TensorRT
 TensorRT copied to clipboard
TensorRT copied to clipboard
(Could not find any implementation for node {ForeignNode[Transpose_2713 + (Unnamed Layer* 4032) [Shuffle]...MatMul_2714]}.)
Hi, I am trying to convert an Onnx model with dynamic inputs to TensorRT format but encounter an error about "Could not find any implementation for node...". Can someone please assist with understanding this error message? Here is the model https://drive.google.com/file/d/12eL6eHxSepDz98GsOleQNe8I9qY8TU7s/view?usp=sharing.
This is my error message.
[07/05/2022-11:59:43] [W] [TRT] (# 1 (RESHAPE (# 0 (SHAPE pkv_44)) 16 2 64 | (* 16 (# 0 (SHAPE input_ids))) -1 64 zeroIsPlaceholder))
[07/05/2022-11:59:43] [W] [TRT] Skipping tactic 0x0000000000000000 due to Myelin error: Incompatible shapes in fully-connected op between: attn_weights_179':f32,trA=false,[128,1,2] and onnx__MatMul_2931':f32,trB=false,[128,8,64].
[07/05/2022-11:59:43] [V] [TRT] Fastest Tactic: 0xd15ea5edd15ea5ed Time: inf
[07/05/2022-11:59:43] [V] [TRT] Deleting timing cache: 186 entries, served 7244 hits since creation.
[07/05/2022-11:59:43] [E] Error[10]: [optimizer.cpp::computeCosts::3628] Error Code 10: Internal Error (Could not find any implementation for node {ForeignNode[Transpose_2713 + (Unnamed Layer* 4032) [Shuffle]...MatMul_2714]}.)
[07/05/2022-11:59:43] [E] Error[2]: [builder.cpp::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
[07/05/2022-11:59:43] [E] Engine could not be created from network
This is my trtexec command.
trtexec --onnx=m2m100_418M-decoder.onnx --verbose --minShapes=input_ids:5x1,encoder_attention_mask:5x1,pkv_0:5x16x1x64,pkv_1:5x16x1x64,pkv_2:5x16x1x64,pkv_3:5x16x1x64,pkv_4:5x16x1x64,pkv_5:5x16x1x64,pkv_6:5x16x1x64,pkv_7:5x16x1x64,pkv_8:5x16x1x64,pkv_9:5x16x1x64,pkv_10:5x16x1x64,pkv_11:5x16x1x64,pkv_12:5x16x1x64,pkv_13:5x16x1x64,pkv_14:5x16x1x64,pkv_15:5x16x1x64,pkv_16:5x16x1x64,pkv_17:5x16x1x64,pkv_18:5x16x1x64,pkv_19:5x16x1x64,pkv_20:5x16x1x64,pkv_21:5x16x1x64,pkv_22:5x16x1x64,pkv_23:5x16x1x64,pkv_24:5x16x1x64,pkv_25:5x16x1x64,pkv_26:5x16x1x64,pkv_27:5x16x1x64,pkv_28:5x16x1x64,pkv_29:5x16x1x64,pkv_30:5x16x1x64,pkv_31:5x16x1x64,pkv_32:5x16x1x64,pkv_33:5x16x1x64,pkv_34:5x16x1x64,pkv_35:5x16x1x64,pkv_36:5x16x1x64,pkv_37:5x16x1x64,pkv_38:5x16x1x64,pkv_39:5x16x1x64,pkv_40:5x16x1x64,pkv_41:5x16x1x64,pkv_42:5x16x1x64,pkv_43:5x16x1x64,pkv_44:5x16x1x64,pkv_45:5x16x1x64,pkv_46:5x16x1x64,pkv_47:5x16x1x64 --optShapes=input_ids:5x1,encoder_attention_mask:5x100,pkv_0:5x16x1x64,pkv_1:5x16x1x64,pkv_2:5x16x1x64,pkv_3:5x16x1x64,pkv_4:5x16x1x64,pkv_5:5x16x1x64,pkv_6:5x16x1x64,pkv_7:5x16x1x64,pkv_8:5x16x1x64,pkv_9:5x16x1x64,pkv_10:5x16x1x64,pkv_11:5x16x1x64,pkv_12:5x16x1x64,pkv_13:5x16x1x64,pkv_14:5x16x1x64,pkv_15:5x16x1x64,pkv_16:5x16x1x64,pkv_17:5x16x1x64,pkv_18:5x16x1x64,pkv_19:5x16x1x64,pkv_20:5x16x1x64,pkv_21:5x16x1x64,pkv_22:5x16x1x64,pkv_23:5x16x1x64,pkv_24:5x16x1x64,pkv_25:5x16x1x64,pkv_26:5x16x1x64,pkv_27:5x16x1x64,pkv_28:5x16x1x64,pkv_29:5x16x1x64,pkv_30:5x16x1x64,pkv_31:5x16x1x64,pkv_32:5x16x1x64,pkv_33:5x16x1x64,pkv_34:5x16x1x64,pkv_35:5x16x1x64,pkv_36:5x16x1x64,pkv_37:5x16x1x64,pkv_38:5x16x1x64,pkv_39:5x16x1x64,pkv_40:5x16x1x64,pkv_41:5x16x1x64,pkv_42:5x16x1x64,pkv_43:5x16x1x64,pkv_44:5x16x1x64,pkv_45:5x16x1x64,pkv_46:5x16x1x64,pkv_47:5x16x1x64 --maxShapes=input_ids:80x1,encoder_attention_mask:80x200,pkv_0:80x16x1x64,pkv_1:80x16x1x64,pkv_2:80x16x1x64,pkv_3:80x16x1x64,pkv_4:80x16x1x64,pkv_5:80x16x1x64,pkv_6:80x16x1x64,pkv_7:80x16x1x64,pkv_8:80x16x1x64,pkv_9:80x16x1x64,pkv_10:80x16x1x64,pkv_11:80x16x1x64,pkv_12:80x16x1x64,pkv_13:80x16x1x64,pkv_14:80x16x1x64,pkv_15:80x16x1x64,pkv_16:80x16x1x64,pkv_17:80x16x1x64,pkv_18:80x16x1x64,pkv_19:80x16x1x64,pkv_20:80x16x1x64,pkv_21:80x16x1x64,pkv_22:80x16x1x64,pkv_23:80x16x1x64,pkv_24:80x16x1x64,pkv_25:80x16x1x64,pkv_26:80x16x1x64,pkv_27:80x16x1x64,pkv_28:80x16x1x64,pkv_29:80x16x1x64,pkv_30:80x16x1x64,pkv_31:80x16x1x64,pkv_32:80x16x1x64,pkv_33:80x16x1x64,pkv_34:80x16x1x64,pkv_35:80x16x1x64,pkv_36:80x16x1x64,pkv_37:80x16x1x64,pkv_38:80x16x1x64,pkv_39:80x16x1x64,pkv_40:80x16x1x64,pkv_41:80x16x1x64,pkv_42:80x16x1x64,pkv_43:80x16x1x64,pkv_44:80x16x1x64,pkv_45:80x16x1x64,pkv_46:80x16x1x64,pkv_47:80x16x1x64 --shapes=input_ids:5x1,encoder_attention_mask:5x100,pkv_0:5x16x1x64,pkv_1:5x16x1x64,pkv_2:5x16x1x64,pkv_3:5x16x1x64,pkv_4:5x16x1x64,pkv_5:5x16x1x64,pkv_6:5x16x1x64,pkv_7:5x16x1x64,pkv_8:5x16x1x64,pkv_9:5x16x1x64,pkv_10:5x16x1x64,pkv_11:5x16x1x64,pkv_12:5x16x1x64,pkv_13:5x16x1x64,pkv_14:5x16x1x64,pkv_15:5x16x1x64,pkv_16:5x16x1x64,pkv_17:5x16x1x64,pkv_18:5x16x1x64,pkv_19:5x16x1x64,pkv_20:5x16x1x64,pkv_21:5x16x1x64,pkv_22:5x16x1x64,pkv_23:5x16x1x64,pkv_24:5x16x1x64,pkv_25:5x16x1x64,pkv_26:5x16x1x64,pkv_27:5x16x1x64,pkv_28:5x16x1x64,pkv_29:5x16x1x64,pkv_30:5x16x1x64,pkv_31:5x16x1x64,pkv_32:5x16x1x64,pkv_33:5x16x1x64,pkv_34:5x16x1x64,pkv_35:5x16x1x64,pkv_36:5x16x1x64,pkv_37:5x16x1x64,pkv_38:5x16x1x64,pkv_39:5x16x1x64,pkv_40:5x16x1x64,pkv_41:5x16x1x64,pkv_42:5x16x1x64,pkv_43:5x16x1x64,pkv_44:5x16x1x64,pkv_45:5x16x1x64,pkv_46:5x16x1x64,pkv_47:5x16x1x64
These are my specs: cuda: 11.3 pytorch: 1.11.0 nvidia-tensorrt: 8.4.1.5 onnx: 1.9.0
I really appreciate the help.
