[QST] 2 GEMM fused result error
Also for this case. I try to use some other parameter to verity the result, such as
cutlass::gemm::GemmCoord gemm_f16_sm75_problem_size_0(10, 64, 576); cutlass::gemm::GemmCoord gemm_f16_sm75_problem_size_1(10, 128, 64);
it run ok, and pass the test.
However for this config
cutlass::gemm::GemmCoord gemm_f16_sm75_problem_size_0(10, 256, 768); cutlass::gemm::GemmCoord gemm_f16_sm75_problem_size_1(10, 128, 256);
it can run but the result failed as in line.
I want to know how to debug this configure and does it have some implicit parameter which has to tuned for each case?
@lw921014 could you please post the thread block and warp tile sizes? In case you haven't tried it, please sanity check if the following requirements are met: problem_N = threadblock_N = warp_N
@lw921014 could you please post the thread block and warp tile sizes? In case you haven't tried it, please sanity check if the following requirements are met: problem_N = threadblock_N = warp_N
Thanks a lot. I know this requirent problem_N = threadblock_N = warp_N. My question is that both problem 1 and problem 2 shoud meet it at the same time? I mean problem0_N = threadblock0_N = warp0_N and problem1_N = threadblock1_N = warp1_N?
problem0_N = threadblock0_N = warp0_N problem1_N = threadblock1_N = warp1_N
problem0_N doesn't have to be the same as problem1_N. It is only required that problem0_N = problem1_K.
Correct. For this group parameter, we satisfied problem0_N = threadblock0_N = warp0_N and problem1_N = threadblock1_N = warp1_N, but still failed.
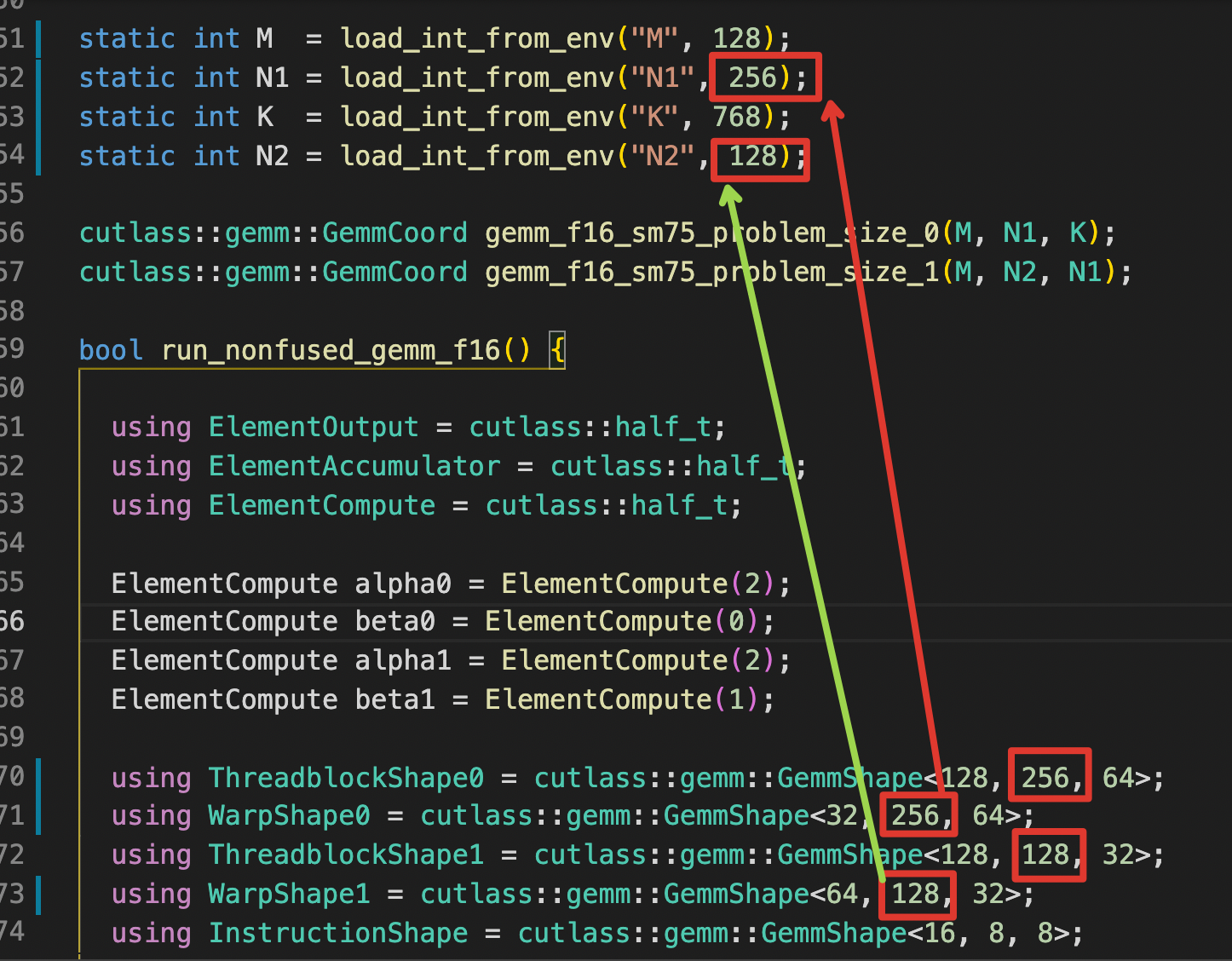
You'll need the same number of warps for each GEMM.
