[QST] How to use slicedK in GEMM?
Hi! I have written a code for slicedK in GEMM, but it seems very slow....I tried to understand cutlass's slicedK, but can not understand it....So I post my code here and explain my concept, hoping someone can give me some suggestions....Thank you!!!
So the basic idea comes from cutlass's post. My allocation is: 64 threads (2 warps) to calculate 64 * 64 size. each thread read 4 values from A and 4 values from B. And calculate 64 results. We arrange 256 threads(8 waprs) in total, so this is sliced-4. 4 groups of warps calculate a same 64 * 64 location, but the K is split, so the final results need to be reduced.
In shared memory, I insert 1/4 of the 64 results in each threads, which is 32 * 32 one time, (take up 16KB), and repeat this 4 times. Each time we add the corresponding location's value and get 4KB's result, write into global memory.
The nsight compute shows:
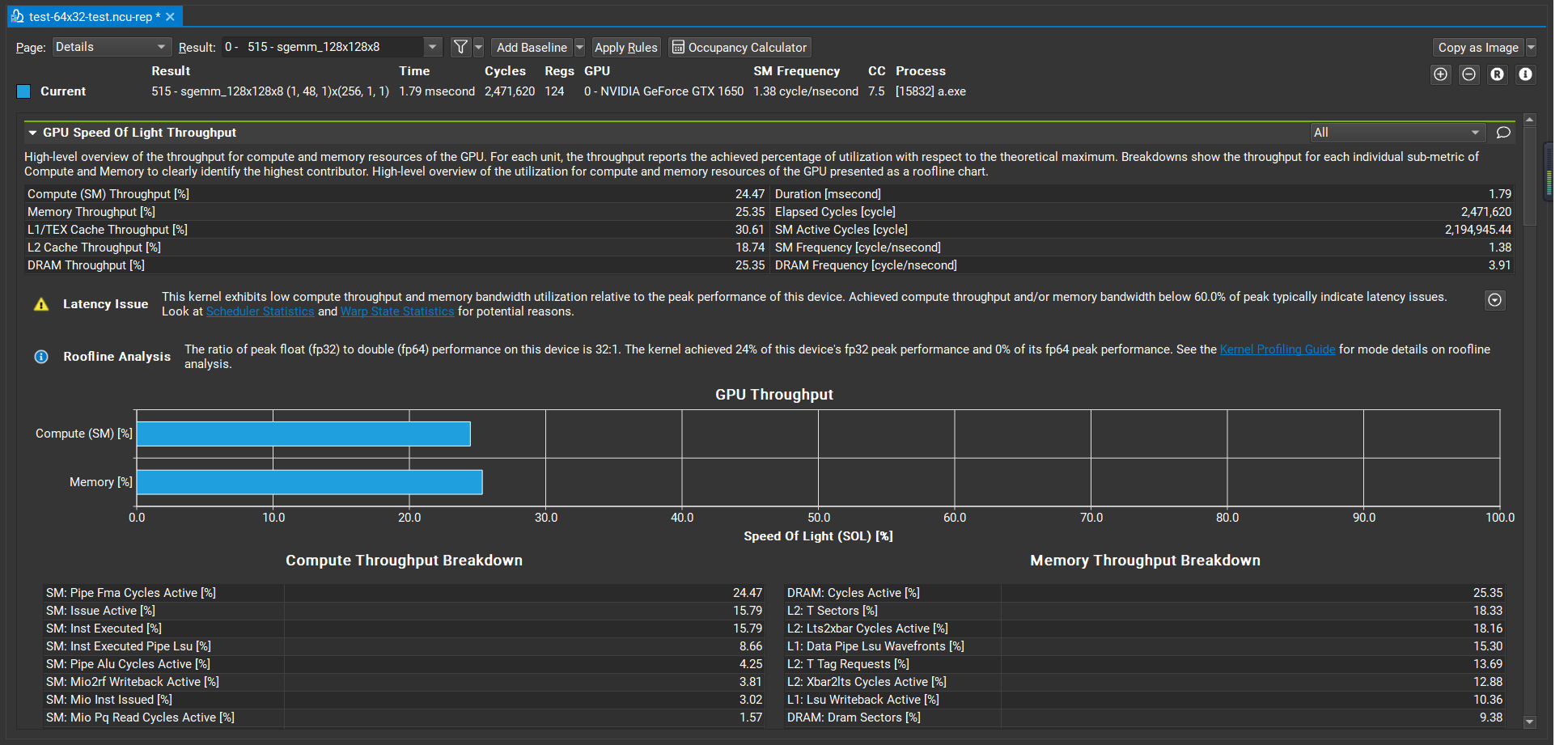
Thank you!!!!!
