cutlass
 cutlass copied to clipboard
cutlass copied to clipboard
[RFE] Optimize the conv-fprop operator
Is your feature request related to a problem? Please describe.
When using the -conv-fprop of cutlass to perform the conv operation, it is found that in the entire kernel, the data transmission takes a long time and accounts for a large proportion. The performance of the entire kernel is poor, and the use of sm is not very good
q1: From the perspective of the entire kernel of about 1.2ms, the time-consuming (1.2ms) = data transfer/throughput, so that the entire kernel is transmitting data. Is that reasonable? Is the calculation of tensor core time-consuming, or is it overlapped by transmission?
q2: The L1 hit rate in the picture below is very low. Is this reasonable? If it's unreasonable, is it possible to improve the hit rate?
q3: From the point of view of instruction execution, there are many move instructions in epilogue-broadcast, is this reasonable? Can it be optimized?
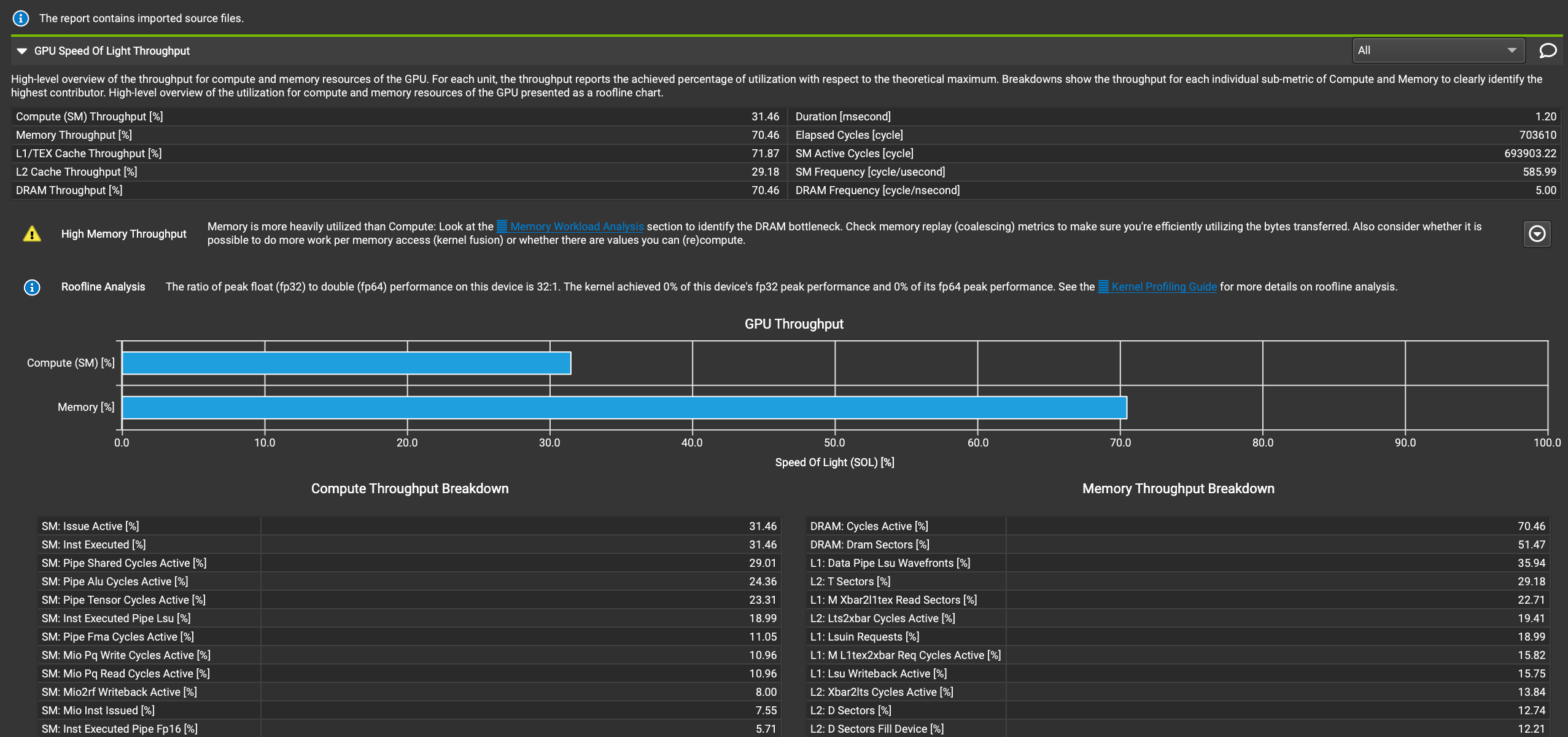
