May i use triton-inference-server to run T5 model
I can see the T5 triton backed related file in https://github.com/NVIDIA/FasterTransformer/tree/dev/v5.0_beta_2021.11_tag/src/fastertransformer/triton_backend/t5 But i also find the https://github.com/triton-inference-server/fastertransformer_backend just support gpt I wonder whether T5 is supported by triton inference server. Is there a doc or example to tell us how to use it?
FT triton backend already supports T5, please refer https://github.com/triton-inference-server/fastertransformer_backend/tree/dev/v1.1_beta#prepare-triton-t5-model-store-in-the-docker.
[I do as README, but i met some errors as follows:
Firstly, i start the server(the model path cannot be setted like --model-repository=/workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/ or --model-repository=/workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1 , because the program will failed with -- error: creating server: Internal - failed to load all models) as follows:
mpirun -n 1 --allow-run-as-root /opt/tritonserver/bin/tritonserver --model-repository=/workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu/
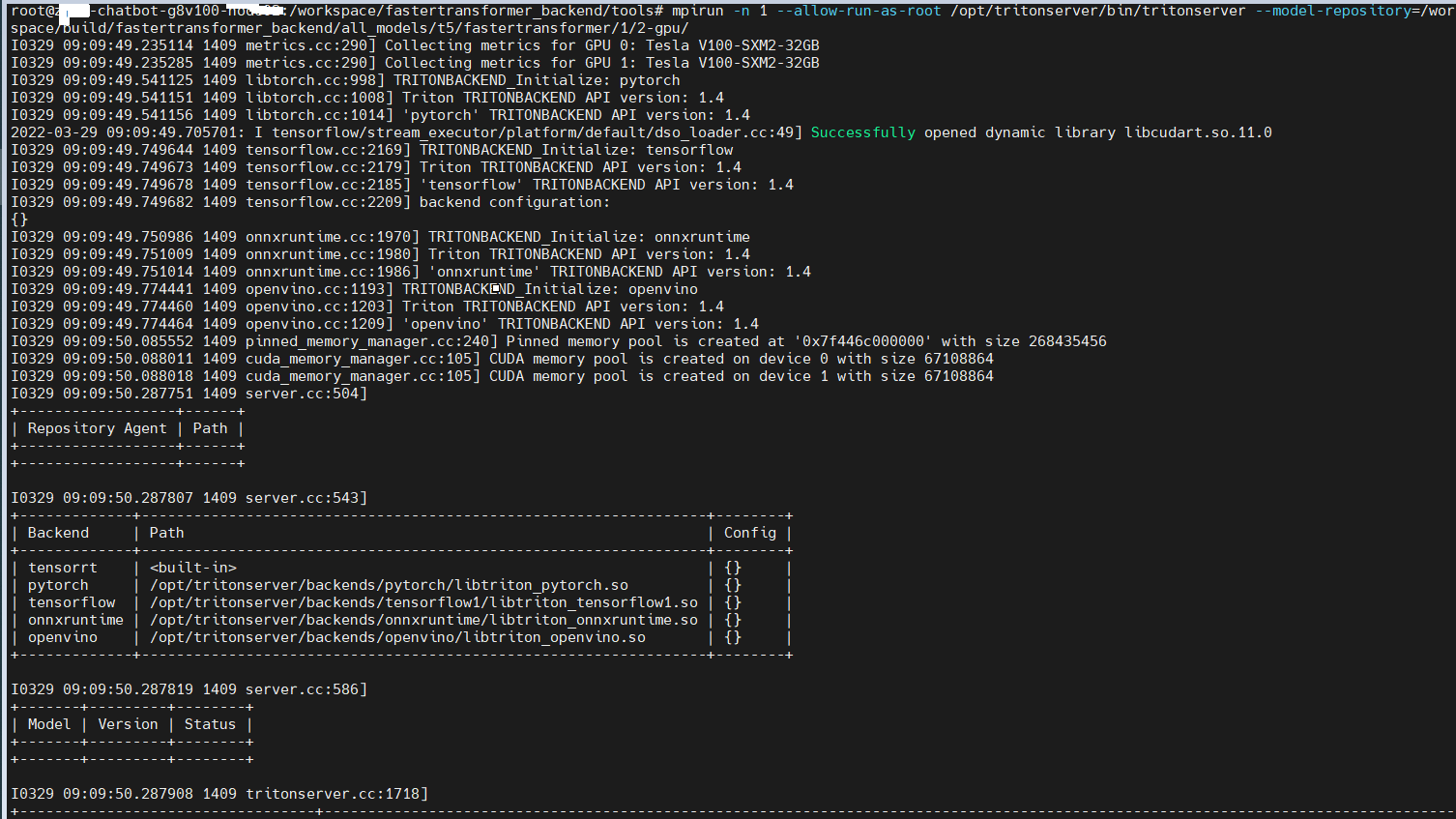
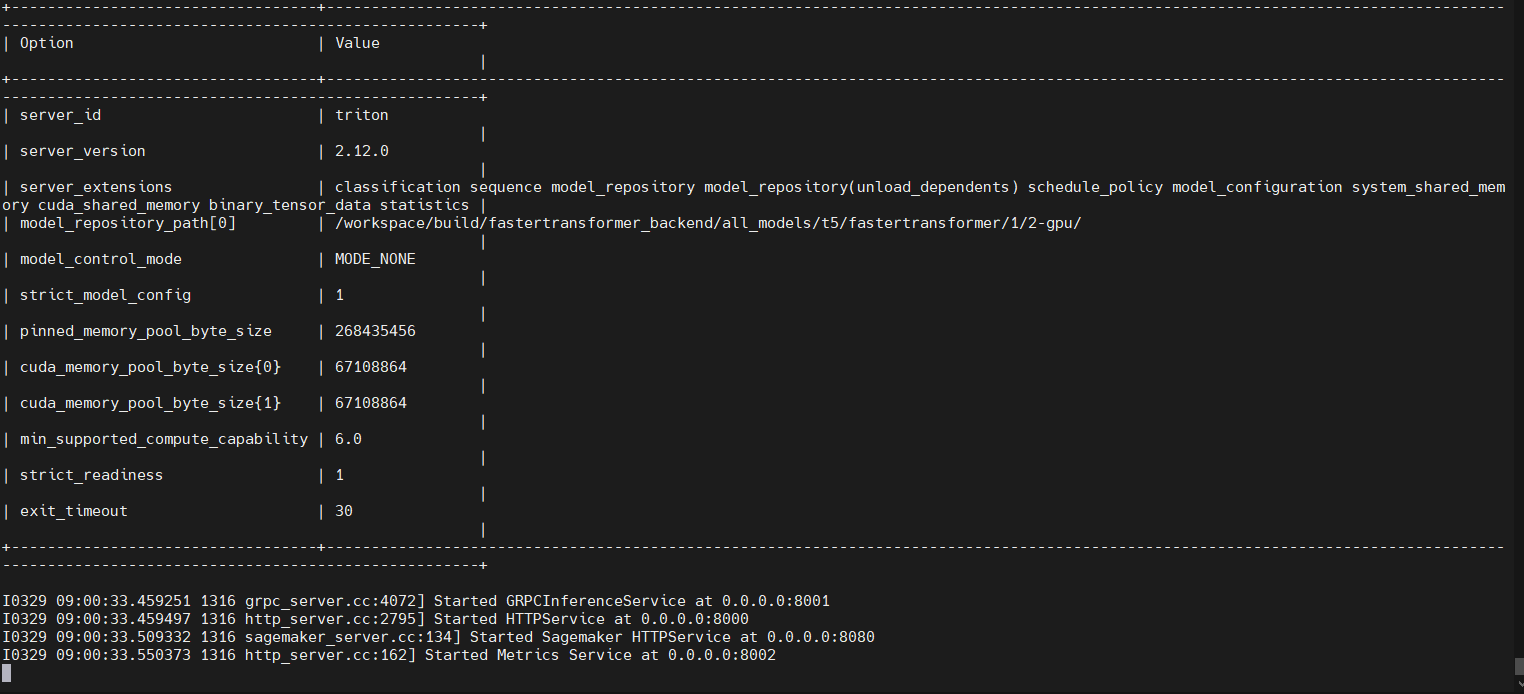 Secondly, i start the client
sh /workspace/fastertransformer_backend/tools/run_client.sh
then i get this in logs:
Secondly, i start the client
sh /workspace/fastertransformer_backend/tools/run_client.sh
then i get this in logs:

](https://github.com/triton-inference-server/fastertransformer_backend/issues/15#issuecomment-1081617473)
Please set the model-repository=/workspace/build/fastertransformer_backend/all_models/t5