(By the way, where is the code for detailed cutlass's sliceK...? I am completely lossed inside....)
#include<iostream>
using namespace std;
#include <cstdint>
#include <cstdlib>
#include <cstdio>
#include <cmath>
#include <vector>
#define FETCH_FLOAT4(pointer) (reinterpret_cast<float4*>(&(pointer))[0])
bool check(const float *A,
const float *B,
const float *C,
int m, int n, int k) {
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
float sum = 0.f;
for (int p = 0; p < k; ++p) {
sum += A[i * k + p] * B[j + p * n];
}
if (std::fabs(sum - C[i * n + j]) / std::fabs(sum) > 1e-5f) {
printf("C[%d][%d] not match, %f vs %f\n", i, j, sum, C[i * n + j]);
return false;
}
}
}
return true;
}
__device__ __forceinline__
uint32_t smem_u32addr(const void *smem_ptr) {
uint32_t addr;
asm("{.reg .u64 u64addr;\n"
" cvta.to.shared.u64 u64addr, %1;\n"
" cvt.u32.u64 %0, u64addr;}\n"
: "=r"(addr)
: "l"(smem_ptr)
);
return addr;
}
__device__ __forceinline__
void ldg32_nc(float ®, const void *ptr, bool guard) {
asm volatile (
"{.reg .pred p;\n"
" setp.ne.b32 p, %2, 0;\n"
#if __CUDACC_VER_MAJOR__ >= 11 && __CUDACC_VER_MINOR__ >= 4 && \
__CUDA_ARCH__ >= 750
" @p ld.global.nc.L2::128B.f32 %0, [%1];}\n"
#else
" @p ld.global.nc.f32 %0, [%1];}\n"
#endif
: "=f"(reg)
: "l"(ptr), "r"((int)guard)
);
}
__device__ __forceinline__ void ldg32_nc_0(float ®, const void *ptr) {
asm volatile("{mov.b32 %0, 0;\n"
#if __CUDACC_VER_MAJOR__ >= 11 && __CUDACC_VER_MINOR__ >= 4 && \
__CUDA_ARCH__ >= 750
"ld.global.nc.L2::128B.f32 %0, [%1];}\n"
#else
"ld.global.nc.f32 %0, [%1];}\n"
#endif
: "=f"(reg)
: "l"(ptr));
}
__device__ __forceinline__
void stg32(const float ®, void *ptr, bool guard) {
asm volatile (
"{.reg .pred p;\n"
" setp.ne.b32 p, %2, 0;\n"
" @p st.global.f32 [%0], %1;}\n"
: : "l"(ptr), "f"(reg), "r"((int)guard)
);
}
__device__ __forceinline__
void lds128(float ®0, float ®1,
float ®2, float ®3,
const uint32_t &addr) {
asm volatile (
"ld.shared.v4.f32 {%0, %1, %2, %3}, [%4];\n"
: "=f"(reg0), "=f"(reg1), "=f"(reg2), "=f"(reg3)
: "r"(addr)
);
}
__device__ __forceinline__
void sts32(const float ®, const uint32_t &addr) {
asm volatile (
"st.shared.f32 [%0], %1;\n"
: : "r"(addr), "f"(reg)
);
}
__device__ __forceinline__
void sts128(const float ®0, const float ®1,
const float ®2, const float ®3,
const uint32_t &addr) {
asm volatile (
"st.shared.v4.f32 [%0], {%1, %2, %3, %4};\n"
: : "r"(addr), "f"(reg0), "f"(reg1), "f"(reg2), "f"(reg3)
);
}
__device__ __forceinline__
void sts64(const float ®0, const float ®1,
const uint32_t &addr) {
