add t5 model
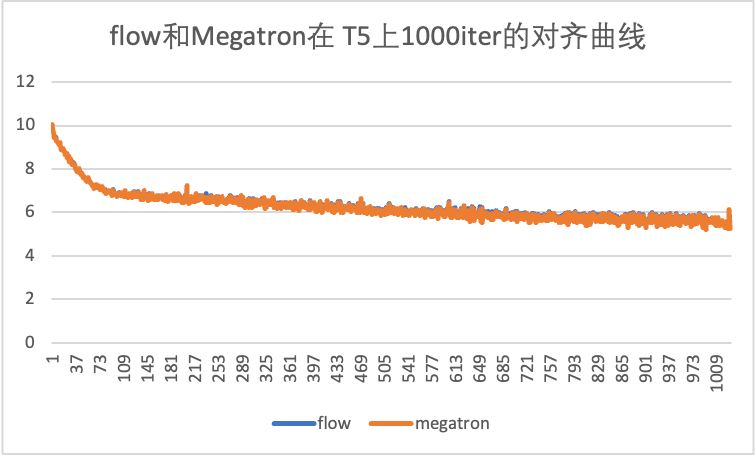
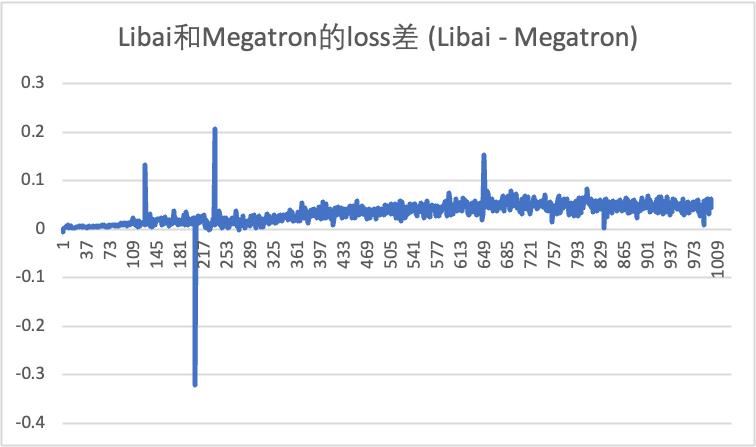
有一个部分需要修改:
T5ExtendedAttnMask 是按照libai bert复现的,但是在和Megatron对齐的过程中,发现Megatron只是简单地做了 .unsqueeze(1),和 T5ExtendedAttnMask 的实现不同,因此没有用上。所以这部分需要删除还是修改成等价于 .unsqueeze(1) 的操作放到模型里面?
T5ExtendedAttnMask 是按照libai bert复现的,但是在和Megatron对齐的过程中,发现Megatron只是简单地做了 .unsqueeze(1),和 T5ExtendedAttnMask 的实现不同,因此没有用上。所以这部分需要删除还是修改成等价于 .unsqueeze(1) 的操作放到模型里面?
这个因为megatron构造t5数据时,encoder_padding_mask等是[bsz, seqlen, seqlen]的维度,在bert里是[bsz, seqlen]的维度,因此它的处理和bert不同。我在https://github.com/Oneflow-Inc/libai/blob/add_models/libai/layers/mask_helpers.py 里把所有的attention mask操作都写成了模块,可以用这个替换掉bert和t5中的ExtendedAttnMask
现在写的模型只能训练,推理都没有实现。T5model拆分为T5Embedding、T5Encoder、T5Decoder三个模块。T5Embedding作为公共模块传参到T5Encoder、T5Decoder中,实现参数共享。T5model的forward过程包括两部分,encoder.forward()和decoder.forward()。T5Encoder实现编码器的所有层以及编码器的调用过程,T5Decoder实现解码器的所有层和解码器的调用过程,编码过程没有特殊之处,仿照bert直接传参输出即可,解码过程要考虑增量解码,所以要仿照其他库实现。必须将整个模型拆分开,这样才能在推理阶段,调用model.encoder(xxx)得到编码状态,然后循环调用model.decoder(xxx)逐一解码。
大家可以思考一下,现在验证了什么?目前验证了libai的layers使用到模块是正确的,按照目前的方式组装成t5模型和megatron一样,这种组装方式也是正确的。这仅证明训练的正确性,推理的正确性目前无法证明。那么,同样使用这些模块,改变它的组装方式(模型层以及它们的相对顺序不变),是不是也是正确的。以及,在此基础上,加上一些推理相关的,是不是也是正确的。
我不是想说之前我实现的都对,这个工作没有意义。我之前实现的那个pr,最近就发现了不满意的地方,可能也会存在错误,如果延续那个pr,我仍然会改正那些错误。我想表达的是,megatron的实现不友好,所以我们要实现一个更简单易用的库,同时拓展一下oneflow的生态。它的不友好不仅是mpu模块、dataset、trainer,也包括模型,所以我们不能完全对标它的实现。
现在的问题是,megatron实现的模型,将bert、gpt、t5统一为language_model模块,通过add_encoder和add_decoder参数控制。而我们抽象到transformer_layer层,具体的模型由算法工程师开发决定。这里导致参数名称可能不统一,如果想对齐megatron,只能要求模型开发时,也按照它的组装顺序实现。这导致了另一个问题,megatron的推理阶段是通过attention里inference_params这些参数控制的,来减少重复计算。我们之前实现attention时参考huggingface实现,通过past_key_value和use_cache参数控制。如果按照megatron实现,推理无法完成;如果按照huggingface实现,对齐精度时会增加加载模型的工作量。你们可以思考一下之后按照哪种方式实现
我觉得这些工作的目的只是为了有一个标准来衡量一个模型的正确性,不管是用 huggingface 还是 megatron 都是可以的,我们可以选择更简单的那个方式来。
像 NLP pretraining 这种 task 哪怕在小规模数据集上验证也比较麻烦,所以我们找一个标准去对齐 loss,这样发现问题可以及早暴露,而不是一直在写代码,最后发现精度跑不出来,然后无法定位是哪里写错了。
后续 bert 会专门保留一个分支用作 loss 对齐,每次 layers 里面的东西和 bert 模型本身有了优化和修改,都需要在那个分支下做一次 1000 轮训练已验证改动没有精度问题,这个流程已经非常简单且半自动化。
T5ExtendedAttnMask 是按照libai bert复现的,但是在和Megatron对齐的过程中,发现Megatron只是简单地做了 .unsqueeze(1),和 T5ExtendedAttnMask 的实现不同,因此没有用上。所以这部分需要删除还是修改成等价于 .unsqueeze(1) 的操作放到模型里面?
这个因为megatron构造t5数据时,encoder_padding_mask等是[bsz, seqlen, seqlen]的维度,在bert里是[bsz, seqlen]的维度,因此它的处理和bert不同。我在https://github.com/Oneflow-Inc/libai/blob/add_models/libai/layers/mask_helpers.py 里把所有的attention mask操作都写成了模块,可以用这个替换掉bert和t5中的ExtendedAttnMask
这个改完了