After i mv the model_checkpoint_path to 2-gpu
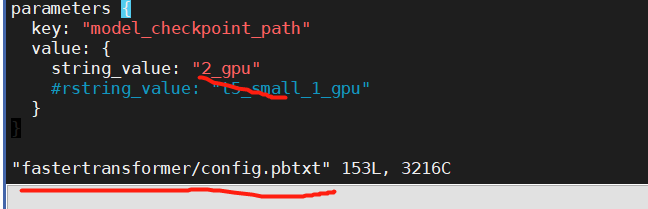 then i run the command:mpirun -n 1 --allow-run-as-root /opt/tritonserver/bin/tritonserver --model-repository
=/workspace/build/fastertransformer_backend/all_models/t5
i got this error , it sames the file name is wrong:
then i run the command:mpirun -n 1 --allow-run-as-root /opt/tritonserver/bin/tritonserver --model-repository
=/workspace/build/fastertransformer_backend/all_models/t5
i got this error , it sames the file name is wrong:

the dir struture is:
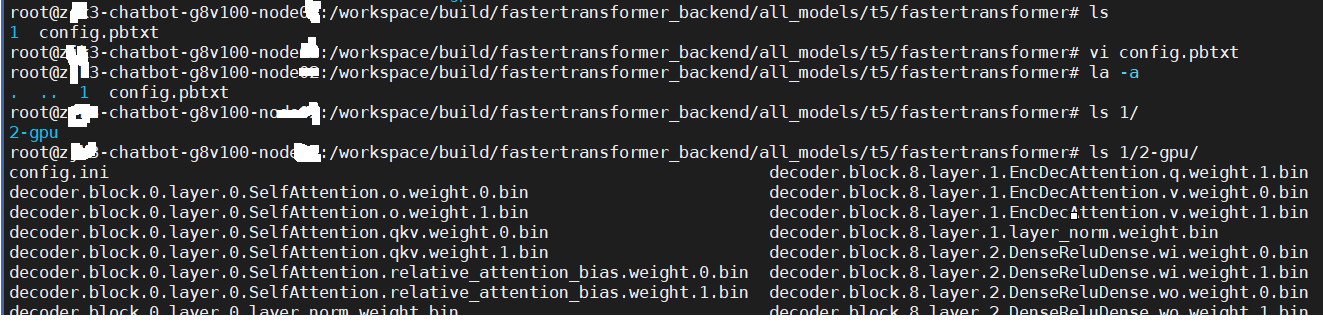
https://github.com/NVIDIA/FasterTransformer/blob/dev/v5.0_beta/src/fastertransformer/triton_backend/t5/T5TritonModel.cc#L116
Please read the guide https://github.com/triton-inference-server/fastertransformer_backend/tree/dev/v1.1_beta#prepare-triton-t5-model-store-in-the-docker
I guess the problem is because you should set model_checkpoint_path to /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu/, but not 2_gpu/
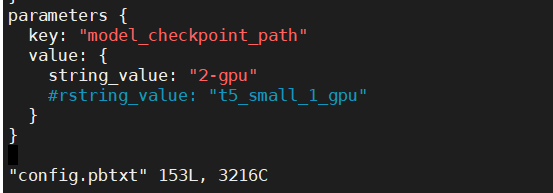 then i also get the error.
then i also get the error.

you should set model_checkpoint_path to /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu/, but not 2_gpu/
 Thanx, it worked! but another question the cuda version must be 11.4 if i want to run t5 in triton ?
Thanx, it worked! but another question the cuda version must be 11.4 if i want to run t5 in triton ?
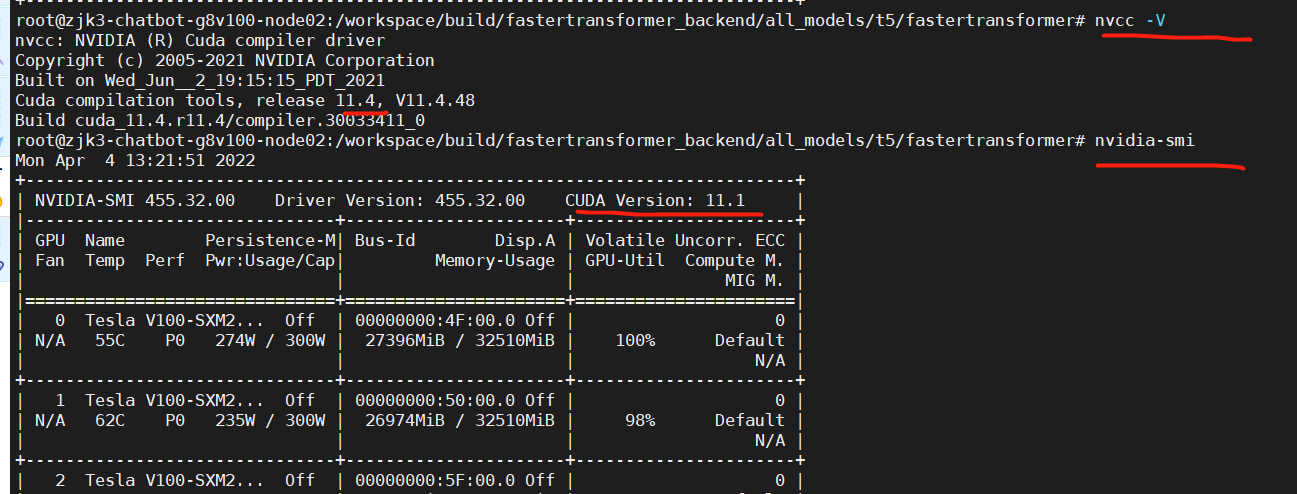
You can change the based triton server docker version in Docker file. The default version is 21.08, which is installed cuda 11.4.