In your example above, you use 4 warps for the 1st GEMM, but use 2 warps for the 2nd GEMM.
You'll need the same number of warps for each GEMM.
In your example above, you use 4 warps for the 1st GEMM, but use 2 warps for the 2nd GEMM.
I change this parameter to ensure each has same 4 warps. however failed.
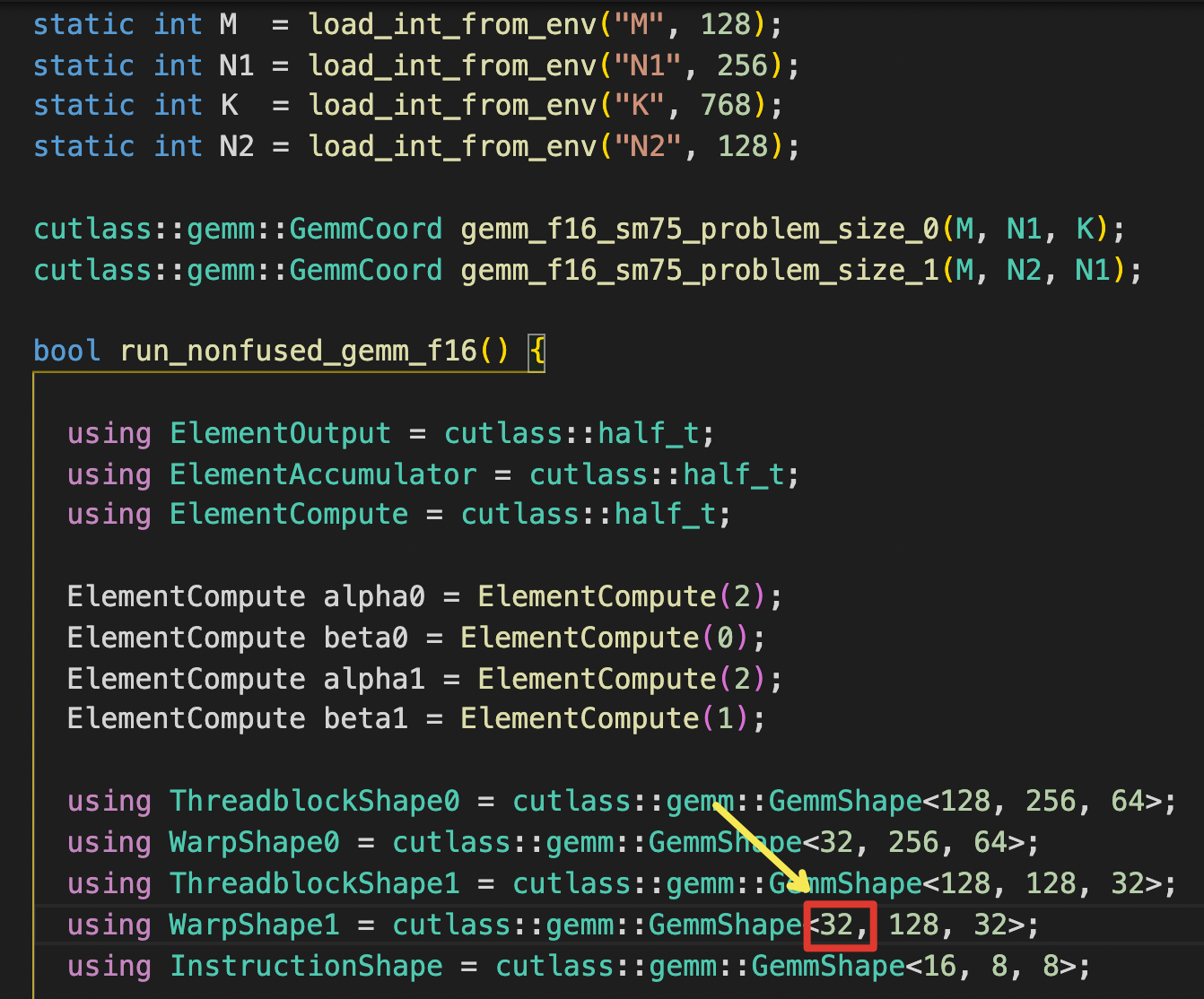
Your code snap shows the function run_nonfused_gemm_f16(). Did you also change the tile sizes for run_fused_gemm_f16()?
