libai
 libai copied to clipboard
libai copied to clipboard
libai 设计文档
LiBai
config 设计文档 详情 trainer 设计文档 详情 lr scheduler 设计文档 详情 dataloader 设计文档 详情
Megatron https://github.com/NVIDIA/Megatron-LM
megatron 的整体结构如下
megatron
data (和数据处理相关的代码)
bert_dataset.py (bert 数据读取代码)
gpt_dataset.py (gpt 数据读取代码)
helper.cpp (建立 index 的工具代码)
dataset_utils.py (一些数据创建工具,比如生成 mask,padding 等等)
data_samplers.py (数据采样的代码)
...
fused_kernels (一些算子融合加速的代码)
layer_norm_cuda_kernel.cu (layernorm cuda 加速代码)
scaled_masked_softmax_cuda.cu (masked + softmax 加速代码)
...
model (所有的模型结构以及一些层的定义)
bert_model.py (bert 模型)
gpt_model.py (gpt 模型)
transformer.py (transformer 的所有层)
language_model.py (语言模型相关的层,比如 embedding 和 pooler)
fused_bias_gelu.py (一些零碎的层的合并)
...
mpu (model parallel utility,模型并行工具包)
layers.py (需要模型并行的 layer,比如 vocabEmbedding,ColumnLinear 等等)
cross_entropy.py (分布式的交叉熵计算)
...
optimizer (优化器相关的部分)
clip_grads.py (梯度裁剪)
optimizer.py (定义使用的优化器)
...
tokenizer (分词相关的代码)
tokenizer.py (分词的 interface)
bert_tokenization.py (bert 任务的分词代码)
gpt2_tokenization.py (gpt 任务的分词代码)
arguments.py (模型训练传入的参数)
checkpointing.py (模型保存相关的工具函数)
global_vars.py (全局参数)
learning_rates.py (学习率调整的策略)
training.py (模型训练的所有工具代码)
tasks (不同任务相关的代码)
glue (glue 任务相关的评测代码)
vision (视觉分类的评测代码)
finetune_utils.py (微调工具)
pretrain_bert.py (bert 训练入口)
pretrain_gpt.py (gpt 训练入口)
...
对于 model 部分
在 model 中定义了模型结构,如果要定义一个新模型,只需要定义 extended_attention_mask, position_ids, LMHead, language_model_processing, Model 即可,比如以 RoFormer 为例
https://github.com/Oneflow-Inc/LibaiLM/blob/53a243fbe4692c9bbc6b5a28691f3529af656054/model/roformer_model.py#L23-L145
-
优点:如果模型整体以 transformer 堆叠的 encoder 作为 backbone 提取 feature,只是修改 position encoding 以及后续和 loss 相关的部分,实现新的模型相对是简单的
-
缺点:如果需要修改 transformer 内部的逻辑,比如类似 roformer 需要在 attention 部分加入旋转位置编码,这时就需要直接去修改 transformer 里面的代码,不能做到模块化的方式来插入这个部分的代码
对于 mpu 部分
这个部分主要实现了模型并行需要的东西,主要就是分布式的 linear 层类似的小计算单元
- 优点:分离普通的 layer 和并行的 layer,使得代码在阅读上更清晰,同时将需要高度手工定制的 layer 抽象出来也方便其他代码的调用
- 缺点:高度定制化的代码只能针对特定情况进行使用,不够灵活
Training
整体的训练代码通过 functional 的方式进行实现,里面没有面向对象的概念,所有的接口都是通过函数互相调用,在写一个新的模型训练时,只需要定义 model_provider, get_batch, loss_func, forward_step 等函数即可自定义训练方式
- 优点:函数式编程使得自定义训练流程比较灵活,用户不需要去 hack 内部的常规训练代码,只需要将自己修改的部分加入即可
- 缺点:自定义的位置是固定的,如果需要对训练流程进行更自由的定义,则需要去改内部的训练逻辑