I set the CONTAINER_VERSION=20.10
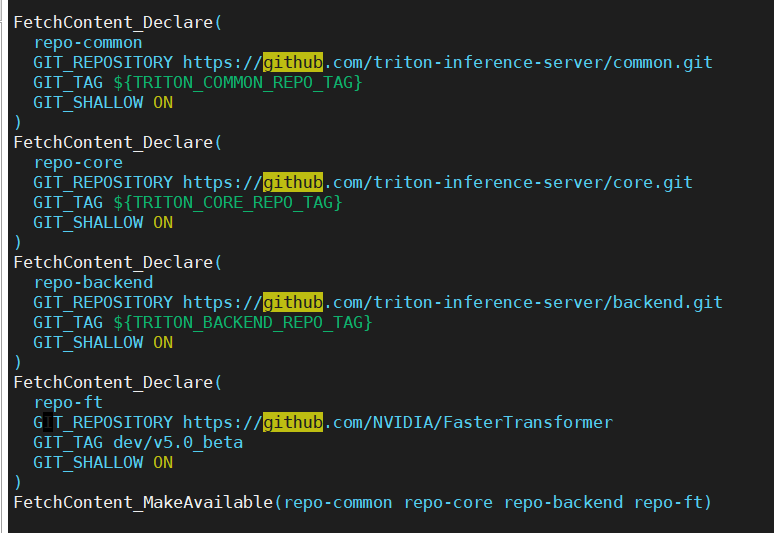
it sames the github access errors in cmake file
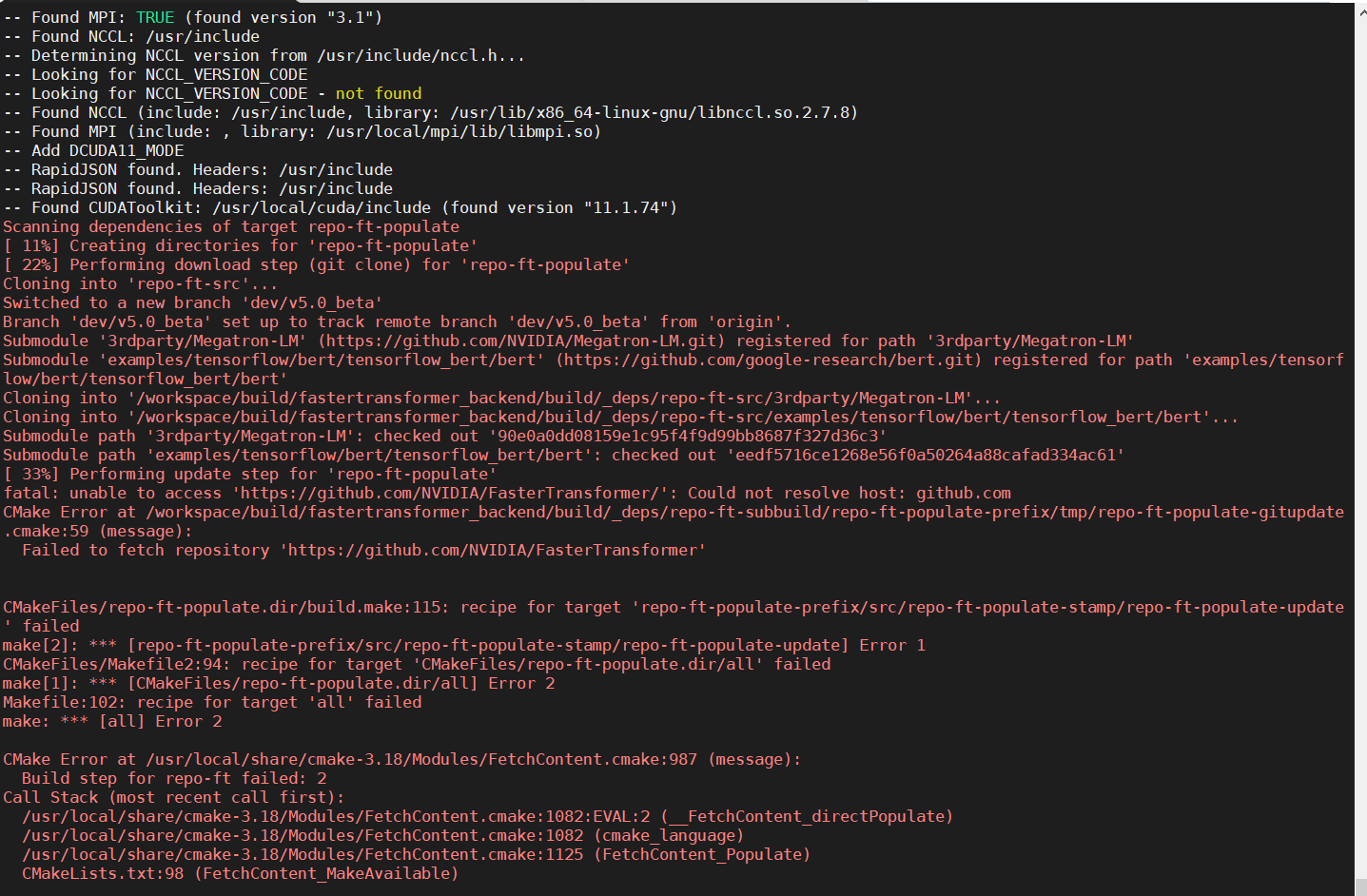 or
or
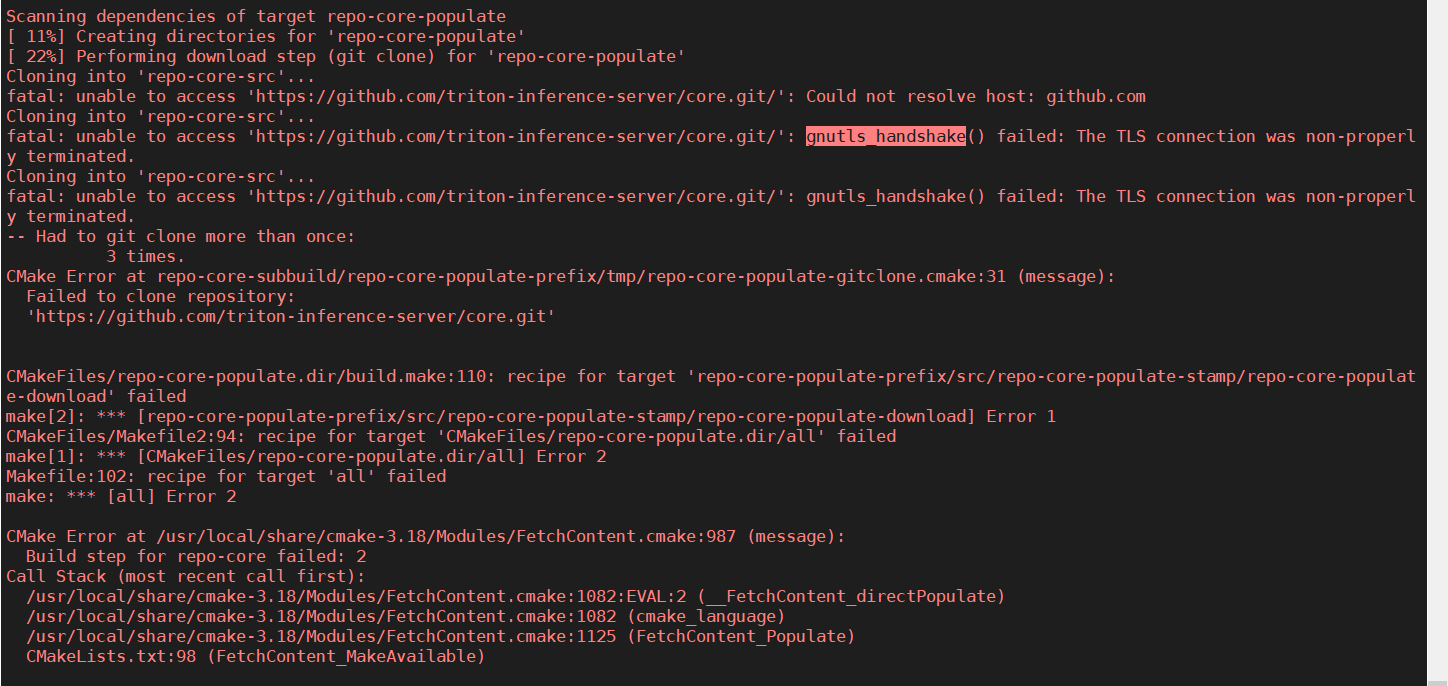
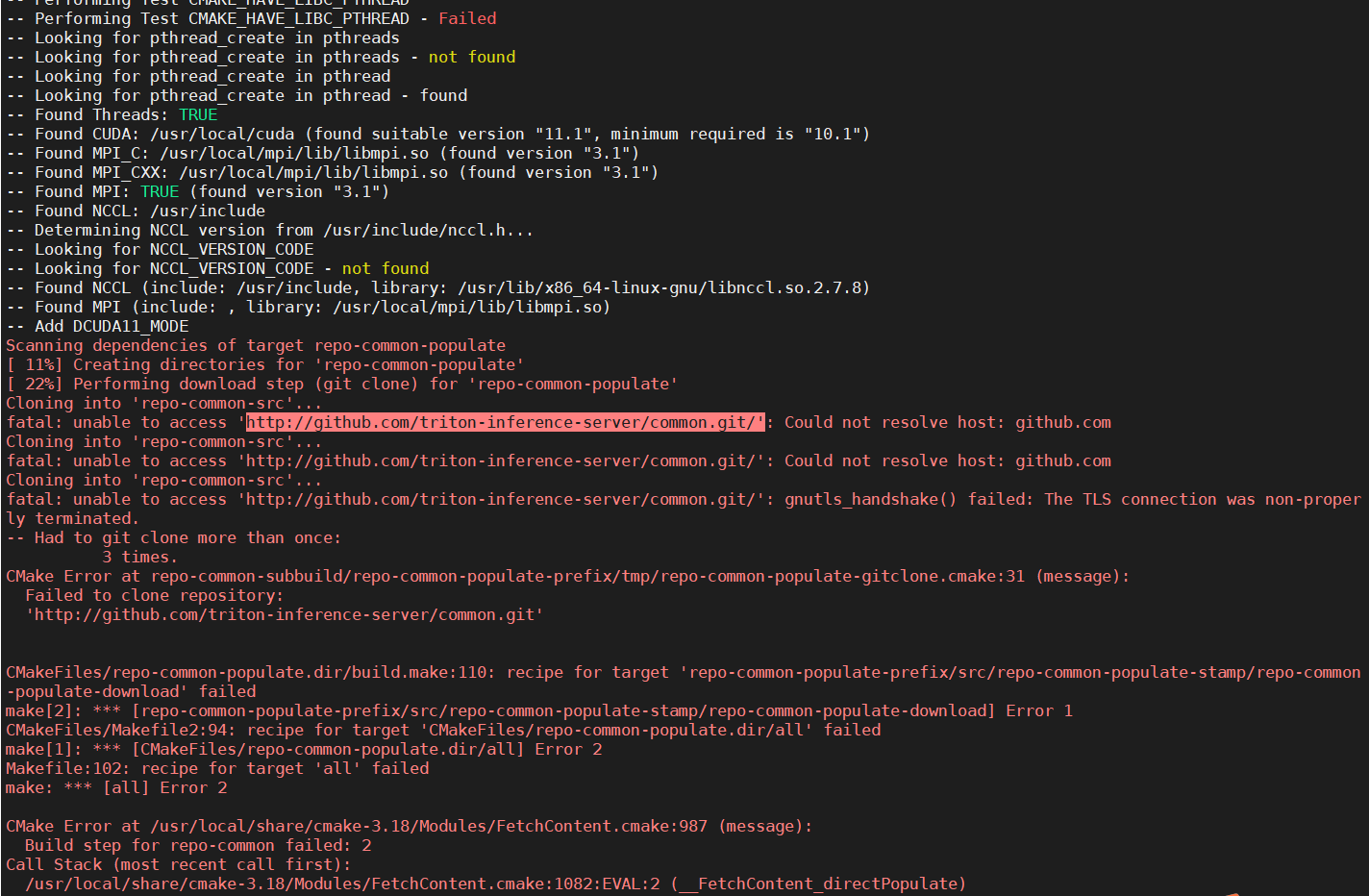
Then i change the https to http in fastertransformer_backend/CMakeLists.txt, then i get this error:
Do you mean that you can build the docker successfully before you modify the version of docker, but encounter the error after you change the docker version?
How do you build the ft backend? By docker file or building it in the docker image?
Have you tried the 21.08 docker version?
