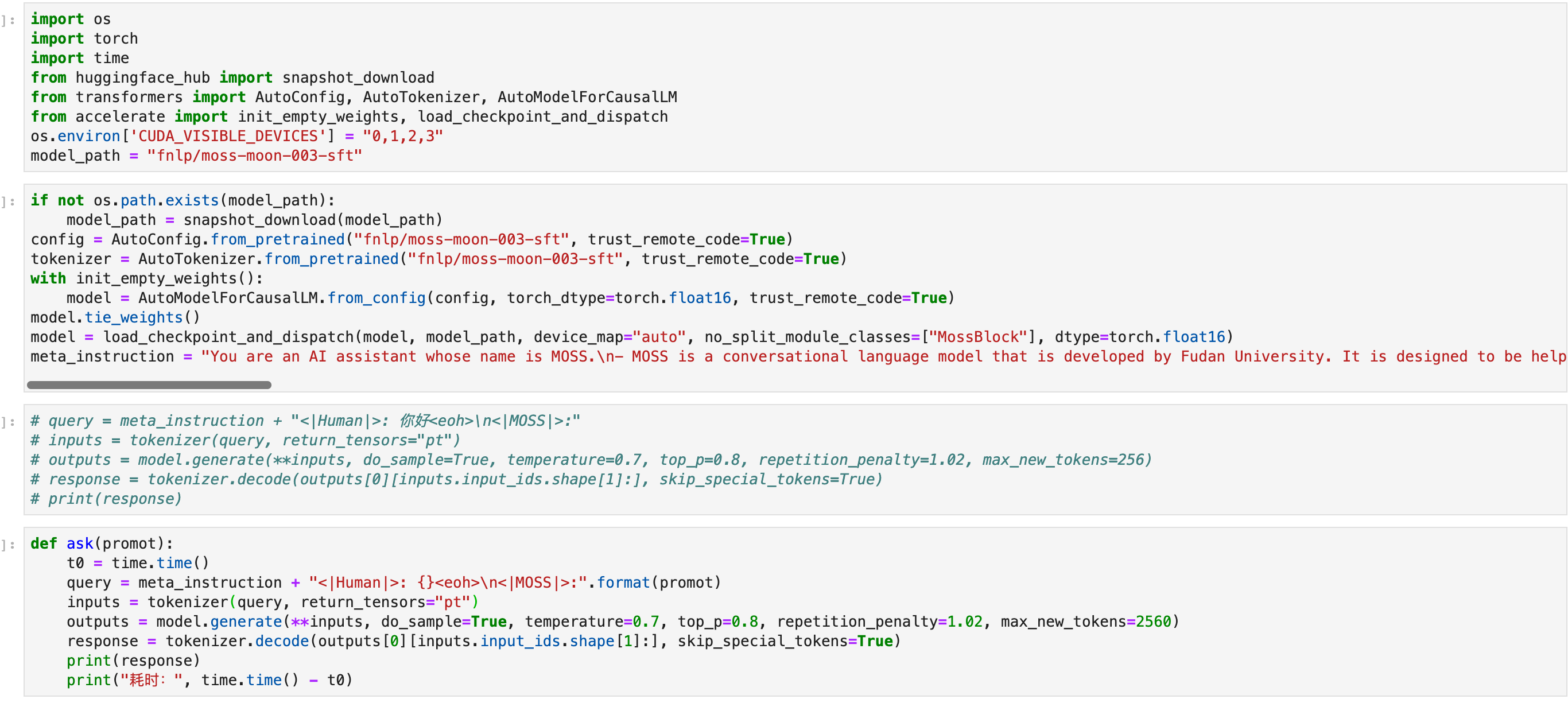
MOSS

MOSS copied to clipboard
推理结果的长度不足怎么调整,或者怎么让它继续推理
按照readme里的多卡部署,用jupyter测试的,我这边想用来做一些生成单元测试和代码审查。但是给出的回答tokens很短。说到一半就截止了。不知道该怎么调整,这边用了4张Tesla V100
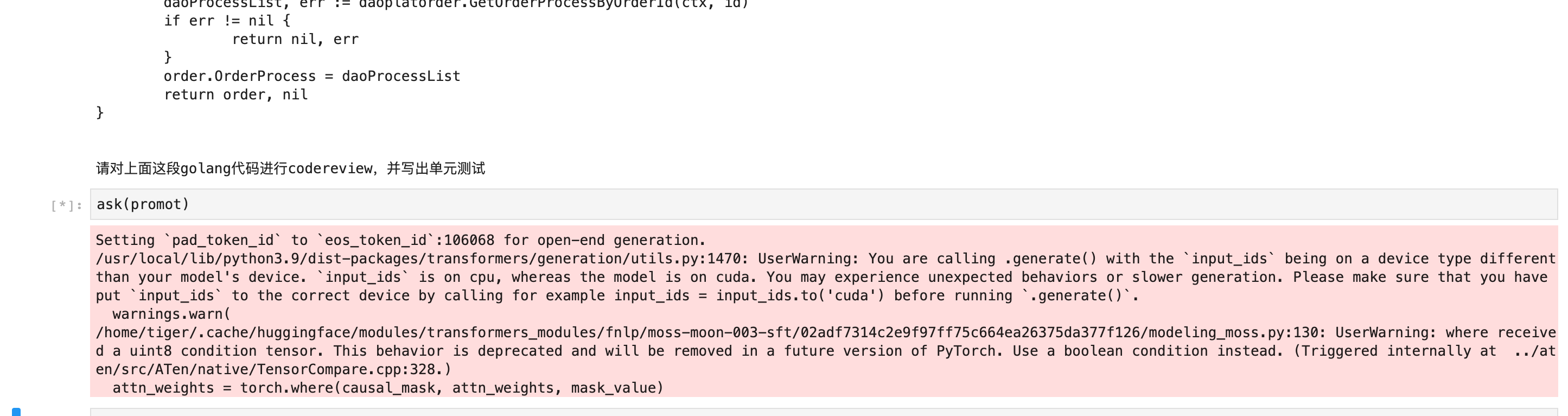 现在是这样,不认真回答了
现在是这样,不认真回答了
设置 skip_special_tokens=False ,打印response看最后是不是 eom,如果是(我觉得大概率是),那说明模型就只给你这点输出。