asm volatile (
"st.shared.v2.f32 [%0], {%1, %2};\n"
: : "r"(addr), "f"(reg0), "f"(reg1)
);
}
struct StgFrag {
float data[4][4];
__device__ __forceinline__
StgFrag(const float(&C_frag)[8][8], int tile_x, int tile_y) {
#pragma unroll
for (int i = 0; i < 4; ++i) {
#pragma unroll
for (int j = 0; j < 4; ++j) {
data[i][j] = C_frag[tile_y * 4 + i][tile_x * 4 + j];
}
}
}
};
__device__ __noinline__
void C_tile_wb(StgFrag C_frag,
float *C_stg_ptr,
const float *C_lds_ptr,
uint32_t C_sts_addr,
uint32_t m,
uint32_t n,
uint32_t m_idx,
uint32_t n_idx) {
__syncthreads();
#pragma unroll
for (int i = 0; i < 4; ++i) {
sts128(C_frag.data[i][0],
C_frag.data[i][1],
C_frag.data[i][2],
C_frag.data[i][3],
C_sts_addr + i * 8 * sizeof(float4));
}
__syncthreads();
uint32_t m_guard = m < m_idx ? 0 : m - m_idx;
#pragma unroll
for (int i = 0; i < 16; ++i) {
stg32(C_lds_ptr[i * 32],
C_stg_ptr + i * n,
i < m_guard && n_idx < n);
}
}
__device__ __forceinline__ void stg128(const float ®0, const float ®1,
const float ®2, const float ®3,
const float *addr) {
asm volatile("st.global.v4.f32 [%0], {%1, %2, %3, %4};\n"
:
: "l"(addr), "f"(reg0), "f"(reg1), "f"(reg2), "f"(reg3));
}
__global__ __launch_bounds__(256, 2) void sgemm_128x128x8(uint32_t m,
uint32_t n,
uint32_t k,
float *A,
float *B,
float *C) {
__shared__ __align__(8 * 1024) char smem[20 * 1024]; // 16.5KB
float *A_smem = reinterpret_cast<float *>(smem);
float *B_smem = reinterpret_cast<float *>(smem + 8704); // 8.5KB
// A, B and C register fragment
float A_frag[2][8];
float B_frag[2][8];
float C_frag[8][8];
#pragma unroll
for (int i = 0; i < 8; ++i) {
#pragma unroll
for (int j = 0; j < 8; ++j) {
C_frag[i][j] = 0;
}
}
const uint32_t lane_id = threadIdx.x % 32;
const uint32_t warp_id = threadIdx.x / 32;
// 4x8 threads each warp for FFMA
const uint32_t mma_tid_x = (lane_id / 2) % 8;
const uint32_t mma_tid_y = (lane_id / 16) * 2 + (lane_id % 2);
// A_tile & B_tile ldg pointer
int from_a = (blockIdx.y * 64 + (threadIdx.x % 64) / 4 * 4) * k + (threadIdx.x % 64) % 4 + (threadIdx.x / 64) * (k / 4);
int from_b = ((threadIdx.x % 64) / 16 + (threadIdx.x / 64) * (k / 4)) * n + blockIdx.x * 64 + (threadIdx.x % 64) % 16 * 4;
// A_tile & B_tile sts/lds pointer
// using uint32_t pointer for faster double buffer switch
uint32_t A_lds_addr = smem_u32addr(
A_smem + (warp_id % 2) * 32 + mma_tid_y * 4 + (threadIdx.x / 64) * 68 * 4);
uint32_t B_lds_addr = smem_u32addr(
B_smem + mma_tid_x * 4 + (threadIdx.x / 64) * 64 * 4);
float4 b_ldg_reg;
float a_ldg_reg[4];