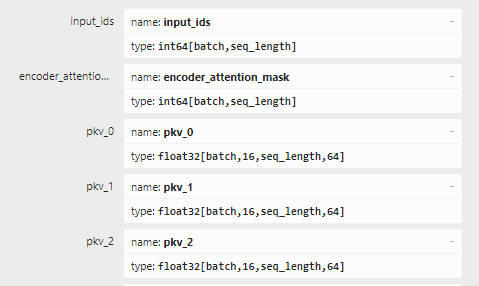
The input shapes of the input_ids and encoder_attention_mask are both [batch,seq_length] in your ONNX model, but the optShapes you provide has different seq_length between the two inputs. Could you re-export the ONNX and make sure the two dimensions have different names?
Thank you, I have changed the --opt-length flag in the trtexec command as below
trtexec --onnx=m2m100_418M-decoder.onnx --verbose --minShapes=input_ids:5x1,encoder_attention_mask:5x1,pkv_0:5x16x1x64,pkv_1:5x16x1x64,pkv_2:5x16x1x64,pkv_3:5x16x1x64,pkv_4:5x16x1x64,pkv_5:5x16x1x64,pkv_6:5x16x1x64,pkv_7:5x16x1x64,pkv_8:5x16x1x64,pkv_9:5x16x1x64,pkv_10:5x16x1x64,pkv_11:5x16x1x64,pkv_12:5x16x1x64,pkv_13:5x16x1x64,pkv_14:5x16x1x64,pkv_15:5x16x1x64,pkv_16:5x16x1x64,pkv_17:5x16x1x64,pkv_18:5x16x1x64,pkv_19:5x16x1x64,pkv_20:5x16x1x64,pkv_21:5x16x1x64,pkv_22:5x16x1x64,pkv_23:5x16x1x64,pkv_24:5x16x1x64,pkv_25:5x16x1x64,pkv_26:5x16x1x64,pkv_27:5x16x1x64,pkv_28:5x16x1x64,pkv_29:5x16x1x64,pkv_30:5x16x1x64,pkv_31:5x16x1x64,pkv_32:5x16x1x64,pkv_33:5x16x1x64,pkv_34:5x16x1x64,pkv_35:5x16x1x64,pkv_36:5x16x1x64,pkv_37:5x16x1x64,pkv_38:5x16x1x64,pkv_39:5x16x1x64,pkv_40:5x16x1x64,pkv_41:5x16x1x64,pkv_42:5x16x1x64,pkv_43:5x16x1x64,pkv_44:5x16x1x64,pkv_45:5x16x1x64,pkv_46:5x16x1x64,pkv_47:5x16x1x64 --optShapes=input_ids:5x100,encoder_attention_mask:5x100,pkv_0:5x16x100x64,pkv_1:5x16x100x64,pkv_2:5x16x100x64,pkv_3:5x16x100x64,pkv_4:5x16x100x64,pkv_5:5x16x100x64,pkv_6:5x16x100x64,pkv_7:5x16x100x64,pkv_8:5x16x100x64,pkv_9:5x16x100x64,pkv_10:5x16x100x64,pkv_11:5x16x100x64,pkv_12:5x16x100x64,pkv_13:5x16x100x64,pkv_14:5x16x100x64,pkv_15:5x16x100x64,pkv_16:5x16x100x64,pkv_17:5x16x100x64,pkv_18:5x16x100x64,pkv_19:5x16x100x64,pkv_20:5x16x100x64,pkv_21:5x16x100x64,pkv_22:5x16x100x64,pkv_23:5x16x100x64,pkv_24:5x16x100x64,pkv_25:5x16x100x64,pkv_26:5x16x100x64,pkv_27:5x16x100x64,pkv_28:5x16x100x64,pkv_29:5x16x100x64,pkv_30:5x16x100x64,pkv_31:5x16x100x64,pkv_32:5x16x100x64,pkv_33:5x16x100x64,pkv_34:5x16x100x64,pkv_35:5x16x100x64,pkv_36:5x16x100x64,pkv_37:5x16x100x64,pkv_38:5x16x100x64,pkv_39:5x16x100x64,pkv_40:5x16x100x64,pkv_41:5x16x100x64,pkv_42:5x16x100x64,pkv_43:5x16x100x64,pkv_44:5x16x100x64,pkv_45:5x16x100x64,pkv_46:5x16x100x64,pkv_47:5x16x100x64 --maxShapes=input_ids:80x200,encoder_attention_mask:80x200,pkv_0:80x16x200x64,pkv_1:80x16x200x64,pkv_2:80x16x200x64,pkv_3:80x16x200x64,pkv_4:80x16x200x64,pkv_5:80x16x200x64,pkv_6:80x16x200x64,pkv_7:80x16x200x64,pkv_8:80x16x200x64,pkv_9:80x16x200x64,pkv_10:80x16x200x64,pkv_11:80x16x200x64,pkv_12:80x16x200x64,pkv_13:80x16x200x64,pkv_14:80x16x200x64,pkv_15:80x16x200x64,pkv_16:80x16x200x64,pkv_17:80x16x200x64,pkv_18:80x16x200x64,pkv_19:80x16x200x64,pkv_20:80x16x200x64,pkv_21:80x16x200x64,pkv_22:80x16x200x64,pkv_23:80x16x200x64,pkv_24:80x16x200x64,pkv_25:80x16x200x64,pkv_26:80x16x200x64,pkv_27:80x16x200x64,pkv_28:80x16x200x64,pkv_29:80x16x200x64,pkv_30:80x16x200x64,pkv_31:80x16x200x64,pkv_32:80x16x200x64,pkv_33:80x16x200x64,pkv_34:80x16x200x64,pkv_35:80x16x200x64,pkv_36:80x16x200x64,pkv_37:80x16x200x64,pkv_38:80x16x200x64,pkv_39:80x16x200x64,pkv_40:80x16x200x64,pkv_41:80x16x200x64,pkv_42:80x16x200x64,pkv_43:80x16x200x64,pkv_44:80x16x200x64,pkv_45:80x16x200x64,pkv_46:80x16x200x64,pkv_47:80x16x200x64 --shapes=input_ids:5x1,encoder_attention_mask:5x1,pkv_0:5x16x1x64,pkv_1:5x16x1x64,pkv_2:5x16x1x64,pkv_3:5x16x1x64,pkv_4:5x16x1x64,pkv_5:5x16x1x64,pkv_6:5x16x1x64,pkv_7:5x16x1x64,pkv_8:5x16x1x64,pkv_9:5x16x1x64,pkv_10:5x16x1x64,pkv_11:5x16x1x64,pkv_12:5x16x1x64,pkv_13:5x16x1x64,pkv_14:5x16x1x64,pkv_15:5x16x1x64,pkv_16:5x16x1x64,pkv_17:5x16x1x64,pkv_18:5x16x1x64,pkv_19:5x16x1x64,pkv_20:5x16x1x64,pkv_21:5x16x1x64,pkv_22:5x16x1x64,pkv_23:5x16x1x64,pkv_24:5x16x1x64,pkv_25:5x16x1x64,pkv_26:5x16x1x64,pkv_27:5x16x1x64,pkv_28:5x16x1x64,pkv_29:5x16x1x64,pkv_30:5x16x1x64,pkv_31:5x16x1x64,pkv_32:5x16x1x64,pkv_33:5x16x1x64,pkv_34:5x16x1x64,pkv_35:5x16x1x64,pkv_36:5x16x1x64,pkv_37:5x16x1x64,pkv_38:5x16x1x64,pkv_39:5x16x1x64,pkv_40:5x16x1x64,pkv_41:5x16x1x64,pkv_42:5x16x1x64,pkv_43:5x16x1x64,pkv_44:5x16x1x64,pkv_45:5x16x1x64,pkv_46:5x16x1x64,pkv_47:5x16x1x64
Here are the params:
min_batch = opt_batch = 5
max_batch = 80
min_seq_length = 1
opt_seq_length = 100
max_seq_length = 200
But the same error still persists.