Here is a combination that works for me:
using ThreadblockShape0 = cutlass::gemm::GemmShape<64, 256, 32>; using WarpShape0 = cutlass::gemm::GemmShape<16, 256, 32>; using ThreadblockShape1 = cutlass::gemm::GemmShape<64, 128, 32>; using WarpShape1 = cutlass::gemm::GemmShape<16, 128, 32>; using InstructionShape = cutlass::gemm::GemmShape<16, 8, 8>;
Note that this may not be performant compared with non-fused case due to small warp_M=16. Also the large warp_N=256 causes RF spill.
I change as this it run ok.
Note that this may not be performant compared with non-fused case due to small warp_M=16. Also the large warp_N=256 causes RF spill.
warp_N must be same as problem n. So for problem size which has a large n, do non-fused always better than fused? If not, can you give some advice to tuning the performance?
warp_N must be the same as problem_N
It is true for this example since we need the input A matrix of 2nd GEMM to be RF-resident, and each warp computes one warp tile with the entire input B matrix. You may reduce the warp1_N, e.g. warp1_N = 1/2 problem_N, but you'll need to change warp tile mapping so each warp computes two warp tiles at the N dimension.
The other solution is to use shared memory staging for the output of 1st GEMM so warp_N restriction can be relaxed. We will add an example in the future.
Also along the lines, you may hit shared memory size limit for large threadblock_N. On Turing, shared memory size is 64KB. Using threadblock size (64,256,32) as an example, you'll need (64x32+256x32)x(2 stages)x(2 bytes for fp16) = 40KB. If you increase threadblock_N, you will have to reduce threadblock_M or threadblock_K to reduce shared memory usage, which can lead to performance inefficiency.
Also along the lines, you may hit shared memory size limit for large threadblock_N. On Turing, shared memory size is 64KB. Using threadblock size (64,256,32) as an example, you'll need (64x32+256x32)x(2 stages)x(2 bytes for fp16) = 40KB. If you increase threadblock_N, you will have to reduce threadblock_M or threadblock_K to reduce shared memory usage, which can lead to performance inefficiency.
ok. Thanks a lot.
The other solution is to use shared memory staging for the output of 1st GEMM so warp_N restriction can be relaxed. We will add an example in the future.
You mean in 2.9?
@jwang323 I find another question about the result, for the problem size 0 (M = 1, N = 256, K = 64) and problem size 1 (M = 1, N = 128, K = 256), I run this example without change any parameters, the result is correct.
However, when I use same problem size and change the A0, B0, C0, B1, C1 and fill them with all 0.1, and set the alpha0, alpha1, beta0, beta1 as all 1, then result show check failed. The data in [error_B2bGemm_device_fused.txt] shown as
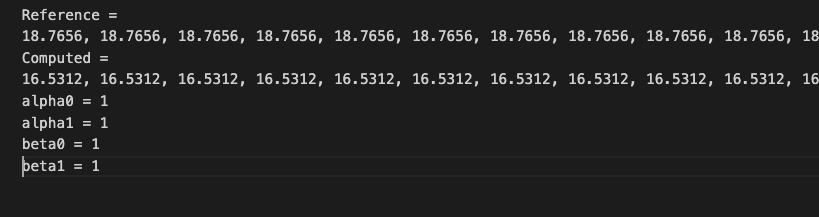 . Is this a bug?
. Is this a bug?
I find in this line, EpilogueOutputOp0 is seted as cutlass::epilogue::thread::ScaleType::OnlyAlphaScaling, does this ingore beta? And do we have some method to suport this case which C is a vector?