uint32_t a_sts_addr = smem_u32addr(A_smem + ((threadIdx.x % 64) % 4) * 68 + ((threadIdx.x % 64) / 4) * 4 + (threadIdx.x / 64) * 68 * 4);
uint32_t b_sts_addr = smem_u32addr(B_smem + ((threadIdx.x % 64) / 16) * 64 + ((threadIdx.x % 64) % 16) * 4 + (threadIdx.x / 64) * 64 * 4);
// 1'st A&B tile loaded before the k_tile loop
uint32_t k_tiles = (k / 4 + 3) / 4 - 1;
uint32_t first_k_tile = k / 4 - k_tiles * 4 + (k / 4)*(threadIdx.x / 64);
// load 1'st tile to shared memory
{
// load first
// load gmem to smem for ashare
#pragma unroll
for (int i = 0; i < 4; ++i) {
if ((threadIdx.x % 64) % 4 + (threadIdx.x / 64)*(k / 4) < first_k_tile && blockIdx.y * 64 + (threadIdx.x % 64) / 4 * 4 + i < m) {
ldg32_nc_0(a_ldg_reg[i], (const char *)(A + from_a) + i * k * sizeof(float));
}
else {
a_ldg_reg[i] = 0;
}
}
sts128(a_ldg_reg[0], a_ldg_reg[1], a_ldg_reg[2], a_ldg_reg[3], a_sts_addr);
// load gmem to smem for bshare
if (from_b < (1 + (threadIdx.x % 64) / 16 + (threadIdx.x / 64)*(k / 4))*n && (threadIdx.x % 64) / 16 + (threadIdx.x / 64)*(k / 4) < first_k_tile) {
b_ldg_reg = FETCH_FLOAT4(B[from_b]);
}
else {
b_ldg_reg = float4{ 0, 0, 0, 0 };
}
FETCH_FLOAT4(B_smem[((threadIdx.x % 64) / 16) * 64 + ((threadIdx.x % 64) % 16) * 4 + (threadIdx.x / 64) * 64 * 4]) = b_ldg_reg;
__syncthreads();
// add offset and flip flag
from_a += k / 4 - k_tiles * 4;
from_b += (k / 4 - k_tiles * 4) * n;
a_sts_addr += 68 * 4 * 4 * sizeof(float);
b_sts_addr += 64 * 4 * 4 * sizeof(float);
}
// load 1'st fragment
lds128(A_frag[0][0], A_frag[0][1], A_frag[0][2], A_frag[0][3],
A_lds_addr);
lds128(A_frag[0][4], A_frag[0][5], A_frag[0][6], A_frag[0][7],
A_lds_addr + 16 * sizeof(float));
lds128(B_frag[0][0], B_frag[0][1], B_frag[0][2], B_frag[0][3],
B_lds_addr);
lds128(B_frag[0][4], B_frag[0][5], B_frag[0][6], B_frag[0][7],
B_lds_addr + 32 * sizeof(float));
int jump = 0;
// k_tiles loop
for (; k_tiles > 0; --k_tiles) {
jump ^= 1;
#pragma unroll
for (int k_frag = 0; k_frag < 4; ++k_frag) {
// store next A&B tile to shared memory
if (k_frag == 3) {
sts128(a_ldg_reg[0], a_ldg_reg[1], a_ldg_reg[2], a_ldg_reg[3], a_sts_addr);
sts128(b_ldg_reg.x, b_ldg_reg.y, b_ldg_reg.z, b_ldg_reg.w, b_sts_addr);
__syncthreads();
// switch double buffer
if (jump == 1) {
A_lds_addr += 68 * 4 * 4 * sizeof(float);
B_lds_addr += 64 * 4 * 4 * sizeof(float);
a_sts_addr -= 68 * 4 * 4 * sizeof(float);
b_sts_addr -= 64 * 4 * 4 * sizeof(float);
}
else {
A_lds_addr -= 68 * 4 * 4 * sizeof(float);
B_lds_addr -= 64 * 4 * 4 * sizeof(float);
a_sts_addr += 68 * 4 * 4 * sizeof(float);