I can build the Dockerfile successfully with default 21.08 CONTAINER_VERSION, then i met the cuda mismatch error. So i change the the CONTAINER_VERSION to 20.10 as you said and build the docker image with docker file , i met the 'unable to access github' error.
Have you tried other version? 21.07? 21.06?
You can also try to update your driver.
Since the error of 20.10 is on github access, I have no idea about it.
I try 21.07, it's the same error.
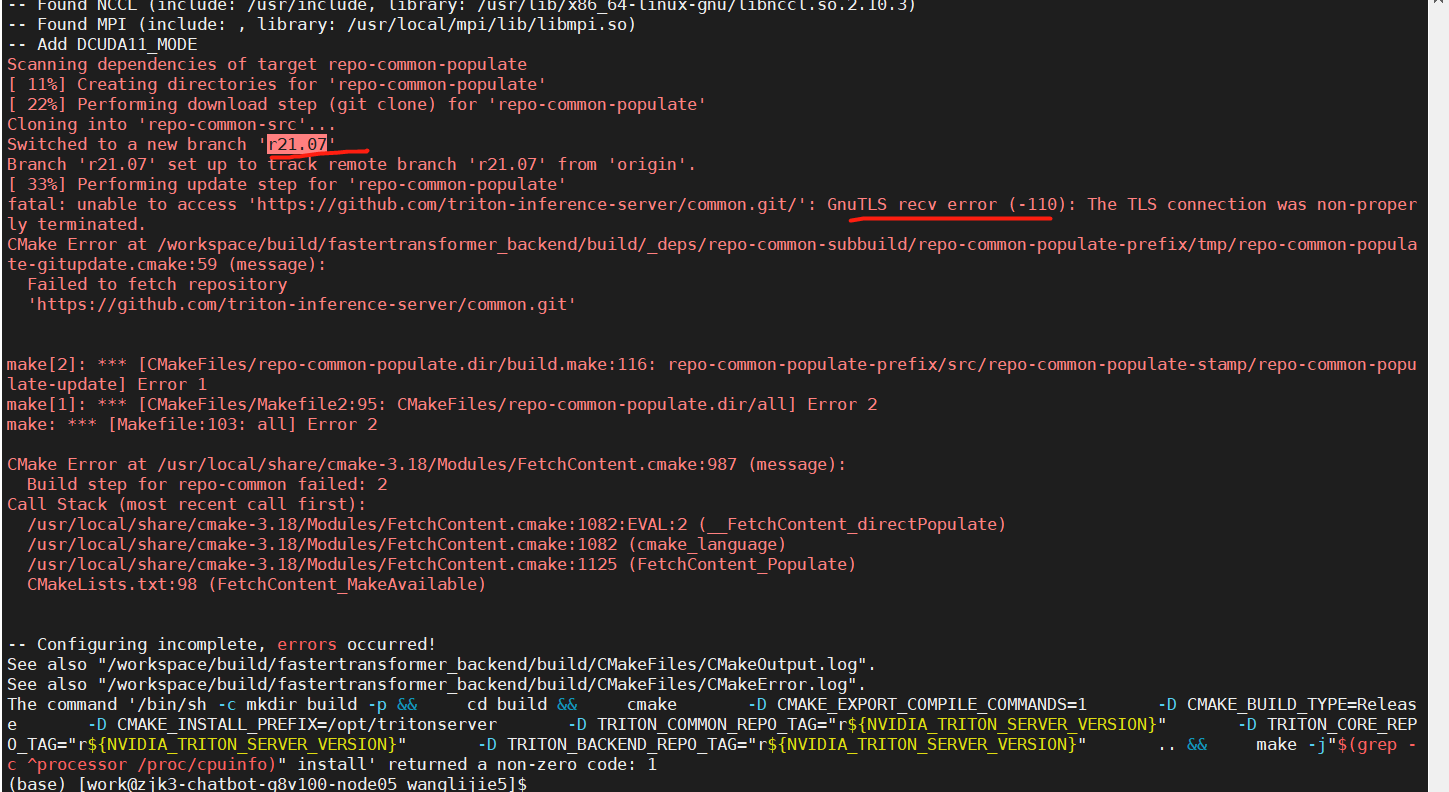
And i can find the 20.10 in the https://github.com/triton-inference-server/server/branches/all?page=5 Maybe it's the network error. Should i do some config about github in the Dockerfile?