megatron 整体上是一个高度自定义的分布式训练模型库,它支持的模型类型和训练方式都比较固定,对于修改比较小的任务而言,直接使用会比较方便,如果在模型内部需要较多的自定义,则需要对 megatron 整体进行改动,所以对于 research 来说并不是特别友好,同时由于其函数式编程方式,不希望在函数中传入配置,所以不管是在模型定义还是训练中,都有大量的 args = get_args() 来获取全局配置,这在阅读代码的时候并不友好,需要实际运行才能知道里面参数的具体数值,同时如果用户想抽取其中一个 layer 在外部使用时,也必须带上 args=get_args(),这会让外部用户没有办法进行使用
最后一个缺点我认为是 megatron 的训练配置没有办法很直观的显示出来,要么通过 console 进行展示,或者是通过 shell 脚本进行查看,更直观的方式是在训练开始的时候将训练配置存成一个 yaml,这样用户可以很方便的通过 diff conf1 conf2 来得到两次训练配置的区别从而还方便的知道改动。
xformer https://github.com/facebookresearch/xformers
xformer 的整体结构如下
xformers
componenets (一些模型需要的零组件)
attention (attention 模块)
fourier_mix.py
ortho.py
lambda_layer.py
scaled_dot_product.py
feedforward (前馈网络)
fused_mlp.py
mlp.py
positional_embedding (位置编码)
sine.py
vocab.py
activations.py (激活函数)
residual.py (残差连接)
reversible.py
factory
block_factory.py (可编程的网络层生成)
model_factory.py (可编程的模型生成)
helpers (帮助函数)
timm_sparese_attention.py
models (模型)
linformer.py
triton (一些融合算子)
fused_linear_layer.py
activations.py
layer_norm.py
...
xformer 作为一个刚刚开源的 codebase,并没有提供训练代码,主打的卖点是将 Transformer 模型进行精细地拆分,使得每一个模块可以独立组合,最终所有的 sota 模型可以通过这些模块进行不同顺序或者微调进行构建
- 优点:网络的各个层进行模块化,方便用户进行调用,使用 triton 进行算子融合,避免了大量的 cuda 代码
- 缺点:没有大多数完整模型的结构代码啊,没有训练代码,同时不支持分布式 layer
huggingface https://github.com/huggingface/transformers
hugginface 的整体结构如下
transformers
data (数据处理函数)
models (模型部分)
albert
bart
beit
bert
big_bird
...
- 优点:huggingface 提供了最全面的模型,同时有训练代码,模型构建支持 tf1.0/2.0,pytorch 以及 jax,模型转化支持 onnx,支持几乎所有的下游任务以及详细的 example 和教程
- 缺点:只支持最简单的数据并行,同时模型之间互相没有关系,每一个模型都是一份完整的代码,如果要定义一个新模型需要大量的重复劳动
fairseq
fairseq的组织架构如下:
fairseq
examples (具体任务相关的代码,及复现说明)
fairseq
clib (一些操作或算子的cpp或cu实现)
config (几个baseline的config文件,yaml格式)
criterions(所有损失函数,继承fairseq_criterion类,使用时需要注册,每个损失函数可添加自己的参数)
data (数据读取相关,实现了词表、迭代器和很多种dataset,常用的是indexed_dataset、monolingual_dataset、language_pair_dataset)
dataclass (配置参数,以及参数override操作)
distributed (数据并行的相关配置,如数据切片)
logging (日志,progress_bar)
model_parallel (基于megatron-lm的核心部分mpu,数据加载相关部分和megatron相差很大)
models (模型(transformer)或基础模型(encoder、decoder),使用时需要注册,里面设置了多个模型的配置,例如注册transformer-base,就无需填写模型其他参数)
modules (模块,如attention、positional_embedding、transformer_layer)
optim (优化器和调度器,fp16,使用时需要注册)
tasks (任务类,包括翻译任务、语言模型任务、掩码语言模型任务,去噪任务、句子排序任务等,使用时需要注册)
trainer.py (配置dataloader、调度训练流程)
search.py,sequence_generator.py (生成相关文件,支持beam_search、采样生成等)