Thanks. We will debug this. @zerollzeng Could you repro this and file an internal tracker bug? Thanks
My try on this bug: constant folding won't work, the error happened on the last matmul layer. if I don't dynamic shape then trt can build engine successfully.

Issue is fixed in TensorRT 8.5. Please verify when the release is public. You need to add --preview=+fasterDynamicShapes0805 parameter for trtrexec
[08/18/2022-23:32:35] [I] === Performance summary ===
[08/18/2022-23:32:35] [I] Throughput: 118.63 qps
[08/18/2022-23:32:35] [I] Latency: min = 8.68604 ms, max = 8.86206 ms, mean = 8.70558 ms, median = 8.70435 ms, percentile(90%) = 8.71228 ms, percentile(95%) = 8.71619 ms, percentile(99%) = 8.72046 ms
[08/18/2022-23:32:35] [I] Enqueue Time: min = 8.23904 ms, max = 8.40942 ms, mean = 8.25222 ms, median = 8.25098 ms, percentile(90%) = 8.25928 ms, percentile(95%) = 8.26166 ms, percentile(99%) = 8.26709 ms
[08/18/2022-23:32:35] [I] H2D Latency: min = 0.180298 ms, max = 0.191162 ms, mean = 0.182987 ms, median = 0.183105 ms, percentile(90%) = 0.184326 ms, percentile(95%) = 0.184814 ms, percentile(99%) = 0.186035 ms
[08/18/2022-23:32:35] [I] GPU Compute Time: min = 8.13654 ms, max = 8.30908 ms, mean = 8.15172 ms, median = 8.15057 ms, percentile(90%) = 8.15894 ms, percentile(95%) = 8.16144 ms, percentile(99%) = 8.16742 ms
[08/18/2022-23:32:35] [I] D2H Latency: min = 0.35498 ms, max = 0.377991 ms, mean = 0.370881 ms, median = 0.37085 ms, percentile(90%) = 0.372162 ms, percentile(95%) = 0.372864 ms, percentile(99%) = 0.37616 ms
[08/18/2022-23:32:35] [I] Total Host Walltime: 3.01779 s
[08/18/2022-23:32:35] [I] Total GPU Compute Time: 2.91832 s
[08/18/2022-23:32:35] [W] * Throughput may be bound by Enqueue Time rather than GPU Compute and the GPU may be under-utilized.
[08/18/2022-23:32:35] [W] If not already in use, --useCudaGraph (utilize CUDA graphs where possible) may increase the throughput.
[08/18/2022-23:32:35] [I] Explanations of the performance metrics are printed in the verbose logs.
[08/18/2022-23:32:35] [V]
[08/18/2022-23:32:35] [V] === Explanations of the performance metrics ===
[08/18/2022-23:32:35] [V] Total Host Walltime: the host walltime from when the first query (after warmups) is enqueued to when the last query is completed.
[08/18/2022-23:32:35] [V] GPU Compute Time: the GPU latency to execute the kernels for a query.
[08/18/2022-23:32:35] [V] Total GPU Compute Time: the summation of the GPU Compute Time of all the queries. If this is significantly shorter than Total Host Walltime, the GPU may be under-utilized because of host-side overheads or data transfers.
[08/18/2022-23:32:35] [V] Throughput: the observed throughput computed by dividing the number of queries by the Total Host Walltime. If this is significantly lower than the reciprocal of GPU Compute Time, the GPU may be under-utilized because of host-side overheads or data transfers.
[08/18/2022-23:32:35] [V] Enqueue Time: the host latency to enqueue a query. If this is longer than GPU Compute Time, the GPU may be under-utilized.
