K8 cluster generating excessive "other IOPS" on NetApp NAS nodes.
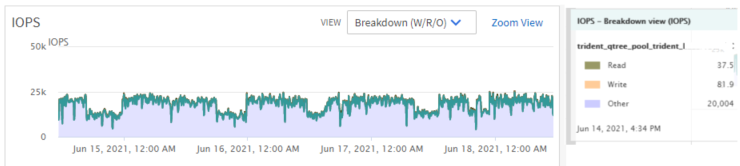
Describe the bug Is anyone else seeing K8 clusters generating excessive "other IOPS" on NetApp NAS nodes?
We have several K8 clusters with thousands of PVC's spread across hundreds of NAS volumes on multiple NAS clusters. On ~80% of the NAS volumes, we're seeing 10,000+ of "other IOPS" with a relatively low amount of read or write IOPS.
The behavior is pushing the NAS node utilization to 90%+ CPU utilization. We hid the snapshot directory on the volumes, which substantially reduced the "other IOPS" and node utilization, but it seems there should be more options/understanding for further reducing the "other IOPS" and node utilization.
Is anyone else seeing K8 clusters generating excessive "other IOPS" on NetApp NAS nodes?
Environment Provide accurate information about the environment to help us reproduce the issue.
- Trident version: 19.04
- Trident installation flags used: TBD
- Container runtime: TBD
- Kubernetes version: 1.11
- Kubernetes orchestrator: TBD
- Kubernetes enabled feature gates: TBD
- OS: Linux version TBD
- NetApp backend types: OnTap 9.7
- Other:
To Reproduce The breakdown of IOPS can be seen in the default volume performance graphs within AIQUM.
Expected behavior A more even distribution of read, write, and other IOPS.
Additional context None.
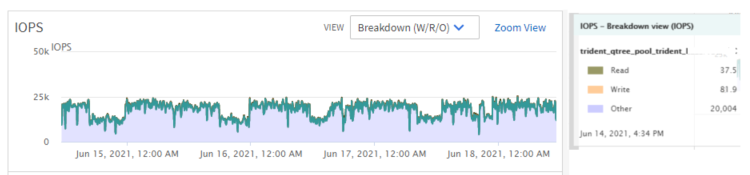
Hi @jbuchanan360,
Any IOPS that are not read or write are called "Other IOPS". The NFS client activities like getattr, listing files, or even a shell running the ls command will fall into this category. Here is a NetApp Knowledge Base article that includes a summary of procedures: What operations are categorized under Other IOPS in ONTAP?
Hi Gnarl, thank you for responding and the details. We have a large NetApp environment with several petabytes of storage. The amount and percentage of "other IOPS" in the NAS volumes for the container/K8 environment is much higher than we see in our general purpose NetApp NAS environment.
There seems to be some type of unnecessary scanning of files occurring considering the other IOPS dropped by ~50% when we hid the snapshot directory (which then substantially lowered NAS node cpu utilization).
I'm wondering if other shops utilizing Kubernetes with NetApp NAS are seeing a large percentage of the IOPS being "other". Ideally show the same volume performance graph I provided above.
I'm also wondering if other shops were able to reduce the other IOPS, which then reduced node utilization in our case.
Hi @jbuchanan360,
Considering that Trident isn't involved with the data path I'd compare the workloads that you are running in your Pods compared to your general purpose NAS environment. Also, in your image you are showing a "trident_qtree_pool..." which means that you are using the ontap-nas-economy driver. The ontap-nas-economy driver creates many PVs (qtrees) and adds them to a FlexVol volume that is treated as a storage pool. So in this case you could be comparing a FlexVol containing multiple PVs to a general purpose NAS workload where one application is accessing a single FlexVol.
We made significant progress on this issue by disabling Prometheus, a Jenkins plug-in that was capturing disk usage stats. The following graphs show a before/after picture from the NetApp perspective when Prometheus was disabled on August 7th:

Closing this issue as the excess IOPS was being generated by the Prometheus configuration. Thank you @jbuchanan360 for posting a comment on your investigation.