echopype
 echopype copied to clipboard
echopype copied to clipboard
Investigate memory usage of `ZarrCombine`
When first creating the ZarrCombine class, it was found that combining a large number of files could lead to a substantial increase in memory usage. In PR #824 the class variable max_append_chunk_size was created so that we could limit how large the chunks could get and this limitation curbs the increase in memory usage. Currently, we have set max_append_chunk_size=1000, however, no real study has went into this upper bound.
It is important that we do one of the following:
- Conduct a study on various file types and obtain a heuristically driven value for this upper bound
- Let
max_append_chunk_sizebe an input tocombine_echodata - Set an upper bound for the maximum amount of memory per chunk (say 50MiB) and automatically determine
max_append_chunk_sizebased on this limitation for each variable/coordinate.
Perfect that you created this issue! I am currently reviewing #824 and looked at the combined echodata object. Here's an example of one of the data array from the Beam group:
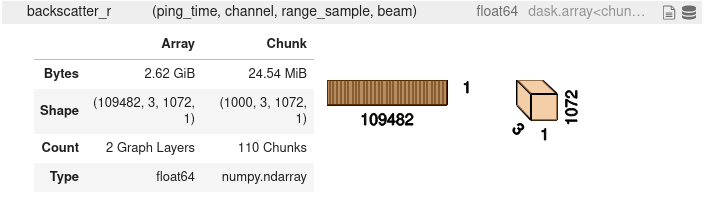 The new
The new combine_echodata method works great so far, however, the chunk sizes are way to small. You can see that there are 110 chunks for this particular array! That's gonna be a lot of I/O happening. I think there should be a way to specify the chunk size maybe as MB/GB etc rather than just an integer. At the end of the day I can see maybe around 100MB chunk size for a 1GB of array, rather than the current 25MB chunk size. Btw dask.utils.parse_bytes is a great function to parse the string to regular bytes integer.
This is now addressed in https://github.com/OSOceanAcoustics/echopype/pull/1042.