b_sts_addr += 64 * 4 * 4 * sizeof(float);
}
// ldg pointer for next tile
from_a += 4;
from_b += 4 * n;
}
// load next A&B fragment from shared memory to register
lds128(A_frag[(k_frag + 1) % 2][0],
A_frag[(k_frag + 1) % 2][1],
A_frag[(k_frag + 1) % 2][2],
A_frag[(k_frag + 1) % 2][3],
A_lds_addr + (k_frag + 1) % 4 * 68 * sizeof(float));
lds128(A_frag[(k_frag + 1) % 2][4],
A_frag[(k_frag + 1) % 2][5],
A_frag[(k_frag + 1) % 2][6],
A_frag[(k_frag + 1) % 2][7],
A_lds_addr + ((k_frag + 1) % 4 * 68 + 16) * sizeof(float));
lds128(B_frag[(k_frag + 1) % 2][0],
B_frag[(k_frag + 1) % 2][1],
B_frag[(k_frag + 1) % 2][2],
B_frag[(k_frag + 1) % 2][3],
B_lds_addr + (k_frag + 1) % 4 * 64 * sizeof(float));
lds128(B_frag[(k_frag + 1) % 2][4],
B_frag[(k_frag + 1) % 2][5],
B_frag[(k_frag + 1) % 2][6],
B_frag[(k_frag + 1) % 2][7],
B_lds_addr + ((k_frag + 1) % 4 * 64 + 32) * sizeof(float));
// load next A&B tile
if (k_frag == 0) {
if (from_b < (1 + (threadIdx.x % 64) / 16 + (threadIdx.x / 64)*(k / 4))*n + (-k_tiles * 4 + k / 4)*n && (-k_tiles * 4 + k / 4) + (threadIdx.x % 64) / 16 + (threadIdx.x / 64)*(k / 4) < (threadIdx.x / 64 + 1)*(k / 4)) {
b_ldg_reg = FETCH_FLOAT4(B[from_b]);
}
else {
b_ldg_reg = float4{ 0, 0, 0, 0 };
}
#pragma unroll
for (int i = 0; i < 4; ++i) {
if ((threadIdx.x % 64) % 4 + (threadIdx.x / 64)*(k / 4) + (-k_tiles * 4 + k / 4) < k && blockIdx.y * 64 + (threadIdx.x % 64) / 4 * 4 + i < m) {
ldg32_nc_0(a_ldg_reg[i], (const char *)(A + from_a) + i * k * sizeof(float));
}
else {
a_ldg_reg[i] = 0;
}
}
}
// FFMA loop
#pragma unroll
for (int i = 0; i < 8; ++i) {
#pragma unroll
for (int j = 0; j < 8; ++j) {
C_frag[i][j] += A_frag[k_frag % 2][i] *
B_frag[k_frag % 2][j];
}
}
}
}
// FFMA for the last tile
#pragma unroll
for (int k_frag = 0; k_frag < 4; ++k_frag) {
if (k_frag < 3) {
// load next A&B fragment from shared memory to register
lds128(A_frag[(k_frag + 1) % 2][0],
A_frag[(k_frag + 1) % 2][1],
A_frag[(k_frag + 1) % 2][2],
A_frag[(k_frag + 1) % 2][3],
A_lds_addr + (k_frag + 1) % 4 * 68 * sizeof(float));
lds128(A_frag[(k_frag + 1) % 2][4],
A_frag[(k_frag + 1) % 2][5],
A_frag[(k_frag + 1) % 2][6],
A_frag[(k_frag + 1) % 2][7],
A_lds_addr + ((k_frag + 1) % 4 * 68 + 16) * sizeof(float));
lds128(B_frag[(k_frag + 1) % 2][0],
B_frag[(k_frag + 1) % 2][1],
B_frag[(k_frag + 1) % 2][2],
B_frag[(k_frag + 1) % 2][3],
B_lds_addr + (k_frag + 1) % 4 * 64 * sizeof(float));
lds128(B_frag[(k_frag + 1) % 2][4],
B_frag[(k_frag + 1) % 2][5],
B_frag[(k_frag + 1) % 2][6],
B_frag[(k_frag + 1) % 2][7],