register.py (注册机制)
fairseq_cli (提供数据处理、训练、生成等的脚本,安装库后会变成命令,例如,可以使用fairseq-train命令训练,代替python train.py命令)
scripts (平均checkpoint,sentence_piece,构建词表等脚本)
- 优点:
- 训练和推理阶段效率很高。
- 可以按照教程轻松地复现模型,因此跑主流的baseline很合适。
- 熟悉代码后,更改各模块较为简单,因为各模块几乎完全解耦,只需要改一小部分,然后在命令行中更改模块。
- 训练流程规范,日志规范。
- 缺点:
- 新手复现模型容易,但更改模型很难,不知从何下手,学习成本比较高。
- 训练流程固定,很难更改训练逻辑。
- 输入格式常常会让初学者崩溃,看不懂数据处理环境,更别提自定义数据处理。
- 用户只能基于此库进行开发或实验,很难只使用其中的某些部分,若不想基于该框架开发,只能参考代码重新实现。
megatron的痛点
单卡和多卡的代码无法复用; 开发新模型,无法拼装,需要fork代码,然后改代码; 保存的模型,是多机分块的,需要手动拼接成一个完整的模型;
如何设计,解决这些问题
提供一个预训练模型组件库libai。这个库oneflow model / 合作方【当前多个合作的预训练语言模型】 / 新算法 都可以复用。
提供单卡torch风格的基础module 提供oneflow的分布式moudle 用submodule引用组件库的模块,积木一样搭建新模型 数据预处理(如中文)组件
当前基于工厂模式大致构建了如下框架:
- trainer是主体逻辑,在init函数通过build_xxx函数构建训练所需要的组件,如模型、数据集、损失函数等。训练、验证、保存加载等尽量复用同样的代码。
- 对于模型、数据集、损失函数这三类,采用了注册机制,因为各模型或数据集所涉及的参数不同,采用注册机制可以单独未用到的模型添加参数,除此之外,工厂模型也需要注册机制进行实现。在添加新类时,先继承base_model/base_criterion/base_dataset类,然后实现自己的逻辑,之后实现add_args和build_model这样的函数,最后在类名上面添加@register_model('xxx')这样的声明,这样可以在外部轻松切换模型。
- modules文件夹下实现了分布式训练的常用组件,之后视需求再进行补充和完善。
- distribute实现了分布式的配置管理。
- meter实现了几种常用meter,并构建了Logger类,方便日志管理。
- optimizer采用了文骁的写法,之后应该添加lamb这样的优化器,训练大模型时常常会用到(可以在oneflow中实现),lr_scheduler也不完善,之后添加到oneflow中。
- config下定义通用的参数,像模型的hidden size、dropout这类参数,在模型的add_args参数中定义。config会自动解析所需要的参数。
当前问题:
- eager模式不支持amp、gradient checkpointing、set_pipeline_stage_id这类高级特性。
- dataloader有一个问题,目前dataloader负责了加载数据和迭代两个功能,这两个应该是分开的,我在写验证部分时发现,num_samples、batch_size这样的参数无法区分开。之后我再想想数据加载有什么好办法,大家有啥好办法,也可以在下面讨论。
- torch里的amp有多个模式,O1、O2、O3这些,对应半精度的范围不一样,oneflow目前只有一个开关。
- checkpointing机制也只有一个开关,但我不太清楚torch里是怎么做的。
目前外部的 IDEA 项目和 GLM 项目基本都完成了模型搭建的内容,内部的 GPT-3 项目也已经能够跑通模型训练,这个时机已经比较成熟可以推进 LiBai 项目。
LiBai 项目的最终定位希望的是基于 transformer 的大规模预训练模型库,不仅可以做 NLP 的预训练任务,也可以做 CV 相关的预训练,所以和目前我们做的 oneflow-text 以及 oneflow-nlp 在定位上是不冲突的,我们更专注于基于 transformer 的大模型上,同时发挥 oneflow 在分布式上的优势作为我们的主要竞争力。
目前市面上有两个大规模模型库 https://github.com/NVIDIA/Megatron-LM 和 https://github.com/hpcaitech/ColossalAI 是我们主要的比较对手,和他们的差异性在于:
- 我们提供比较方便的分布式并行接口 (数据并行,张量并行和流水线并行) 的实现,后期甚至可以使用自动并行的特性让用户不用关注并行的问题;
- 我们提供了一套既可以用于 NLP 的预训练,也可以进行 CV 的预训练框架,打通预训练+下游评测的全链路,希望 NLP 和 CV 中做大模型的研究员可以基于我们的 codebase 进行研究工作;
后面我们可以逐步完善代码抽象以及模型的完备,然后加上下游任务的适配。
可以将整个项目分成下面不同的 milestone:
- 完成 modeling 部分的抽象;
- 对齐模型前向结果和训练 loss;
- 完善基本的大模型 (gpt-3, T5, etc...)