Sorry, I have no idea about the error because it does not happen on FT side.
I add the follows in the dockerfile before #backend build, it seems the network unstable. RUN sed -i "s/archive.ubuntu./mirrors.aliyun./g" /etc/apt/sources.list RUN sed -i "s/deb.debian.org/mirrors.aliyun.com/g" /etc/apt/sources.list RUN sed -i "s/security.debian.org/mirrors.aliyun.com/debian-security/g" /etc/apt/sources.list RUN apt-get update
Then in the build process,i met this
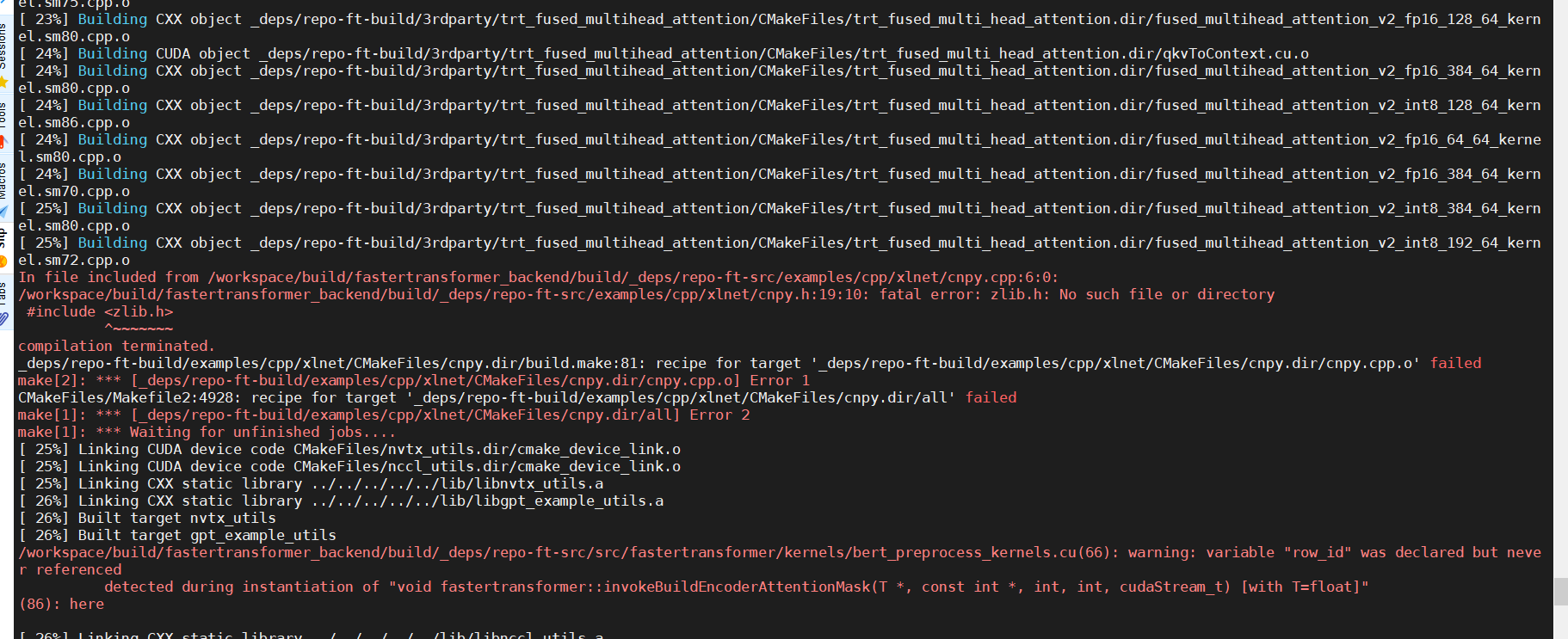
After I resolve the download problem and Dependency problem: (1,i modify the https://github to http://github 2,when build the dockerfile i entry the current docker and modify the /etc/hosts add: 140.82.114.3 github.com 185.199.108.153 assets-cdn.github.com 3,i install zlib in current docker)
Then i met this error as follows:

I modify the version to 20.12, the current step can build success, then i met this below. i add this:apt-get install --no-install-recommends -y software-properties-common in dockerfile command, and it is solved.