B_lds_addr + ((k_frag + 1) % 4 * 64 + 32) * sizeof(float));
}
// FFMA loop
#pragma unroll
for (int i = 0; i < 8; ++i) {
#pragma unroll
for (int j = 0; j < 8; ++j) {
C_frag[i][j] += A_frag[k_frag % 2][i] *
B_frag[k_frag % 2][j];
}
}
}
// C_tile write back, reuse A&B tile shared memory buffer
uint32_t C_sts_addr = smem_u32addr((float4 *)(smem + warp_id * 2048) +
mma_tid_y * 4 * 8 + mma_tid_x);
uint32_t C_lds_ptr = smem_u32addr(A_smem + (mma_tid_y * 4 * 8 + mma_tid_x) * 4 + (warp_id % 2) * 16 * 32);
uint32_t C_lds_addr = smem_u32addr(A_smem + threadIdx.x / 8 * 32 + (threadIdx.x % 8) * 4);
uint32_t m_idx = blockIdx.y * 64;
if (m_idx >= m) {
return;
}
else if (m_idx + 32 <= m) {
#pragma unroll
for (int i = 0; i < 2; ++i) {
for (int j = 0; j < 2; ++j) {
__syncthreads();
#pragma unroll
for (int p = 0; p < 4; ++p) {
sts128(C_frag[i * 4 + p][j * 4],
C_frag[i * 4 + p][j * 4 + 1],
C_frag[i * 4 + p][j * 4 + 2],
C_frag[i * 4 + p][j * 4 + 3],
C_sts_addr + p * 8 * sizeof(float4));
}
__syncthreads();
lds128(B_frag[0][0], B_frag[0][1], B_frag[0][2], B_frag[0][3], C_lds_addr);
lds128(B_frag[0][4], B_frag[0][5], B_frag[0][6], B_frag[0][7],
C_lds_addr + (32 * 32) * sizeof(float));
lds128(B_frag[1][0], B_frag[1][1], B_frag[1][2], B_frag[1][3],
C_lds_addr + (32 * 32 * 2) * sizeof(float));
lds128(B_frag[1][4], B_frag[1][5], B_frag[1][6], B_frag[1][7],
C_lds_addr + (32 * 32 * 3) * sizeof(float));
B_frag[0][0] += (B_frag[0][4] + B_frag[1][0] + B_frag[1][4]);
B_frag[0][1] += (B_frag[0][5] + B_frag[1][1] + B_frag[1][5]);
B_frag[0][2] += (B_frag[0][6] + B_frag[1][2] + B_frag[1][6]);
B_frag[0][3] += (B_frag[0][7] + B_frag[1][3] + B_frag[1][7]);
if (blockIdx.y * 64 + (threadIdx.x % 128) / 8 + i * 16 + (threadIdx.x / 128) * 32 < m&& blockIdx.x * 64 + (threadIdx.x % 8) * 4 + j * 32 < n) {
stg128(B_frag[0][0], B_frag[0][1], B_frag[0][2], B_frag[0][3], C + (blockIdx.y * 64 + (threadIdx.x % 128) / 8 + i * 16 + (threadIdx.x / 128) * 32)*n + blockIdx.x * 64 + (threadIdx.x % 8) * 4 + j * 32);
}
}
}
}
// else {
//#pragma unroll
// for (int i = 0; i < 2; ++i) {
//#pragma unroll
// for (int j = 0; j < 2; ++j) {
// StgFrag stg_frag(C_frag, j, i);
// C_tile_wb(stg_frag,
// C_stg_ptr + i * 16 * n + j * 32,
// C_lds_ptr,
// C_sts_addr,
// m,
// n,
// m_idx + i * 16,
// n_idx + j * 32);
// }
// }
// }
}
float* random_matrix(int row, int col) {
float* mat = new float[row * col];
for (int i = 0; i < row; ++i) {
for (int j = 0; j < col; ++j) {
if (i * col + j + 1 < 10) {
mat[i * col + j] = i * col + j + 1;
}
else {
mat[i * col + j] = 0.5;
