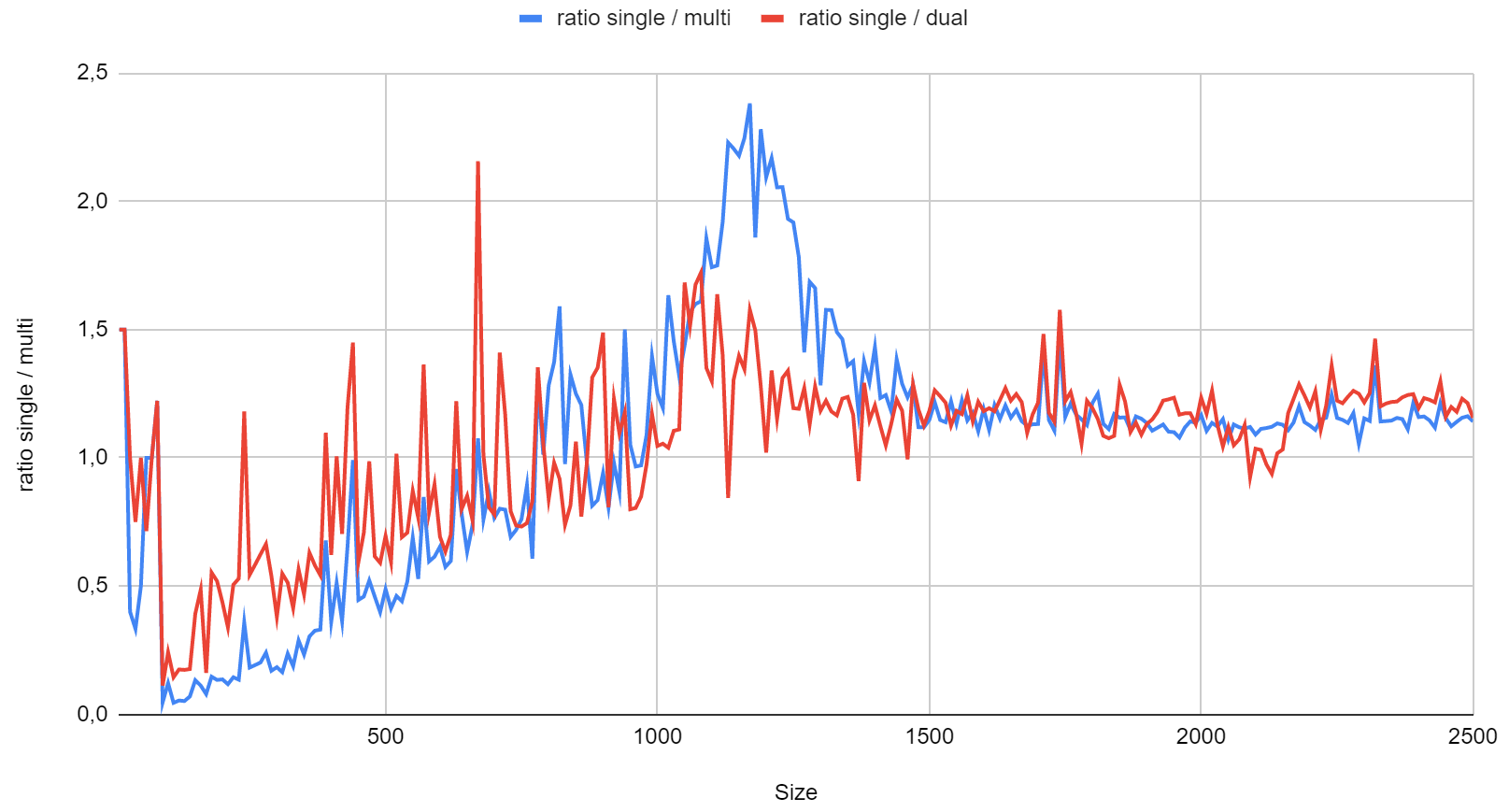
In practice I will not have access to that E3 CPU, but will be using a lower-end CPUs and RAM, with smaller caches, and for which the chart typically looks like below (here an AMD Ryzen 5). The sweet spot of multi-threading is much narrower, but on the other hand the Ryzen 5 multi-threading can maintain a tiny lead over single-threading fort the larger sizes.