- 数据预处理部分的设计 (tokenizer, dataloader, etc...)
- 配置文件的重新设计;
- 完成 Trainer 部分的代码抽象;
- 完成下游任务的评测指标;
- 一些高级特性的完善 (gradient accumulation, amp, etc ...)
大家可以一起讨论,然后补充一下内容。
关于 modeling 部分的设计思考:
- 单卡和多卡的一致性,即既可以跑单卡,也可以跑多卡;
- 抽象的合理性,不能太细粒度,也不能太粗粒度;
- 用户使用体验;
对于 NLP 来说,模型一般分为
- Embedding(word embedding, position embedding, tokentype_embeddings)
- Mask Generation
- Encoder/Decoder(transformer)
- Head(pooling, lm_logits)
- Loss
Embedding
Embedding 可以直接抽象成一个类,里面包含了这三种可以训练的 embedding,如果用户需要采用手工生成的 sin-cos position encoding,可以关掉内部的可训练参数,通过下面的代码在外部自行构建并传入
embedding_out = self.embeddings(token_ids)
position_encoding = self.position_embedding()
embedding_out = embedding_out + position_encoding
需要讨论:是否要讲常用的手工 position encoding 总结起来放在一个文件夹里供代码复用?
Mask Generation
一般来说,mask 都是通过函数进行生成,而且相对来说自由度比较高,用户需要根据自己的需求生成 mask,所以 mask 的部分可以考虑留给用户自定义,我们只需要给出目前几个模型需要的 mask 生成作为参考即可
Encoder/Decoder (Transformer)
Encoder 和 Decoder 基本都是由 Transformer 构成的,而 Transformer 都是由 TransformerLayer 进行多层的堆叠构成的,所以只需要考虑 TransformerLayer 如何进行抽象和拆分即可。
下图是 Encoder + Decoder 的 Transformer 结构,可以看到 Decoder 和 Encoder 唯一的不同即多了一个 cross attention,所以可以考虑用一个统一的 TransformerLayer 进行构建。
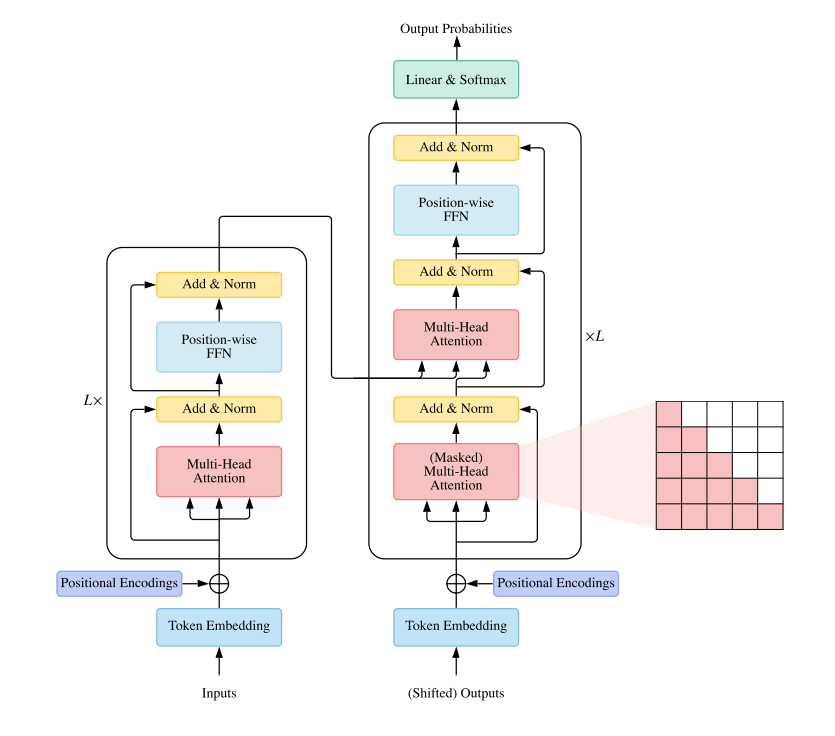
TransformerLayer 可以分为下面几个部分
- Pre-layernorm
- Attention (self attention, cross attention)
- Multi-Head Mechanism
- MLP (Linear)
- Post-layernorm
MLP