In version 20.12, i can success start the server : -----------------step1-----------------: root@node02:/workspace/build/fastertransformer_backend/all_models/t5/fastertransformer# mpirun -n 1 --allow-run-as-root /opt/tritonserver/bin/tritonserver --model-repository=/workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu I0413 04:47:12.551729 1308 metrics.cc:221] Collecting metrics for GPU 0: Tesla V100-SXM2-32GB I0413 04:47:12.559994 1308 metrics.cc:221] Collecting metrics for GPU 1: Tesla V100-SXM2-32GB I0413 04:47:12.948742 1308 libtorch.cc:945] TRITONBACKEND_Initialize: pytorch I0413 04:47:12.948785 1308 libtorch.cc:955] Triton TRITONBACKEND API version: 1.0 I0413 04:47:12.948791 1308 libtorch.cc:961] 'pytorch' TRITONBACKEND API version: 1.0 2022-04-13 04:47:13.254049: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0 I0413 04:47:13.315844 1308 tensorflow.cc:1877] TRITONBACKEND_Initialize: tensorflow I0413 04:47:13.315887 1308 tensorflow.cc:1887] Triton TRITONBACKEND API version: 1.0 I0413 04:47:13.315893 1308 tensorflow.cc:1893] 'tensorflow' TRITONBACKEND API version: 1.0 I0413 04:47:13.315898 1308 tensorflow.cc:1917] backend configuration: {} I0413 04:47:13.319122 1308 onnxruntime.cc:1715] TRITONBACKEND_Initialize: onnxruntime I0413 04:47:13.319167 1308 onnxruntime.cc:1725] Triton TRITONBACKEND API version: 1.0 I0413 04:47:13.319174 1308 onnxruntime.cc:1731] 'onnxruntime' TRITONBACKEND API version: 1.0 I0413 04:47:13.743538 1308 pinned_memory_manager.cc:199] Pinned memory pool is created at '0x7f352c000000' with size 268435456 I0413 04:47:13.746193 1308 cuda_memory_manager.cc:103] CUDA memory pool is created on device 0 with size 67108864 I0413 04:47:13.746216 1308 cuda_memory_manager.cc:103] CUDA memory pool is created on device 1 with size 67108864 I0413 04:47:13.984656 1308 server.cc:490] +-------------+-----------------------------------------------------------------+------+ | Backend | Config | Path | +-------------+-----------------------------------------------------------------+------+ | pytorch | /opt/tritonserver/backends/pytorch/libtriton_pytorch.so | {} | | tensorflow | /opt/tritonserver/backends/tensorflow1/libtriton_tensorflow1.so | {} | | onnxruntime | /opt/tritonserver/backends/onnxruntime/libtriton_onnxruntime.so | {} | +-------------+-----------------------------------------------------------------+------+
I0413 04:47:13.984698 1308 server.cc:533] +-------+---------+--------+ | Model | Version | Status | +-------+---------+--------+ +-------+---------+--------+
I0413 04:47:13.984841 1308 tritonserver.cc:1620] +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+ | Option | Value | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+ | server_id | triton | | server_version | 2.6.0 | | server_extensions | classification sequence model_repository schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_tensor_data statistics | | model_repository_path[0] | /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu | | model_control_mode | MODE_NONE | | strict_model_config | 1 | | pinned_memory_pool_byte_size | 268435456 | | cuda_memory_pool_byte_size{0} | 67108864 | | cuda_memory_pool_byte_size{1} | 67108864 | | min_supported_compute_capability | 6.0 | | strict_readiness | 1 | | exit_timeout | 30 | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+
I0413 04:47:14.021852 1308 grpc_server.cc:3979] Started GRPCInferenceService at 0.0.0.0:8001 I0413 04:47:14.022257 1308 http_server.cc:2717] Started HTTPService at 0.0.0.0:8000 I0413 04:47:14.067500 1308 http_server.cc:2736] Started Metrics Service at 0.0.0.0:8002
Then i try to test i met this, it seems the model_name error, where should i modify ? i modify the model name, it failed. name: "fastertransformer" backend: "fastertransformer" #default_model_filename: "t5" default_model_filename: "fastertransformer"
-----------------step2-----------------:
root@node02:/workspace/build/fastertransformer_backend/build# python /workspace/fastertransformer_backend/tools/t5_utils/t5_end_to_end_test.py
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'T5Tokenizer'.
The class this function is called from is 'PreTrainedTokenizerFast'.
set request
Traceback (most recent call last):
File "/workspace/fastertransformer_backend/tools/t5_utils/t5_end_to_end_test.py", line 153, in
Please set the model-repository=/workspace/build/fastertransformer_backend/all_models/t5
I set the model-repository as you told, then i met this:
root@node02:/workspace/build/fastertransformer_backend/all_models/t5/fastertransformer# mpirun -n 1 --allow-run-as-root /opt/tritonserver/bin/tritonserver --model-repository=/workspace/build/fastertransformer_backend/all_models/t5
.......
And the terminate called after throwing an instance of 'std::runtime_error'
what(): [FT][ERROR] Assertion fail: /workspace/build/fastertransformer_backend/src/libfastertransformer.cc:552
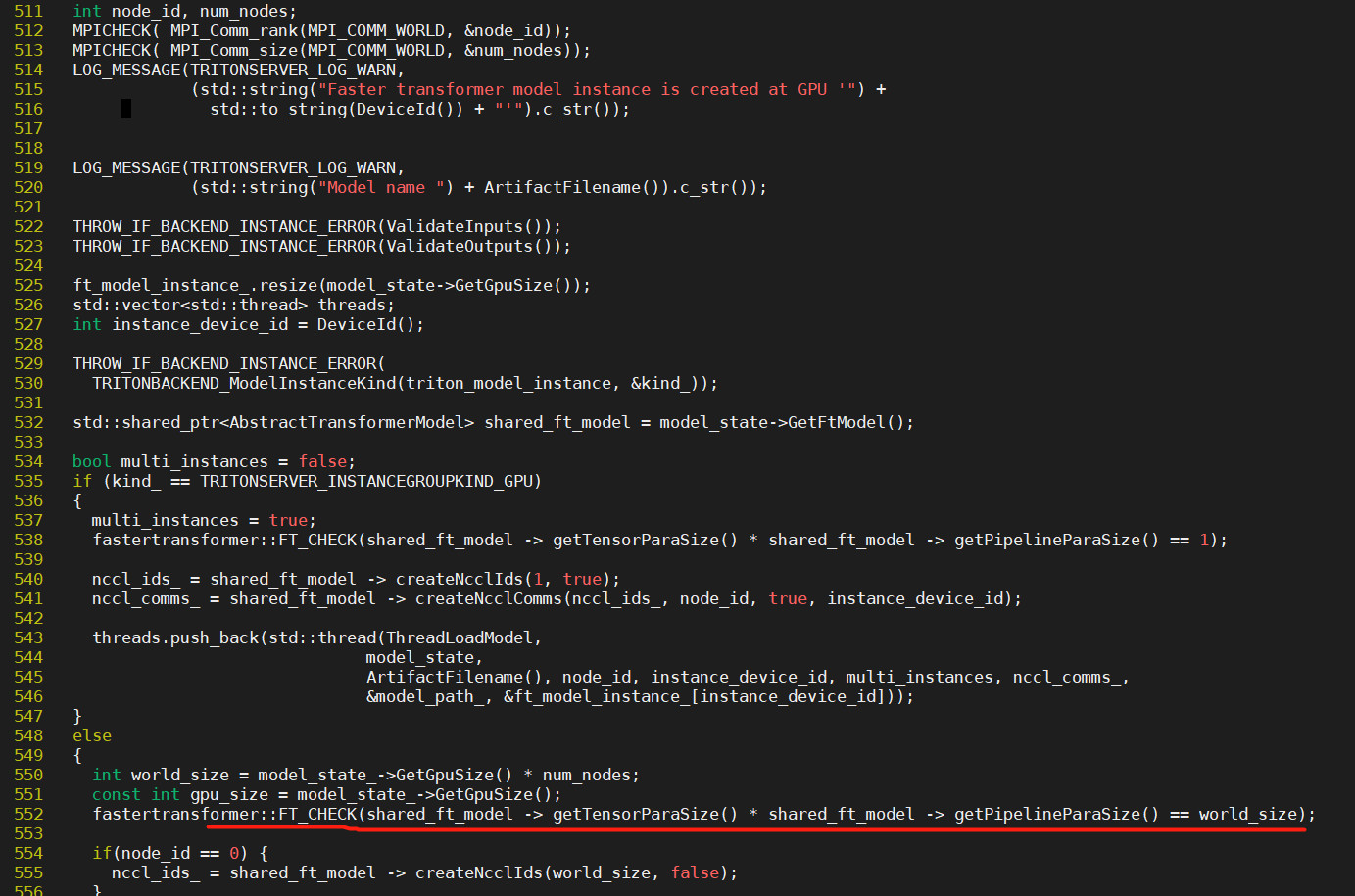
--------solution-----------: When i export CUDA_VISIBLE_DEVICES=1, just single gpu can start sucessfully. ###########So how can i use multiply gpus ############ ?