I find in this line, EpilogueOutputOp0 is seted as
cutlass::epilogue::thread::ScaleType::OnlyAlphaScaling, does this ingore beta?
Yes cutlass::epilogue::thread::ScaleType::OnlyAlphaScaling only applies to epilogue with beta=0. If you have both alpha and beta, you'll need to set to set scale type to cutlass::epilogue::thread::ScaleType::Default, or cutlass::epilogue::thread::ScaleType::NoBetaScaling since your beta=1.
See https://github.com/NVIDIA/cutlass/blob/master/include/cutlass/epilogue/thread/scale_type.h#L44
And do we have some method to suport this case which C is a vector?
Yes C can be treated as a vector if the stride is set to 0. You can check this example: https://github.com/NVIDIA/cutlass/blob/master/examples/17_fprop_per_channel_bias/fprop_per_channel_bias.cu#L188
es
cutlass::epilogue::thread::ScaleType::OnlyAlphaScalingonly applies to epilogue with beta=0. If you have both alpha and beta, you'll need to set to set scale type tocutlass::epilogue::thread::ScaleType::Default, orcutlass::epilogue::thread::ScaleType::NoBetaScaling
when i set cutlass::epilogue::thread::ScaleType::Default as follow
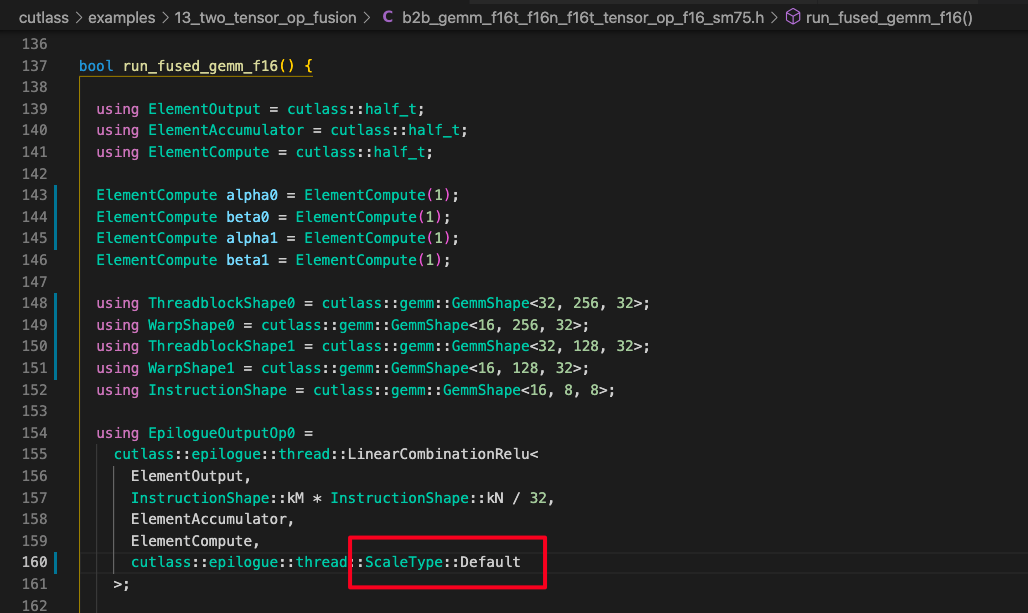 it trigger this error
it trigger this error
 I trace it as follow code, Does it meas beta must be 0?
I trace it as follow code, Does it meas beta must be 0?
ok. beta0 must be 0 is a hard requirent? I mean it is a basic requirent for fused or beta can be set any value in future release(2.9)?
We haven't implemented it.
Is it possible in principle?Or only because may sacifice performance in current rf-resident mode?
It is doable, just we haven't done it yet. Do you want to add a mxn matrix or a per channel bias vector?
doable
Perfect. We need both mode. In fact, from view of upper application, mxn matrix can cover bias vector case, because you can broadcast bias vector in channel axis to obtain a mxn. So I think if we support adding a mxn matrix, we naturally support adding a vector. Of course, if we support both mode, it is best.
We haven't implemented it.
To be honestly, we hope you can support it soon, becase we can not ingnore this bias(c matix) in our real cases.
This issue has been labeled inactive-30d due to no recent activity in the past 30 days. Please close this issue if no further response or action is needed. Otherwise, please respond with a comment indicating any updates or changes to the original issue and/or confirm this issue still needs to be addressed. This issue will be labeled inactive-90d if there is no activity in the next 60 days.