I mean GEMM with M or N being one does same GEMV. 4 megs is really around scale around L3 cache. Do something that sizes at least 10 times biggest advertised cache on CPU, then go down - there is sweet spot when input and output fits nicely in cache and it seems very fast.
The code in question is here https://github.com/xianyi/OpenBLAS/blob/c4a3bd9f4660c3df68fbf07a6322bd97a883a5ca/interface/gemm.c#L503-L506 (the level=3 does not seem to have any effect?). Would it be possible to expose any of this for run-time tweaking? I wonder if a more sophisticated algorithm for choosing args.nthreads would be more beneficial.
I find it surprising that once the input is memory bound additional threads are not helpful: I would think partitioning the problem would continue to help.
Close but you want to look at https://github.com/xianyi/OpenBLAS/blob/c4a3bd9f4660c3df68fbf07a6322bd97a883a5ca/interface/gemv.c#L229-L232 as we are in GEMV not GEMM GEMM_MULTITHREAD_THRESHOLD is at least exposed as a build-time option, ISTR Julialang set it to 50 instead of the default 4 in their builds. And the argument to num_cpu_avail is only a leftover debug option meant to track which part of the code queried the number of cores. This is original GotoBLAS code that I have lacked the time, courage and data to change as it seemed to work "reasonably" well - part of the problem may simply be that the range of hardware, and number of cores in a given system, has changed massively in recent years. (More so since K.Goto came up with it, and his code gained some of its speed from not being thread-safe at all)
the range of hardware, and number of cores in a given system, has changed massively in recent years
Makes sense.
GEMM_MULTITHREAD_THRESHOLDis at least exposed as a build-time option, ISTR Julialang set it to 50 instead of the default 4 in their builds
We could do that in openblas-libs, thanks
Unfortunately a quick test on a 6-core Ryzen3 suggests that increasing GEMM_MULTITHREAD_THRESHOLD globally would kill at least DGEMM performance, while the calculated switching point for (S)GEMV appears to be off by at least a factor of 256 (roughly in agreement with the earlier observation that the transition to multithreading should happen around size 1000 rather than 100). Still need to see if this is true for other architectures as well, and if it could be a symptom of some other breakage rather than a genuine mistake in only this interface function.
@martin-frbg Would it make sense add separate *_MULTITHREAD_THRESHOLD for each of the interfaces currently using GEMM_MULTITHREAD_THRESHOLD? grep shows it's only used in the interfaces for zswap, zgemv, zger, gemv, swap, zrtmv, ger, gemm, and trsm and one driver driver/level2/gemv_thread.c. It may be nice to allow for some fine-grained tuning anyway, especially if gemv/gemm currently don't agree on the optimal setting. (assuming the difference is not from a mistake/breakage.)
I guess for backwards compatibility, they would all have to default to using the current value of GEMM_MULTITHREAD_THRESHOLD, but then people could override them individually if desired. (I can make a PR for this if it's reasonable?)
FWIW, on my M1, I also notice a large slow down for dger that is similar to dgemv: around size 100, multicore slows things down a lot. Then, at size 1000, multicore becomes ~1.1x faster than single core.
Too early to say - and as the threshold calculations use somewhat arbitrary scale factors already, it might be sufficient to adjust those
btw multicore threshold for ger was last changed in 2016, tested on a xeon e5-2xxx of the time. also this probably predates all the thread-safety fixes that unavoidably affected multicore performance through added locking
@martin-frbg I believe this issue can be closed after gh-4441 (auto-closing didn't quite work in this case).
Right - would probably have needed to repeat the "fixes" keyword for that to work