Transformers-Tutorials
 Transformers-Tutorials copied to clipboard
Transformers-Tutorials copied to clipboard
TrOCR Printed Text have Extra Results
Hi,
I was trying to do inference on cropped text regions which are printed, using the trocr-base-printed model.
It's doing well, but on certain images it's giving some extra results which is weird.
Example 1
 Results:
Results:
ACCOUNT ON D ON D
The images is Account, which it predicted, but it's also adding ON D ON D
Example 2
 Result:
Result:
29/11/1936 / 2/ 2/
Similarly, the images is 29/11/1936, but also predicted extra / 2/ 2/
Example 3
 Result:
Result:
PREVIOUS ONCLUSE SIGNE SUBE SOLDE SOLD
The image is Previous, but the model is predicting many things along with Previos.
Hi,
Thanks for reporting. I'm suspecting this may have to do with the decoding settings, rather than the model. In HuggingFace, one uses the generate method which is defined for all generative models. By default, it uses greedy decoding, but it can also perform beam search or top-k sampling decoding.
Can you try adjusting these settings, and report back?
Thanks!
Thanks, Will look into top-k predictions, will run the inference with that and will get back here with results.
Hi,
After investigation, it turns out the generate() method currently does not take into account config.decoder.eos_token_id, only config.eos_token_id.
You can fix it by setting model.config.eos_token_id = 2.
We will fix this soon.
Hi thanks for all your efforts,
I have one use case. Can we read texts from the images like shown in the image below, using TrOCR. I have tried with inference used in space by changing checkpoint to trocr-base-printed . I got weird results. Do I need to fine_tune the model by creating new dataset by showing actual target values then Should I use that model for inference. Sorry I am new to this space. Can you please guide me what to do to predict the actual text in the image. some times many other texts present in the image, how to get the only required text, instead of many other non essential texts.

Hi,
Yes that's possible, take a look at this Space: https://huggingface.co/spaces/vishnun/CRAFT-OCR.
It combines text detection (CRAFT) with text recognition (TrOCR).
Hello,
I have the same problem with handwritten text using google/vit-base-patch16-224-in21k as encoder and indobenchmark/indobert-base-p1 as decoder
All the result didn't predict well and give some extra results too even with train dataset,
Example:
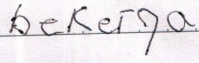 Result:
dan dalam sebagai sebagai sebagai. atau / akan / mana berjalan termasuk / mana awal misalnya atau atau karena ingat atau ". atau kemudian. tanpa tetaplah. atau atau atas harus ) adalah perlu jugaika lagi. * khusus lagi tanpa termasuk lokal dalam perlu perlu bantuan lagi dapat untuk luar termasuk atau atassemwiika hutan kita
Result:
dan dalam sebagai sebagai sebagai. atau / akan / mana berjalan termasuk / mana awal misalnya atau atau karena ingat atau ". atau kemudian. tanpa tetaplah. atau atau atas harus ) adalah perlu jugaika lagi. * khusus lagi tanpa termasuk lokal dalam perlu perlu bantuan lagi dapat untuk luar termasuk atau atassemwiika hutan kita
I following fine tune seq2seq tutorial, but when I try fine tune with native pytorch It works well
Hello, I have the same problem with handwritten text using
google/vit-base-patch16-224-in21kas encoder andindobenchmark/indobert-base-p1as decoderAll the result didn't predict well and give some extra results too even with train dataset, Example:
I following fine tune seq2seq tutorial, but when I try fine tune with native pytorch It works well
@dhea1323 Hi, I'm currently trying to train TrOCR on a German custom Data-Set. I am not sure what the correct settings are for Processor and Model. If I train to another language, can I do a warm start at all, or is that not possible because I am using a different tokenizer? I would be very happy if you could show me your model and processor initialization. And if there are other important things you could tell me. Thanks a lot!
@abdksyed @NielsRogge were you able to solve this issue? Tried setting eos token as @NielsRogge said, but dint work out, any possible solutions?
Nope, the last time I checked, it didn't work. But I don't know after almost 18 months if there is any change or not.