MLP 的部分可以考虑将 MLP 和 Linear 可以作为两个 python 文件放到 feedforward 模块中,之所以将这两个部分分开可以方便后面对 Linear 进行扩展到 Linear1D, Linear2D 和 Linear3D 等 tensor parallelism,同理 MLP 也可以类似进行构建,所以分到两个文件中。
Attention & Multi-Head Mechanism
一般来将模型中的注意力机制都是配合在一起使用的,所以一般的代码都是将这两个部分直接写在一起。
需要讨论: 是否要将 Attention 和 Multi-Head Mechanism 分开?
- 合成一起的好处是认为目前的 attention 都是用的 scaled dot product,所以直接写死没有关系;
- 分开的好处则是考虑到如果有人需要替换 scaled dot product,或者是想修改 scaled dot product,那么直接修改重写一个 attention 就好了,解耦了 multi-head 的部分,因为 multi-head 几乎可以认为是一个固定组件;
不同的 Attention 几乎没有本质区别,不管是 Encoder 和 Decoder 都需要输出 q k v 以及 mask,只是 Decoder 中有一个 Attention 的 q k 来自于 Encoder 的输出,所以可以考虑在 Attention 的 forward 中传入 mask
class ScaledDotProduct(nn.Module):
def __init__(self, ...):
...
def forward(self,
q: flow.Tensor,
k: flow.Tensor,
v: flow.Tensor,
attn_mask: Optional[flow.Tensor] = None,
) -> flow.Tensor:
...
另外对于 Encoder 和 Decoder 而言,还有一个差别就是 Decoder 需要额外输入 Encoder 的输出,这里可以在定义 TransformerLayer forward 的时候额外定义两个 optional 输入,在 Encoder 的时候默认是 None ,在 Decoder 的时候传入即可
def forward(
self, hidden_states, attention_mask, encoder_output=None, enc_dec_attn_mask=None
):
Head & Loss
这个部分可复用程度并不高,不同的模型有不同的 head,loss 也都是不同的复杂组合,可以考虑让用户在写模型的时候自己写,可以将目前模型需要用的 loss 写出来作为参考。
我觉得 libai 和 flow-text 各自的定位还需要更清晰一些,有一些点我也没太想明白,需要再讨论
-
最好两者功能上和提供的组件上没有太多的交集,最好是可以复用对方的组件不用重复造轮子
-
Libai 的定位
- 基于 transformer 的大规模模型预训练解决方案,提供如何从单机丝滑拓展到大规模预训练的示例
- 提供丰富的预训练的模型库 ?
- 对于数据加载和预处理 dataloader 这块是否需要放到 libai 这个库,而应该把 cv 的数据加载和预处理用 flow-vision?nlp 的数据集加载和预处理用 flow-text?