[08/18/2022-23:32:35] [V] H2D Latency: the latency for host-to-device data transfers for input tensors of a single query.
[08/18/2022-23:32:35] [V] D2H Latency: the latency for device-to-host data transfers for output tensors of a single query.
[08/18/2022-23:32:35] [V] Latency: the summation of H2D Latency, GPU Compute Time, and D2H Latency. This is the latency to infer a single query.
[08/18/2022-23:32:35] [I]
&&&& PASSED TensorRT.trtexec [TensorRT v8500] # ./trtexec --onnx=/home/okorzh/trt/m2m100_418M-decoder.onnx --verbose --minShapes=input_ids:5x1,encoder_attention_mask:5x1,pkv_0:5x16x1x64,pkv_1:5x16x1x64,pkv_2:5x16x1x64,pkv_3:5x16x1x64,pkv_4:5x16x1x64,pkv_5:5x16x1x64,pkv_6:5x16x1x64,pkv_7:5x16x1x64,pkv_8:5x16x1x64,pkv_9:5x16x1x64,pkv_10:5x16x1x64,pkv_11:5x16x1x64,pkv_12:5x16x1x64,pkv_13:5x16x1x64,pkv_14:5x16x1x64,pkv_15:5x16x1x64,pkv_16:5x16x1x64,pkv_17:5x16x1x64,pkv_18:5x16x1x64,pkv_19:5x16x1x64,pkv_20:5x16x1x64,pkv_21:5x16x1x64,pkv_22:5x16x1x64,pkv_23:5x16x1x64,pkv_24:5x16x1x64,pkv_25:5x16x1x64,pkv_26:5x16x1x64,pkv_27:5x16x1x64,pkv_28:5x16x1x64,pkv_29:5x16x1x64,pkv_30:5x16x1x64,pkv_31:5x16x1x64,pkv_32:5x16x1x64,pkv_33:5x16x1x64,pkv_34:5x16x1x64,pkv_35:5x16x1x64,pkv_36:5x16x1x64,pkv_37:5x16x1x64,pkv_38:5x16x1x64,pkv_39:5x16x1x64,pkv_40:5x16x1x64,pkv_41:5x16x1x64,pkv_42:5x16x1x64,pkv_43:5x16x1x64,pkv_44:5x16x1x64,pkv_45:5x16x1x64,pkv_46:5x16x1x64,pkv_47:5x16x1x64 --optShapes=input_ids:5x100,encoder_attention_mask:5x100,pkv_0:5x16x100x64,pkv_1:5x16x100x64,pkv_2:5x16x100x64,pkv_3:5x16x100x64,pkv_4:5x16x100x64,pkv_5:5x16x100x64,pkv_6:5x16x100x64,pkv_7:5x16x100x64,pkv_8:5x16x100x64,pkv_9:5x16x100x64,pkv_10:5x16x100x64,pkv_11:5x16x100x64,pkv_12:5x16x100x64,pkv_13:5x16x100x64,pkv_14:5x16x100x64,pkv_15:5x16x100x64,pkv_16:5x16x100x64,pkv_17:5x16x100x64,pkv_18:5x16x100x64,pkv_19:5x16x100x64,pkv_20:5x16x100x64,pkv_21:5x16x100x64,pkv_22:5x16x100x64,pkv_23:5x16x100x64,pkv_24:5x16x100x64,pkv_25:5x16x100x64,pkv_26:5x16x100x64,pkv_27:5x16x100x64,pkv_28:5x16x100x64,pkv_29:5x16x100x64,pkv_30:5x16x100x64,pkv_31:5x16x100x64,pkv_32:5x16x100x64,pkv_33:5x16x100x64,pkv_34:5x16x100x64,pkv_35:5x16x100x64,pkv_36:5x16x100x64,pkv_37:5x16x100x64,pkv_38:5x16x100x64,pkv_39:5x16x100x64,pkv_40:5x16x100x64,pkv_41:5x16x100x64,pkv_42:5x16x100x64,pkv_43:5x16x100x64,pkv_44:5x16x100x64,pkv_45:5x16x100x64,pkv_46:5x16x100x64,pkv_47:5x16x100x64 --maxShapes=input_ids:80x200,encoder_attention_mask:80x200,pkv_0:80x16x200x64,pkv_1:80x16x200x64,pkv_2:80x16x200x64,pkv_3:80x16x200x64,pkv_4:80x16x200x64,pkv_5:80x16x200x64,pkv_6:80x16x200x64,pkv_7:80x16x200x64,pkv_8:80x16x200x64,pkv_9:80x16x200x64,pkv_10:80x16x200x64,pkv_11:80x16x200x64,pkv_12:80x16x200x64,pkv_13:80x16x200x64,pkv_14:80x16x200x64,pkv_15:80x16x200x64,pkv_16:80x16x200x64,pkv_17:80x16x200x64,pkv_18:80x16x200x64,pkv_19:80x16x200x64,pkv_20:80x16x200x64,pkv_21:80x16x200x64,pkv_22:80x16x200x64,pkv_23:80x16x200x64,pkv_24:80x16x200x64,pkv_25:80x16x200x64,pkv_26:80x16x200x64,pkv_27:80x16x200x64,pkv_28:80x16x200x64,pkv_29:80x16x200x64,pkv_30:80x16x200x64,pkv_31:80x16x200x64,pkv_32:80x16x200x64,pkv_33:80x16x200x64,pkv_34:80x16x200x64,pkv_35:80x16x200x64,pkv_36:80x16x200x64,pkv_37:80x16x200x64,pkv_38:80x16x200x64,pkv_39:80x16x200x64,pkv_40:80x16x200x64,pkv_41:80x16x200x64,pkv_42:80x16x200x64,pkv_43:80x16x200x64,pkv_44:80x16x200x64,pkv_45:80x16x200x64,pkv_46:80x16x200x64,pkv_47:80x16x200x64 --shapes=input_ids:5x1,encoder_attention_mask:5x1,pkv_0:5x16x1x64,pkv_1:5x16x1x64,pkv_2:5x16x1x64,pkv_3:5x16x1x64,pkv_4:5x16x1x64,pkv_5:5x16x1x64,pkv_6:5x16x1x64,pkv_7:5x16x1x64,pkv_8:5x16x1x64,pkv_9:5x16x1x64,pkv_10:5x16x1x64,pkv_11:5x16x1x64,pkv_12:5x16x1x64,pkv_13:5x16x1x64,pkv_14:5x16x1x64,pkv_15:5x16x1x64,pkv_16:5x16x1x64,pkv_17:5x16x1x64,pkv_18:5x16x1x64,pkv_19:5x16x1x64,pkv_20:5x16x1x64,pkv_21:5x16x1x64,pkv_22:5x16x1x64,pkv_23:5x16x1x64,pkv_24:5x16x1x64,pkv_25:5x16x1x64,pkv_26:5x16x1x64,pkv_27:5x16x1x64,pkv_28:5x16x1x64,pkv_29:5x16x1x64,pkv_30:5x16x1x64,pkv_31:5x16x1x64,pkv_32:5x16x1x64,pkv_33:5x16x1x64,pkv_34:5x16x1x64,pkv_35:5x16x1x64,pkv_36:5x16x1x64,pkv_37:5x16x1x64,pkv_38:5x16x1x64,pkv_39:5x16x1x64,pkv_40:5x16x1x64,pkv_41:5x16x1x64,pkv_42:5x16x1x64,pkv_43:5x16x1x64,pkv_44:5x16x1x64,pkv_45:5x16x1x64,pkv_46:5x16x1x64,pkv_47:5x16x1x64 --preview=+fasterDynamicShapes0805
closing since no activity for more than 14 days, please reopen if you still have question, thanks!
Hi @oxana-nvidia @ttyio , I got the issue when converting torch .pt file to trt with torch2trt, not onnx though. I tried the least tensorrt 8.5.2, and the problem still exits. The problem is mainly from the matmul. Is that only fixed for onnx model to trt engine? Can you guys please fix the problem in general? My model has dynamic input as well.
In addition, once I removed the matmul the conversion worked fine. However the result had accuracy drop compared to torch model output.
*With static input shape, the conversion worked fine.