}
}
}
return mat;
}
// float* random_matrix(int row, int col) {
// float* mat = new float[row * col];
//
//
// for (int i = 0; i < row; ++i) {
// for (int j = 0; j < col; ++j) {
// mat[i * col + j] = 0;
// }
// }
//
// return mat;
// }
void print_mat(float* mat, int row, int col) {
/*Display the matrix for visualizatoin*/
for (int i = 0; i < row; ++i) {
for (int j = 0; j < col; ++j) {
cout << mat[i * col + j] << " ";
}cout << endl;
}
cout << "\n" << endl;
}
int main()
{
const int m = 3072, k = 3072, n = 64;
float* a = random_matrix(m, k);
float* b = random_matrix(k, n);
float* c = new float[m*n];
float* dev_a, *dev_b, *dev_c;
cudaMalloc((void**)&dev_a, m * k * sizeof(float));
cudaMalloc((void**)&dev_b, k * n * sizeof(float));
cudaMalloc((void**)&dev_c, m * n * sizeof(float));
cudaMemcpy(dev_a, a, m * k * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, k * n * sizeof(float), cudaMemcpyHostToDevice);
constexpr int BLOCK = 64;
dim3 grid((n + BLOCK - 1) / BLOCK, (m + 64 - 1) / 64);
int repeat = 1;
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
cudaEventQuery(start);
for (int i = 0; i < repeat; i++) {
sgemm_128x128x8 << <grid, 256 >> > (m, n, k, dev_a, dev_b, dev_c);
}
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float elapsed_time;
cudaEventElapsedTime(&elapsed_time, start, stop);
printf("Time = %g ms .\n", elapsed_time / repeat);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(c, dev_c, m * n * sizeof(float), cudaMemcpyDeviceToHost);
bool chk = check(a, b, c, m, n, k);
printf("Matrix_C check: %s\n", chk ? "OK" : "Failed");
//cout << 'a' << endl;
//print_mat(a, m, k);
//cout << 'b' << endl;
//print_mat(b, k, n);
//cout << 'c' << endl;
//print_mat(c, m, n);
}
you can take a look at this igemm example: https://github.com/NVIDIA/cutlass/blob/master/test/unit/gemm/threadblock/mma_pipelined_slicedk.cu#L42-L64 . We haven't added slicek support to sgemm, but the concepts are the same.
The shared memory load code is in https://github.com/NVIDIA/cutlass/blob/master/include/cutlass/gemm/warp/mma_simt_tile_iterator.h#L1433-L1884. Template PartitionsK controls the slice number.
This issue has been labeled inactive-30d due to no recent activity in the past 30 days. Please close this issue if no further response or action is needed. Otherwise, please respond with a comment indicating any updates or changes to the original issue and/or confirm this issue still needs to be addressed. This issue will be labeled inactive-90d if there is no activity in the next 60 days.