Reuse the first gpu when there are multiple gpu training tasks
Run the training task using kubeflow's tfjob.
When I run a gpu training task everything works fine,
When I run multiple gpu training tasks, each task tries to use the first gpu,until the first gpu is full. The result is the training task report an OOM exception
I am having this same issue with both PyTorch Elastic and Kubeflow's PyTorchJob CRDs. A single multi-worker job works as expected, scheduling to N unique GPUs. But, when I schedule multi-worker jobs via those CRDs to Kubernetes, the subsequent workers are scheduled onto the same devices:
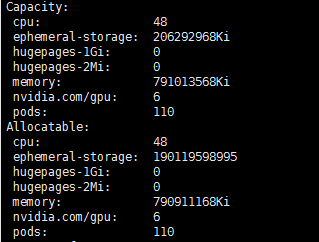
The last column contains the PIDs allocated to the GPU, and both are from successive scheduling an 8-worker job via the ElasticJob operator. That particular node has 10 GPUs and the cluster has 40 in total and they arent in use
research2 | 04 | GeForce GTX 1080 Ti | NO | /usr/bin/python3.6 /usr/bin/python3.6 | 12687 16510
research2 | 05 | GeForce GTX 1080 Ti | NO | /usr/bin/python3.6 /usr/bin/python3.6 | 12679 16484
research2 | 06 | GeForce GTX 1080 Ti | NO | /usr/bin/python3.6 /usr/bin/python3.6 | 12685 16481
research2 | 07 | GeForce GTX 1080 Ti | NO | /usr/bin/python3.6 /usr/bin/python3.6 | 12677 16498
research2 | 08 | GeForce GTX 1080 Ti | NO | /usr/bin/python3.6 /usr/bin/python3.6 | 12682 16508
research2 | 0B | GeForce GTX 1080 Ti | NO | /usr/bin/python3.6 /usr/bin/python3.6 | 12691 16441
research2 | 0C | GeForce GTX 1080 Ti | NO | /usr/bin/python3.6 /usr/bin/python3.6 | 12689 16571
research2 | 0D | GeForce GTX 1080 Ti | NO | /usr/bin/python3.6 /usr/bin/python3.6 | 12683 16490
The only way I have found around this is to use a label selector to force it onto a different node, but that is not optimal.
I was hoping that if we updated to the latest version of k8s-device-plugin the issue would be resolved but this occurs even on 0.7.1.
The k8s docs (and other tickets in this tracker) seem to claim this isnt possible so I assume that there is a bug:_ https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
"Containers (and Pods) do not share GPUs. There's no overcommitting of GPUs."
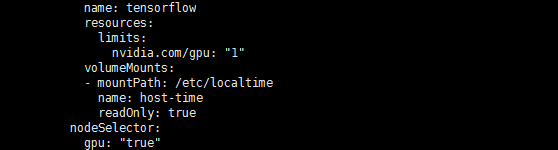
In my case it appears I was able to fix by setting nvidia.com/gpu:
resources:
limits:
nvidia.com/gpu: 1
@dpressel how were you requesting the GPUs before, if not via:
resources:
limits:
nvidia.com/gpu: 1
If you don't set this at all, and your job lands on a node with GPUs, it will consume all of them by default
we were using code to generate the kubernetes request via the API and it was erroneously setting the limit to 0, which did not try to take all GPUs on the machine (there are 10 as I mentioned), but did allow scheduling to the same 8 devices again and did use the GPUs until the resources were exhausted
This issue is stale because it has been open 90 days with no activity. This issue will be closed in 30 days unless new comments are made or the stale label is removed.