- flow-text 的定位
- 我去看了下 torch-text ,感觉 flow-text 需要重新定位一下,torch-text 是提供基础nlp任务所需的常用数据集 loader,词表和常用的评价指标函数等工具,还有一些简单的 nlp 任务的例子,并没有预训练模型的部分
- 如果flow-text也提供bert的预训练模型,这个与 Libai 是否重合了?
- flow-text 的定位如果是对标 torch-text,就是提供 nlp 任务中常用的工具包,不会涉及训练和提供预训练的模型
看了一下目前libai、primeLM、GLM的代码,目前模块抽象如下:
- VocabularyParallelEmbedding,PositionalEmbedding,普通Embedding(用于bert的type embedding)
- Linear1D,ColumnParallelLinear,RowParallelLinear,MLP
- Attention(基于self attention,包含很多变种,体现在attention mask和相对位置等方面)
- LayerNorm
- LMLogits(计算logits)
- Pooler(bert二分类或下游任务需要)
- Loss(交叉熵,kl散度,带mask,带label smooth)
- Activation Checkpointing
- Mask helper(我新加的,里面包含了所有attention mask的相关处理,例如将attention mask进行维度拓展,构造下三角掩码矩阵)
GLM当前做法的弊端:仿照pytorch的写法,没有使用sbp、placement这些oneflow特色,无法体现我们的优势。所以建议采用另外两个库当前的写法。另外,这两种做法的运行速度是什么样,哪种更快一点。
另外两个库当前做法的弊端:需要根据dist确定模型,以及传参多了一项layer idx,用于确定placement。
一个理想的做法:类似pytorch中DataParallel模块,用户按照正常的方法构造模型(默认是单机单卡),如果需要用分布式模型,使用Parallel(dist, model, optimizer)转化成分布式模型。但这样不能使用eager模式,eager模式下立刻搭建模型,会导致大模型无法装入显存。所以,要么延续当前的做法,用户仅需稍微了解一些sbp和placement,要么思考如何设计一个新的模块负责封装分布式。
-
关于 bert 的预训练模型我觉得两边都可以做,区别在于 flow-text 提供的能力是单卡就能 train 的 bert,主要是提供非常简单的模型写法,比如不用考虑 sbp 之类的问题,提供 nn.Module 就可以,用户小规模也能使用;而 LiBai 可以提供的能力是可以支持非常大的 bert 模型,这边对于代码的可读性要求会低一些,会有更多和分布式相关的内容;
-
dataloader 的部分我觉得各自做就好了,因为 dataloader 一般也很难做到完全复用,而且不同的库的定位导致他们面对的数据规模是不同的,很难用同一套东西在两边复用;
看了一下目前libai、primeLM、GLM的代码,目前模块抽象如下:
- VocabularyParallelEmbedding,PositionalEmbedding,普通Embedding(用于bert的type embedding)
- Linear1D,ColumnParallelLinear,RowParallelLinear,MLP
- Attention(基于self attention,包含很多变种,体现在attention mask和相对位置等方面)
- LayerNorm
- LMLogits(计算logits)
- Pooler(bert二分类或下游任务需要)
- Loss(交叉熵,kl散度,带mask,带label smooth)
- Activation Checkpointing
- Mask helper(我新加的,里面包含了所有attention mask的相关处理,例如将attention mask进行维度拓展,构造下三角掩码矩阵)
GLM当前做法的弊端:仿照pytorch的写法,没有使用sbp、placement这些oneflow特色,无法体现我们的优势。所以建议采用另外两个库当前的写法。另外,这两种做法的运行速度是什么样,哪种更快一点。
另外两个库当前做法的弊端:需要根据dist确定模型,以及传参多了一项layer idx,用于确定placement。