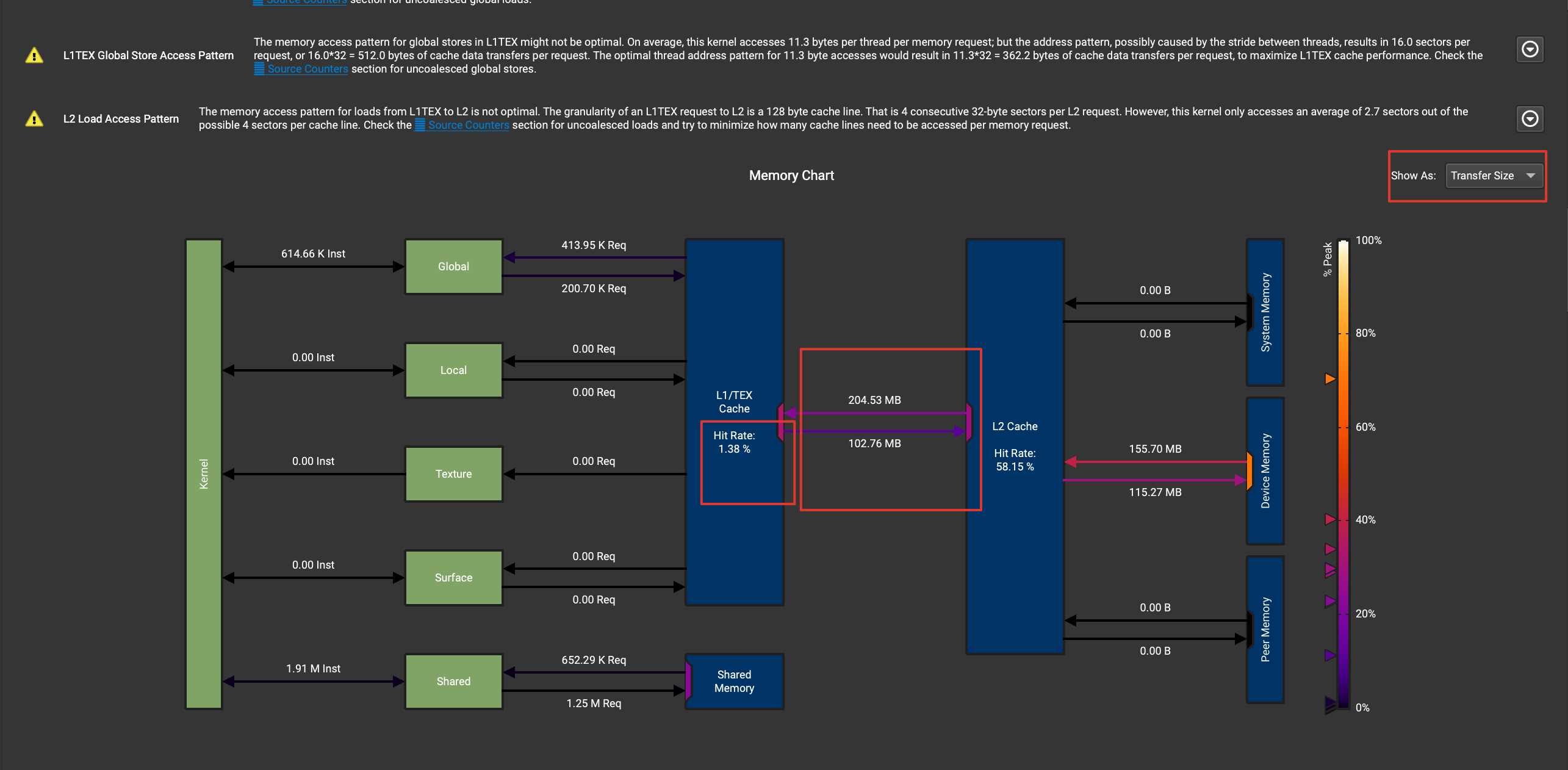
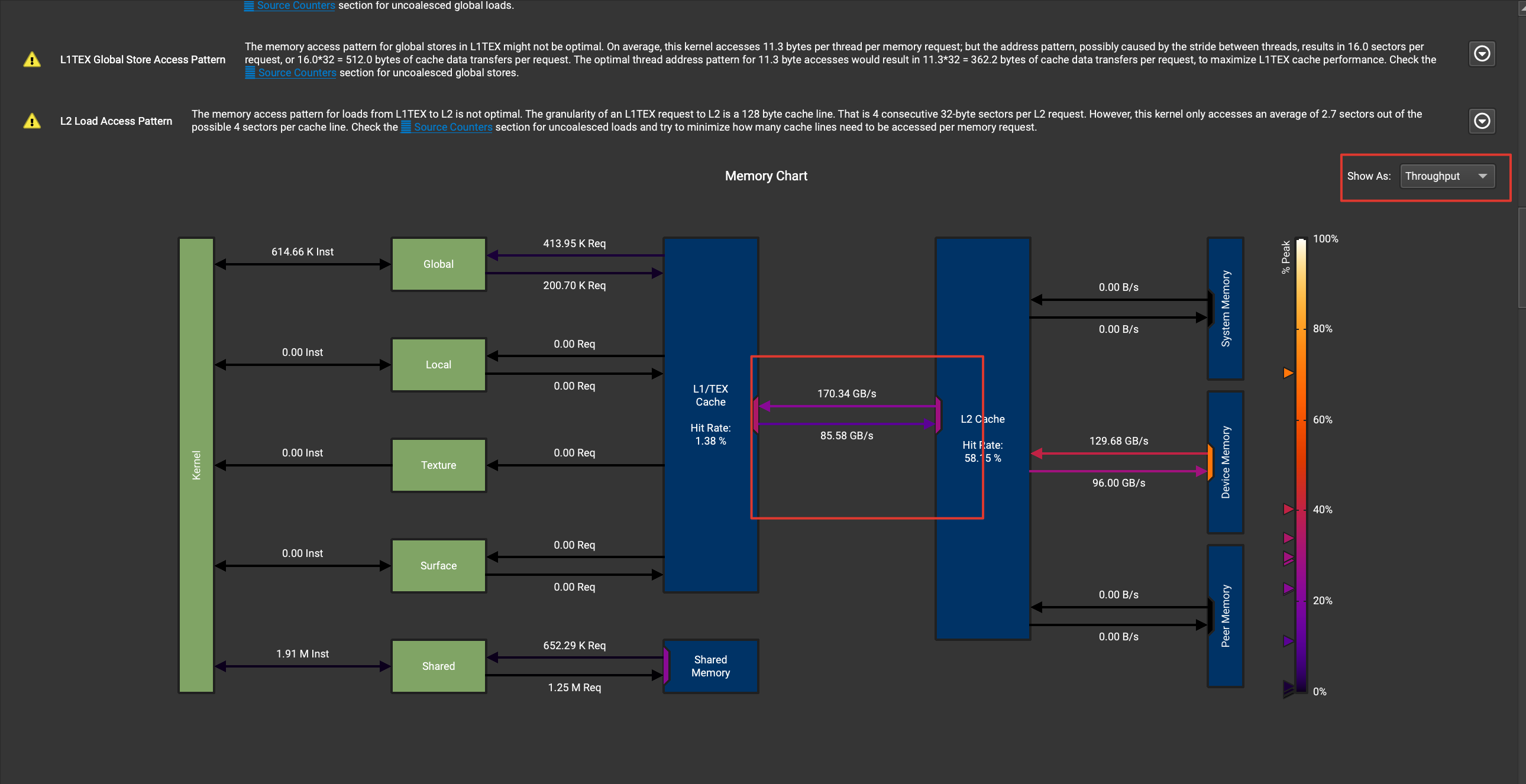
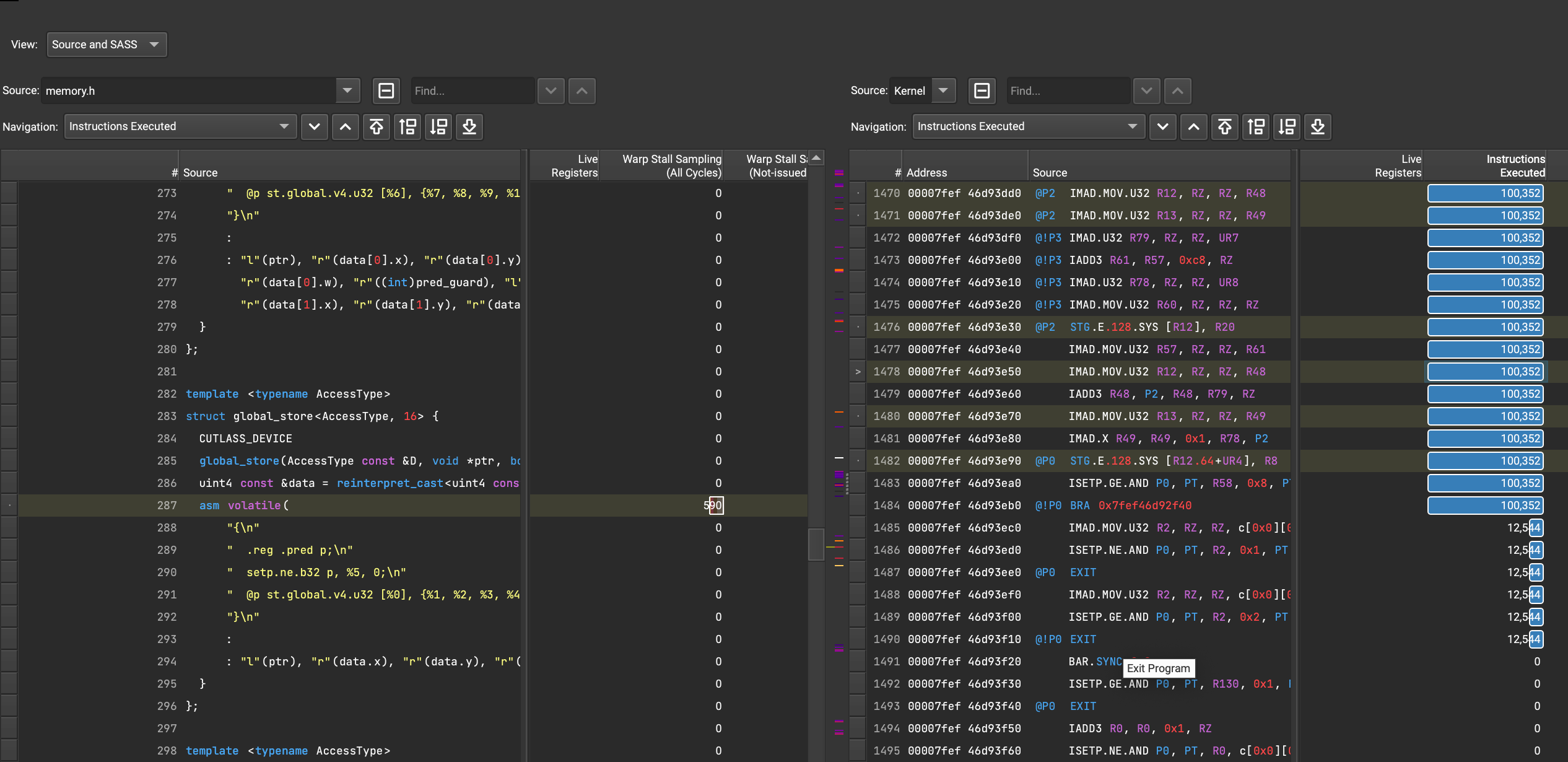
Describe the solution you'd like Can the kernel be further optimized? For example, to reduce the time-consuming of data transmission (such as reducing the amount of data transmission or increasing the transmission bandwidth)?
