[QST] How slice K reduce the value?
Hi! I am learning 'tall' matmul and find it hard to find the code describing how slice K reduce the value.... I think, each wrap will calculate 32*64 values (each thread cal 64 values) and then....we want to reduce between different wraps? So we can not use wrap_sync function like shlf_down_sync? We will use atomicAdd to global memory?
Thank you!!!
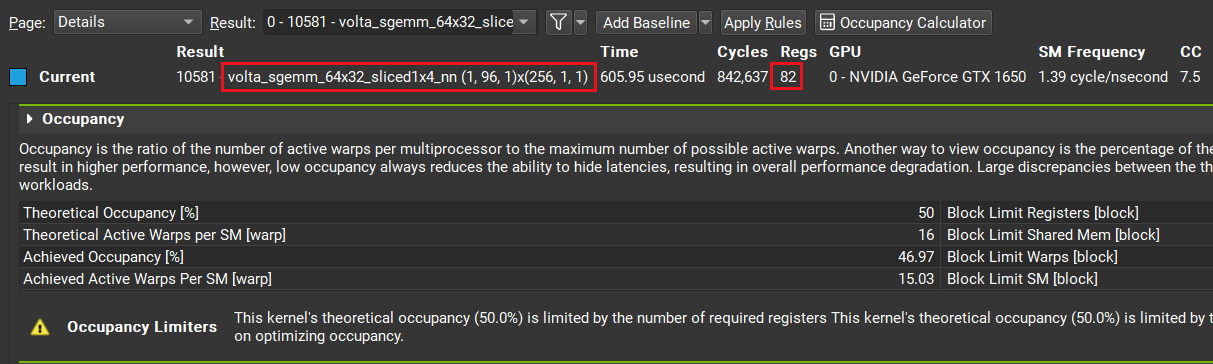
Haha, actually I am guessing how cublas works using nsight compute, and I am calculating 3072 * 3072 3072 * 64 => 3072 * 64 matmul, and see this in nsight: volta_sgemm_64x32_sliced1x4_nn(1, 96, 1)x(256, 1, 1). Do you have any idea what sliced1x4 means? I only see this 1x4 in cutlass.....
Also, what do you think nn is?
Thank you!!!!
we want to reduce between different wraps?
Correct.
So we can not use wrap_sync function like shlf_down_sync? We will use atomicAdd to global memory?
We reduce between warps. We don't use atomic or global memory, but we use shared memory. The code is here.
Do you have any idea what sliced1x4 means?
Each threadblock tile will be splited into 4 parts along the K dimension. Every warp will take care of one part. They will be reduced finally in the epilogue. Here is a cutlass example. It splits K dimension into 2 parts because ThreadBlockShape::kK / WarpShape::kK = 64 / 32 = 2
Also, what do you think nn is
n means non-transposed which is column major. This is cuBlas Terminology. nn means both multiplicands are column major.
we want to reduce between different wraps?
Correct.
So we can not use wrap_sync function like shlf_down_sync? We will use atomicAdd to global memory?
We reduce between warps. We don't use atomic or global memory, but we use shared memory. The code is here.
Do you have any idea what sliced1x4 means?
Each threadblock tile will be splited into 4 parts along the
Kdimension. Every warp will take care of one part. They will be reduced finally in the epilogue. Here is a cutlass example. It splitsKdimension into 2 parts becauseThreadBlockShape::kK / WarpShape::kK = 64 / 32 = 2Also, what do you think nn is
n means non-transposed which is column major. This is cuBlas Terminology. nn means both multiplicands are column major.
Yes, thank you very much! And just one smalllll question,
Each threadblock tile will be splited into 4 parts along the K dimension. Every warp will take care of one part.
so you mentioned sliced1x4 means slice 4 parts, I agree. And cublas here actually uses 256 threads, which is 8 warps, so I think here actually two warps will take care of one part~of size 32 * 8(A) and 8 * 64(B).
Thank you!!!
(By the way, according to my experience, 32 * 4 and 4 * 64 might be better? Two warps one part? I even doubt my conclusion now..)
using Gemm = cutlass::gemm::device::Gemm< cutlass::half_t, cutlass::layout::ColumnMajor, cutlass::half_t, cutlass::layout::RowMajor, ElementOutput, cutlass::layout::RowMajor, ElementAccumulator, cutlass::arch::OpClassTensorOp, cutlass::arch::Sm75, cutlass::gemm::GemmShape<64, 64, 64>, cutlass::gemm::GemmShape<64, 32, 32>, cutlass::gemm::GemmShape<16, 8, 8>, cutlass::epilogue::thread::LinearCombination< ElementOutput, 64 / cutlass::sizeof_bits<ElementOutput>::value, ElementAccumulator, ElementAccumulator >, cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle<>, 2>;
I see this in your provided link and curious about its size and meaning here: cutlass::gemm::GemmShape<64, 64, 64>, cutlass::gemm::GemmShape<64, 32, 32>, cutlass::gemm::GemmShape<16, 8, 8>, So each threadBlock will calculate how large? Read how much from A and B?
Thank you!!!!
@Arsmart123, I think you would benefit greatly from some of the CUTLASS sessions that have been presented at GTC. CUTLASS: Software Primitives for Dense Linear Algebra at All Levels and Scales within CUDA Developing CUDA Kernels to Push Tensor Cores to the Absolute Limit on NVIDIA A100 Accelerating Backward Data Gradient by Increasing Tensor Core Utilization in CUTLASS Accelerating Convolution with Tensor Cores in CUTLASS
Thank you!! One last question, how we choose splitK or sliceK? They cope with a same problem (large K) using different policy?
Actually I am implementing this volta_sgemm_64x32_sliced1x4_nn(1, 96, 1)x(256, 1, 1), and one block will calculate 32 * 64, 8 warps, two warps calculate 32 * 64, each thread calculate 32 values and read 8 B's values and 4 A's values......It is very slow....I doubt it read too much value but calculate too less, previously with 64 calculate and 8 (=4A and 4B) works well....
Thank you!! I am tortured by this for months....
splitK is for large K and small M/N. It is used to saturate GPU.
sliceK is used to reduce the shared memory traffic when the tile size is small.
splitK is for large K and small M/N. It is used to saturate GPU.
sliceK is used to reduce the shared memory traffic when the tile size is small.
Could you help me explain "sliceK is used to reduce the shared memory traffic when the tile size is small", what is ”shared memory traffic“? thanks a lot.
what is ”shared memory traffic“?
loading and storing from/to the shared memory.
This issue has been labeled inactive-30d due to no recent activity in the past 30 days. Please close this issue if no further response or action is needed. Otherwise, please respond with a comment indicating any updates or changes to the original issue and/or confirm this issue still needs to be addressed. This issue will be labeled inactive-90d if there is no activity in the next 60 days.