一个理想的做法:类似pytorch中DataParallel模块,用户按照正常的方法构造模型(默认是单机单卡),如果需要用分布式模型,使用Parallel(dist, model, optimizer)转化成分布式模型。但这样不能使用eager模式,eager模式下立刻搭建模型,会导致大模型无法装入显存。所以,要么延续当前的做法,用户仅需稍微了解一些sbp和placement,要么思考如何设计一个新的模块负责封装分布式。
consistent + graph 应该是最终的训练选择,但是 graph 对于 debug 不太便利,所以考虑 consistent + eager 进行 debug,我觉得应该完全放弃对 ddp 这种方式的支持,首先 ddp 只能做数据并行,另外和 consistent 不兼容,如要要加上去的话需要修改很多代码
目前定义每一个模块同时能在单卡下跑,也能在多卡下跑就可以解决单卡和多卡切换的问题,不用额外加一个 Parallel wrapper 去包一层
- 关于 bert 的预训练模型我觉得两边都可以做,区别在于 flow-text 提供的能力是单卡就能 train 的 bert,主要是提供非常简单的模型写法,比如不用考虑 sbp 之类的问题,提供 nn.Module 就可以,用户小规模也能使用;而 LiBai 可以提供的能力是可以支持非常大的 bert 模型,这边对于代码的可读性要求会低一些,会有更多和分布式相关的内容;
- dataloader 的部分我觉得各自做就好了,因为 dataloader 一般也很难做到完全复用,而且不同的库的定位导致他们面对的数据规模是不同的,很难用同一套东西在两边复用;
感觉可以
consistent + graph 应该是最终的训练选择,但是 graph 对于 debug 不太便利,所以考虑 consistent + eager 进行 debug,我觉得应该完全放弃对 ddp 这种方式的支持,首先 ddp 只能做数据并行,另外和 consistent 不兼容,如要要加上去的话需要修改很多代码
我不是说支持ddp这个模块,而是设计一个类似于ddp的模块,这个模块可以封装在model的外层,负责将原始的单机单卡model变为分布式model。但原始模型可能无法放入到单个gpu中,所以eager模式可能无法使用,只能以一种lazy的方法,在调用模型或者调用我们设计的这个模块时,把模型的参数在各自的机器上初始化。
consistent + graph 应该是最终的训练选择,但是 graph 对于 debug 不太便利,所以考虑 consistent + eager 进行 debug,我觉得应该完全放弃对 ddp 这种方式的支持,首先 ddp 只能做数据并行,另外和 consistent 不兼容,如要要加上去的话需要修改很多代码
我不是说支持ddp这个模块,而是设计一个类似于ddp的模块,这个模块可以封装在model的外层,负责将原始的单机单卡model变为分布式model。但原始模型可能无法放入到单个gpu中,所以eager模式可能无法使用,只能以一种lazy的方法,在调用模型或者调用我们设计的这个模块时,把模型的参数在各自的机器上初始化。
ddp 就表示只能做分布式数据并行,如果是封装拓展单卡到多卡模型的模块,应该要换个名字,比如 dhp ( distributed hybrid parallel)
consistent + graph 应该是最终的训练选择,但是 graph 对于 debug 不太便利,所以考虑 consistent + eager 进行 debug,我觉得应该完全放弃对 ddp 这种方式的支持,首先 ddp 只能做数据并行,另外和 consistent 不兼容,如要要加上去的话需要修改很多代码
我不是说支持ddp这个模块,而是设计一个类似于ddp的模块,这个模块可以封装在model的外层,负责将原始的单机单卡model变为分布式model。但原始模型可能无法放入到单个gpu中,所以eager模式可能无法使用,只能以一种lazy的方法,在调用模型或者调用我们设计的这个模块时,把模型的参数在各自的机器上初始化。
目前有三种分布式训练方式,eager + ddp,eager + consistent 和 graph + consistent,我的意思是我们可以考虑放弃 eager + ddp 这种训练方式
另外就是是否要在 module 外面封一层将单卡 module 变成多卡,我觉得这个是 pytorch 的做法,如果我们有更好的方式,其实不需要 follow 他这种方式