Additional context GPU:T4 input:N,H,W,C,P,Q,K,R,S,pad_h,stride_h,dilation_h,cost_time,64,56,56,64,56,56,256,1,1,0,1,1 code: using ElementAccumulator = cutlass::half_t, using ActivationOp = cutlass::epilogue:: thread ::Identity, using BinaryOp = cutlass::plus, using UnaryOp = cutlass::epilogue:: thread ::ReLu using ElementA = cutlass::half_t; using ElementB = cutlass::half_t; using ElementC = cutlass::half_t; using ElementD = ElementC; using ElementCompute = ElementAccumulator; using EpilogueOutputOp = cutlass::epilogue:: thread ::LinearCombinationResidualBlock< ElementD, ElementAccumulator, ElementCompute, ElementC, 8, ActivationOp, BinaryOp, UnaryOp> ; using Conv2dFpropKernel = typename cutlass::conv:: kernel ::DefaultConv2dFpropWithBroadcast< ElementA, cutlass::layout::TensorNHWC, ElementB, cutlass::layout::TensorNHWC, ElementC, cutlass::layout::TensorNHWC, ElementAccumulator, cutlass::arch::OpClassTensorOp, cutlass::arch::Sm75, cutlass::gemm::GemmShape<128, 128, 32>, cutlass::gemm::GemmShape<64, 64, 32>, cutlass::gemm::GemmShape<16, 8, 8>, EpilogueOutputOp, cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle<4>, 2, cutlass::arch::OpMultiplyAdd, cutlass::conv::IteratorAlgorithm::kOptimized, cutlass::conv::StrideSupport::kStrided, 8, 8>::Kernel; using Conv2dFprop = cutlass::conv::device::ImplicitGemmConvolution<Conv2dFpropKernel>;
Your RSC is 64 which means your kernel is completely memory bound and only needs 2 iterations of the mainloop. You can use cutlass profiler (https://github.com/NVIDIA/cutlass/blob/master/media/docs/profiler.md) to profile all available tile sizes to find the best one. (use -DCUTLASS_LIBRARY_KERNELS=h1688fprop in the cmake to enable all sm75 fprop tile sizes). 256x64 may be more useful to you than 128x128.
256x64 may be more useful to you than 128x128. I tested it and changed it to: cutlass::gemm::GemmShape<256, 64, 32>, cutlass::gemm::GemmShape<64, 64, 32>, cutlass::gemm::GemmShape<16, 8, 8>, but it got slower, now it takes 1.8ms to run
maybe you can also try threadblock size 128x64 and warp size 64x32. As I said earlier, this problem size is completely memory bound, Your performance data looks reasonable to me.
maybe you can also try threadblock size 128x64 and warp size 64x32. As I said earlier, this problem size is completely memory bound, Your performance data looks reasonable to me.
I use Driver Version: 440.33.01 CUDA Version: 10.2. I have tried the following combinations on the T4 card, and the performance data are not ideal. Is there any good way to optimize the kernel?

Your cuda is too old. I recommend to use 11.6+. See https://github.com/NVIDIA/cutlass/discussions/495
Again, your problem size is completely memory bound. Your perf is not bad.
Your cuda is too old. I recommend to use 11.6+. See #495
Again, your problem size is completely memory bound. Your perf is not bad.
Have you tested the performance of conv on cuda11.6+? What kind of performance data is it? For example, compared with cudnn
see https://github.com/NVIDIA/cutlass/blob/master/media/images/cutlass-2.9-implicit-gemm-performance.png
Ok, thanks, do you have the performance comparison data between the high version of cuda and cuda10.2? If only the driver version is upgraded, but the cuda version is not upgraded, will there be a performance improvement?
do you have the performance comparison data between the high version of cuda and cuda10.2?
roughly 10%, but again yours is compute bound. better codegen cannot help much.
If only the driver version is upgraded, but the cuda version is not upgraded, will there be a performance improvement?
i think you cannot launch kernel if cuda version and driver version are very different.
roughly 10%, but again yours is compute bound. better codegen cannot help much.
The conv performance is good on the new cuda version. Did you optimize the conv implementation, or did you improve the cuda version simply? If the conv implementation is optimized, can these optimizations be migrated to the old version?
This issue has been labeled inactive-30d due to no recent activity in the past 30 days. Please close this issue if no further response or action is needed. Otherwise, please respond with a comment indicating any updates or changes to the original issue and/or confirm this issue still needs to be addressed. This issue will be labeled inactive-90d if there is no activity in the next 60 days.