--------the starting logs and decoding logs as follows---------: root@node02:/workspace/build/fastertransformer_backend/all_models/t5/fastertransformer# mpirun -n 1 --allow-run-as-root /opt/tritonserver/bin/tritonserver --model-repository=/workspace/build/fastertransformer_backend/all_models/t5 I0413 05:17:56.102121 1647 metrics.cc:221] Collecting metrics for GPU 0: Tesla V100-SXM2-32GB I0413 05:17:56.412339 1647 libtorch.cc:945] TRITONBACKEND_Initialize: pytorch I0413 05:17:56.412370 1647 libtorch.cc:955] Triton TRITONBACKEND API version: 1.0 I0413 05:17:56.412375 1647 libtorch.cc:961] 'pytorch' TRITONBACKEND API version: 1.0 2022-04-13 05:17:56.638007: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0 I0413 05:17:56.682853 1647 tensorflow.cc:1877] TRITONBACKEND_Initialize: tensorflow I0413 05:17:56.682880 1647 tensorflow.cc:1887] Triton TRITONBACKEND API version: 1.0 I0413 05:17:56.682885 1647 tensorflow.cc:1893] 'tensorflow' TRITONBACKEND API version: 1.0 I0413 05:17:56.682888 1647 tensorflow.cc:1917] backend configuration: {} I0413 05:17:56.684666 1647 onnxruntime.cc:1715] TRITONBACKEND_Initialize: onnxruntime I0413 05:17:56.684688 1647 onnxruntime.cc:1725] Triton TRITONBACKEND API version: 1.0 I0413 05:17:56.684695 1647 onnxruntime.cc:1731] 'onnxruntime' TRITONBACKEND API version: 1.0 I0413 05:17:57.007988 1647 pinned_memory_manager.cc:199] Pinned memory pool is created at '0x7f6194000000' with size 268435456 I0413 05:17:57.009293 1647 cuda_memory_manager.cc:103] CUDA memory pool is created on device 0 with size 67108864 I0413 05:17:57.015102 1647 model_repository_manager.cc:787] loading: fastertransformer:1 I0413 05:17:57.165399 1647 libfastertransformer.cc:1173] TRITONBACKEND_Initialize: fastertransformer I0413 05:17:57.165459 1647 libfastertransformer.cc:1183] Triton TRITONBACKEND API version: 1.0 I0413 05:17:57.165483 1647 libfastertransformer.cc:1189] 'fastertransformer' TRITONBACKEND API version: 1.0 I0413 05:17:57.166593 1647 libfastertransformer.cc:1221] TRITONBACKEND_ModelInitialize: fastertransformer (version 1) W0413 05:17:57.168732 1647 libfastertransformer.cc:157] model configuration: { "name": "fastertransformer", "platform": "", "backend": "fastertransformer", "version_policy": { "latest": { "num_versions": 1 } }, "max_batch_size": 128, "input": [ { "name": "INPUT_ID", "data_type": "TYPE_UINT32", "format": "FORMAT_NONE", "dims": [ -1 ], "is_shape_tensor": false, "allow_ragged_batch": false }, { "name": "REQUEST_INPUT_LEN", "data_type": "TYPE_UINT32", "format": "FORMAT_NONE", "dims": [ -1 ], "is_shape_tensor": false, "allow_ragged_batch": false } ], "output": [ { "name": "OUTPUT0", "data_type": "TYPE_UINT32", "dims": [ -1, -1 ], "label_filename": "", "is_shape_tensor": false }, { "name": "OUTPUT1", "data_type": "TYPE_UINT32", "dims": [ -1 ], "label_filename": "", "is_shape_tensor": false } ], "batch_input": [], "batch_output": [], "optimization": { "priority": "PRIORITY_DEFAULT", "input_pinned_memory": { "enable": true }, "output_pinned_memory": { "enable": true } }, "instance_group": [ { "name": "fastertransformer_0", "kind": "KIND_CPU", "count": 1, "gpus": [], "profile": [] } ], "default_model_filename": "t5", "cc_model_filenames": {}, "metric_tags": {}, "parameters": { "top_p": { "string_value": "0.0" }, "int8_mode": { "string_value": "0" }, "model_type": { "string_value": "T5" }, "model_checkpoint_path": { "string_value": "/workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu/" }, "max_decoding_seq_len": { "string_value": "528" }, "pipeline_para_size": { "string_value": "1" }, "beam_search_diversity_rate": { "string_value": "0.0" }, "is_half": { "string_value": "1" }, "temperature": { "string_value": "1.0" }, "len_penalty": { "string_value": "1.0" }, "repetition_penalty": { "string_value": "1.0" }, "beam_width": { "string_value": "1" }, "max_encoder_seq_len": { "string_value": "512" }, "tensor_para_size": { "string_value": "1" }, "top_k": { "string_value": "1" } }, "model_warmup": [] } I0413 05:17:57.171733 1647 libfastertransformer.cc:1267] TRITONBACKEND_ModelInstanceInitialize: fastertransformer_0 (device 0) W0413 05:17:57.171771 1647 libfastertransformer.cc:514] Faster transformer model instance is created at GPU '0' W0413 05:17:57.171786 1647 libfastertransformer.cc:519] Model name t5 W0413 05:17:57.171816 1647 libfastertransformer.cc:602] get input name: INPUT_ID W0413 05:17:57.171834 1647 libfastertransformer.cc:614] input: INPUT_ID, type: TYPE_UINT32, shape: [63, 0] W0413 05:17:57.171846 1647 libfastertransformer.cc:602] get input name: REQUEST_INPUT_LEN W0413 05:17:57.171853 1647 libfastertransformer.cc:614] input: REQUEST_INPUT_LEN, type: TYPE_UINT32, shape: [63, 0] W0413 05:17:57.171859 1647 libfastertransformer.cc:635] get input name: OUTPUT0 W0413 05:17:57.171865 1647 libfastertransformer.cc:647] input: OUTPUT0, type: TYPE_UINT32, shape: [63, 63] W0413 05:17:57.171879 1647 libfastertransformer.cc:635] get input name: OUTPUT1 W0413 05:17:57.171887 1647 libfastertransformer.cc:647] input: OUTPUT1, type: TYPE_UINT32, shape: [63, 0] Before Loading Model: after allocation, free 30.02 GB total 31.75 GB [WARNING] gemm_config.in is not found; using default GEMM algo [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.0.layer.0.SelfAttention.relative_attention_bias.weight.0.bin only has 768, but request 1536, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.0.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.0.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.0.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.0.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.0.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.0.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.1.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.1.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.1.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.1.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.1.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.1.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.2.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.2.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.2.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.2.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.2.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.2.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.3.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.3.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.3.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.3.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.3.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.3.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.4.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.4.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.4.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.4.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.4.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.4.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.5.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.5.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.5.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.5.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.5.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.5.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.6.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.6.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.6.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.6.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.6.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.6.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.7.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.7.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.7.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.7.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.7.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.7.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.8.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.8.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.8.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.8.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.8.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.8.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.9.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.9.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.9.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.9.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.9.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.9.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.10.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.10.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.10.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.10.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.10.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.10.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.11.layer.0.SelfAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.11.layer.0.SelfAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.11.layer.0.SelfAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.11.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.11.layer.1.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//encoder.block.11.layer.1.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.0.layer.0.SelfAttention.relative_attention_bias.weight.0.bin only has 768, but request 1536, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.0.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.0.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.0.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.0.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.0.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.0.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.0.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.0.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.1.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.1.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.1.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.1.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.1.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.1.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.1.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.1.