[FEA] On-demand size computation to solve #65 and #39
In order to support fully asynchronous bulk operations, e.g., for multi-GPU hash tables, as requested in #65, we need to rethink the way we compute the table's size.
For now, insert tracks the number of successful insertions on-the-fly. After the kernel has finished, we copy the number back to the host and add it to the size_ member. This implies that insert synchronizes with the host.
In order to overcome this limitation for cuco::static_reduction_map (PR #98), 902b93a proposes a standalone size computation based on thrust::count_if and also implements fully asynchronous bulk operations.
The size computation using thrust::count_if shows near SOL performance in terms of throughput.
Additionally, since we do not need to reduce the number of added pairs during insertion, the overall performance of the insert bulk operation improves by ~3-5%.
IMHO we should also add this feature to the other hash table implementations.
This feature also implicitly solves issue #39.
Can you benchmark doing a insert() followed by size() with both approaches?
Benchmark setup:
- Tesla V100 SXM2
- Insert 10^8 distinct 4+4 byte key/value pairs
- Baseline is the old
insert(), i.e., with implicit size computation - Comparison against new
insert(), i.e., without size computation as well asinsert()+size()to emulate the behaviour of the baseline version. - Graph below shows speedup/speedown over varying target load factors
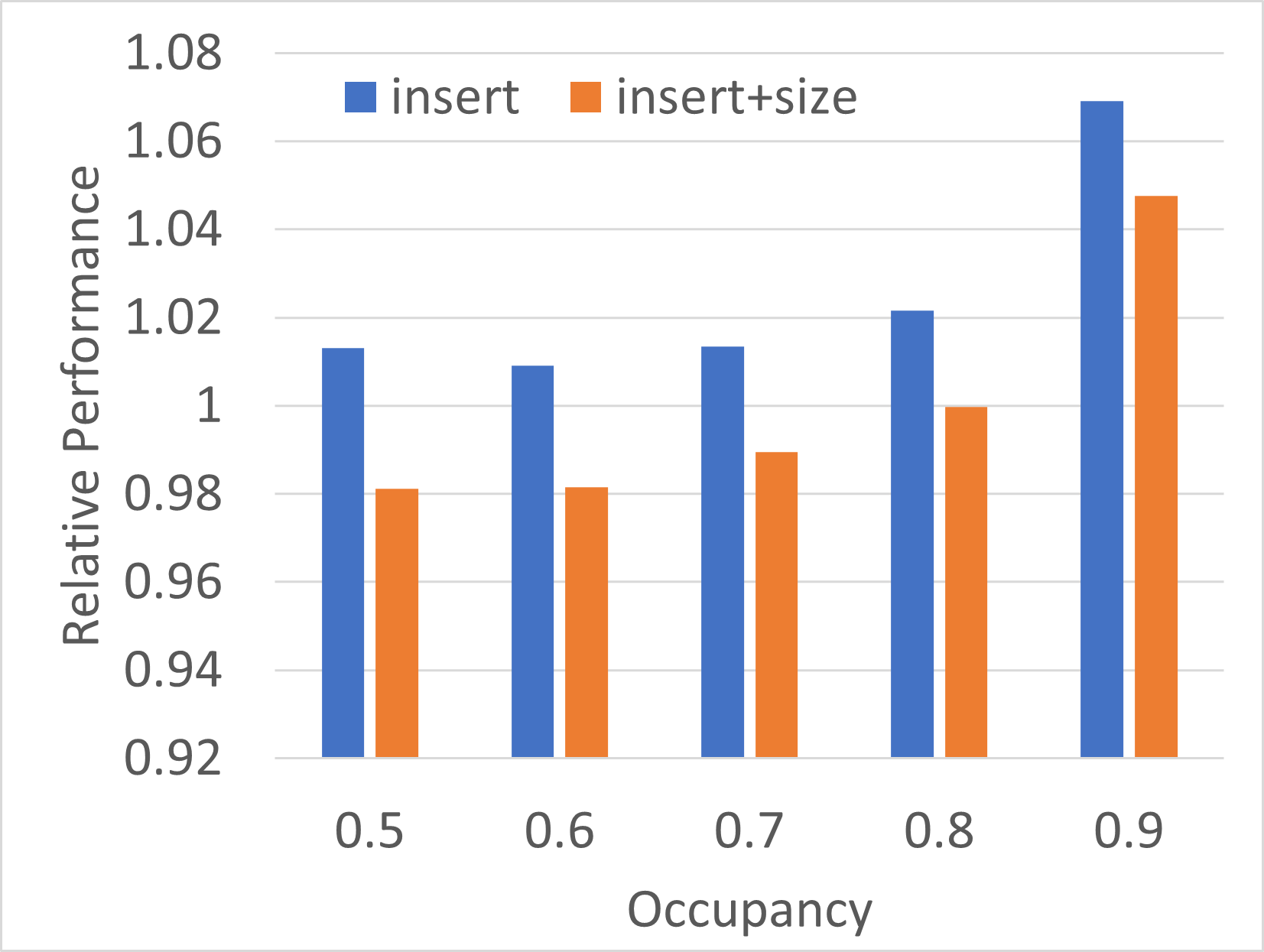
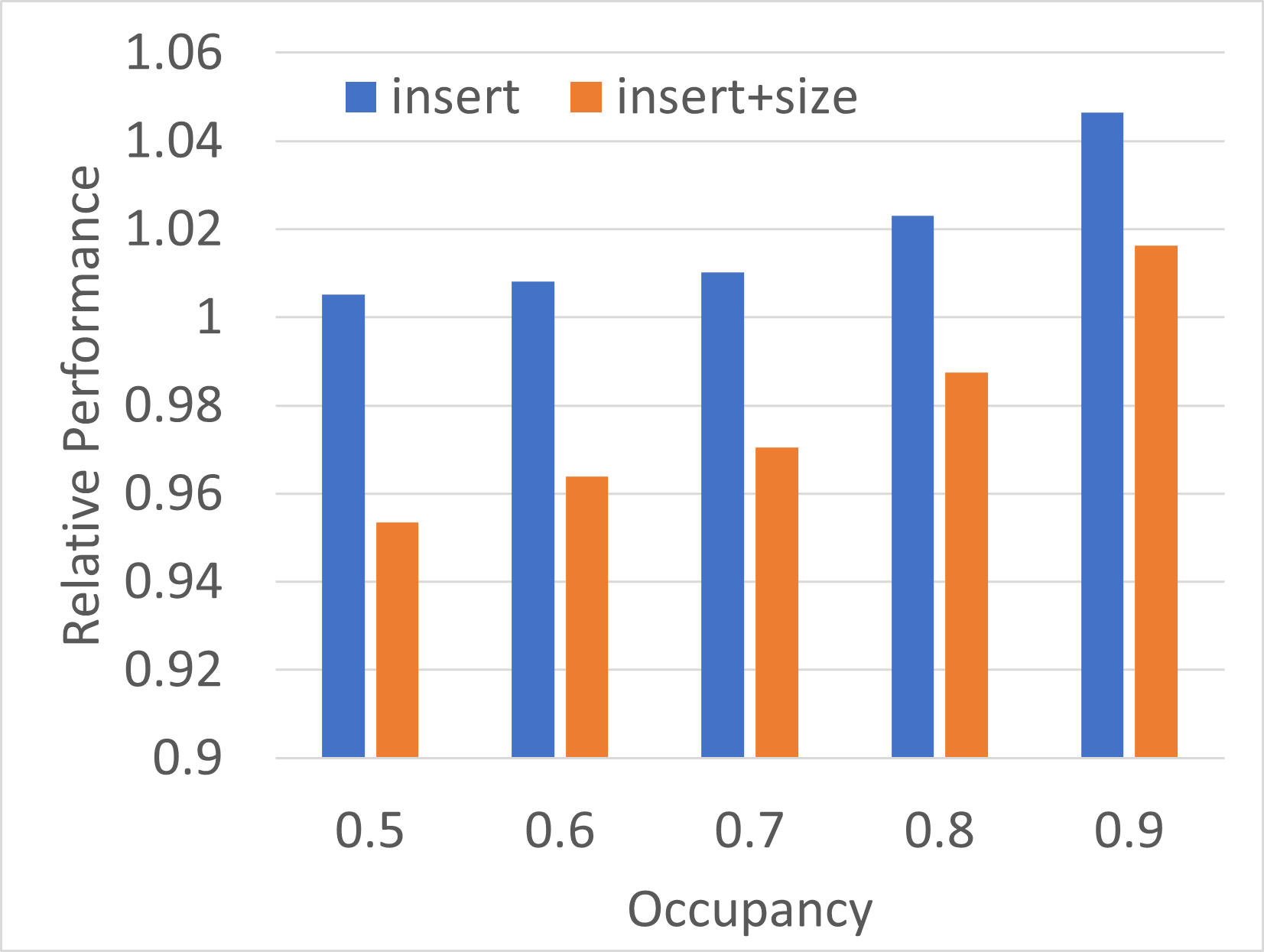
I'm not quite sure why the performance of the standalone size() is slightly worse compared to 4+4 byte pairs.
Maybe my approach of converting a slot into a thrust::tuple to be fed into the thrust::count_if predicate is not neccessary:
https://github.com/sleeepyjack/cuCollections/blob/902b93a64c3c07fbc0108bdba56b2bbc6e1f9b55/include/cuco/detail/static_reduction_map.inl#L188
We could also use cud::DeviceReduce::Reduce with an iterator over the key fields in all slots.