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.2.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.2.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.2.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.2.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.2.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.2.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.2.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.2.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.3.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.3.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.3.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.3.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.3.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.3.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.3.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.3.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.4.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.4.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.4.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.4.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.4.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.4.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.4.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.4.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.5.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.5.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.5.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.5.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.5.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.5.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.5.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.5.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.6.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.6.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.6.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.6.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.6.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.6.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.6.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.6.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.7.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.7.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.7.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.7.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.7.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.7.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.7.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.7.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.8.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.8.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.8.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.8.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.8.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.8.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.8.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.8.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.9.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.9.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.9.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.9.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.9.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.9.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.9.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.9.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.10.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.10.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.10.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.10.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.10.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.10.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.10.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.10.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.11.layer.0.SelfAttention.qkv.weight.0.bin only has 3538944, but request 7077888, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.11.layer.0.SelfAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.11.layer.1.EncDecAttention.q.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.11.layer.1.EncDecAttention.k.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.11.layer.1.EncDecAttention.v.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.11.layer.1.EncDecAttention.o.weight.0.bin only has 1179648, but request 2359296, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.11.layer.2.DenseReluDense.wi.weight.0.bin only has 4718592, but request 9437184, loading model fails! [WARNING] file /workspace/build/fastertransformer_backend/all_models/t5/fastertransformer/1/2-gpu//decoder.block.11.layer.2.DenseReluDense.wo.weight.0.bin only has 4718592, but request 9437184, loading model fails! After Loading Model: after allocation, free 28.36 GB total 31.75 GB I0413 05:18:03.210661 1647 libfastertransformer.cc:580] Model instance is created on GPU Tesla V100-SXM2-32GB I0413 05:18:03.210963 1647 model_repository_manager.cc:960] successfully loaded 'fastertransformer' version 1 I0413 05:18:03.211133 1647 server.cc:490] +-------------------+-----------------------------------------------------------------------------+------+ | Backend | Config | Path | +-------------------+-----------------------------------------------------------------------------+------+ | pytorch | /opt/tritonserver/backends/pytorch/libtriton_pytorch.so | {} | | onnxruntime | /opt/tritonserver/backends/onnxruntime/libtriton_onnxruntime.so | {} | | tensorflow | /opt/tritonserver/backends/tensorflow1/libtriton_tensorflow1.so | {} | | fastertransformer | /opt/tritonserver/backends/fastertransformer/libtriton_fastertransformer.so | {} | +-------------------+-----------------------------------------------------------------------------+------+
I0413 05:18:03.211178 1647 server.cc:533] +-------------------+---------+--------+ | Model | Version | Status | +-------------------+---------+--------+ | fastertransformer | 1 | READY | +-------------------+---------+--------+
I0413 05:18:03.211283 1647 tritonserver.cc:1620] +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+ | Option | Value | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+ | server_id | triton | | server_version | 2.6.0 | | server_extensions | classification sequence model_repository schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_tensor_data statistics | | model_repository_path[0] | /workspace/build/fastertransformer_backend/all_models/t5 | | model_control_mode | MODE_NONE | | strict_model_config | 1 | | pinned_memory_pool_byte_size | 268435456 | | cuda_memory_pool_byte_size{0} | 67108864 | | min_supported_compute_capability | 6.0 | | strict_readiness | 1 | | exit_timeout | 30 | +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+
I0413 05:18:03.212775 1647 grpc_server.cc:3979] Started GRPCInferenceService at 0.0.0.0:8001 I0413 05:18:03.213046 1647 http_server.cc:2717] Started HTTPService at 0.0.0.0:8000 I0413 05:18:03.264200 1647 http_server.cc:2736] Started Metrics Service at 0.0.0.0:8002 W0413 05:20:09.883614 1647 libfastertransformer.cc:1344] model fastertransformer, instance fastertransformer_0, executing 1 requests W0413 05:20:09.883642 1647 libfastertransformer.cc:664] TRITONBACKEND_ModelExecute: Running fastertransformer_0 with 1 requests W0413 05:20:09.883651 1647 libfastertransformer.cc:718] get total batch_size = 1 W0413 05:20:09.883659 1647 libfastertransformer.cc:1018] get input count = 2 W0413 05:20:09.883670 1647 libfastertransformer.cc:1085] collect name: INPUT_ID size: 84 W0413 05:20:09.883676 1647 libfastertransformer.cc:1085] collect name: REQUEST_INPUT_LEN size: 4 W0413 05:20:09.883680 1647 libfastertransformer.cc:1091] the data is in CPU W0413 05:20:09.883683 1647 libfastertransformer.cc:1095] the data is in CPU W0413 05:20:09.883689 1647 libfastertransformer.cc:974] before ThreadForward 0 W0413 05:20:09.883787 1647 libfastertransformer.cc:976] after ThreadForward 0 W0413 05:20:09.883952 1647 libfastertransformer.cc:855] Start to forward W0413 05:20:10.796207 1647 libfastertransformer.cc:858] Stop to forward W0413 05:20:10.796297 1647 libfastertransformer.cc:1118] get output_tensors 0: OUTPUT0 W0413 05:20:10.796311 1647 libfastertransformer.cc:1124] index: 0 get output_type: INT32 W0413 05:20:10.796318 1647 libfastertransformer.cc:1138] output shape: [1 1 528 ] W0413 05:20:10.796392 1647 libfastertransformer.cc:1118] get output_tensors 1: OUTPUT1 W0413 05:20:10.796398 1647 libfastertransformer.cc:1124] index: 1 get output_type: INT32 W0413 05:20:10.796404 1647 libfastertransformer.cc:1138] output shape: [1 1 ] W0413 05:20:10.796434 1647 libfastertransformer.cc:1155] PERFORMED GPU copy: YES W0413 05:20:10.796442 1647 libfastertransformer.cc:804] get response size = 1 W0413 05:20:10.796491 1647 libfastertransformer.cc:817] response is sent W0413 05:20:10.798008 1647 libfastertransformer.cc:1344] model fastertransformer, instance fastertransformer_0, executing 1 requests W0413 05:20:10.798017 1647 libfastertransformer.cc:664] TRITONBACKEND_ModelExecute: Running fastertransformer_0 with 1 requests W0413 05:20:10.798024 1647 libfastertransformer.cc:718] get total batch_size = 1 W0413 05:20:10.798032 1647 libfastertransformer.cc:1018] get input count = 2 W0413 05:20:10.798041 1647 libfastertransformer.cc:1085] collect name: INPUT_ID size: 144 W0413 05:20:10.798049 1647 libfastertransformer.cc:1085] collect name: REQUEST_INPUT_LEN size: 4 W0413 05:20:10.798054 1647 libfastertransformer.cc:1091] the data is in CPU W0413 05:20:10.798059 1647 libfastertransformer.cc:1095] the data is in CPU W0413 05:20:10.798066 1647 libfastertransformer.cc:974] before ThreadForward 0 W0413 05:20:10.798123 1647 libfastertransformer.cc:976] after ThreadForward 0 W0413 05:20:10.798139 1647 libfastertransformer.cc:855] Start to forward W0413 05:20:11.703894 1647 libfastertransformer.cc:858] Stop to forward W0413 05:20:11.703991 1647 libfastertransformer.cc:1118] get output_tensors 0: OUTPUT0 W0413 05:20:11.704004 1647 libfastertransformer.cc:1124] index: 0 get output_type: INT32 W0413 05:20:11.704011 1647 libfastertransformer.cc:1138] output shape: [1 1 528 ] W0413 05:20:11.704069 1647 libfastertransformer.cc:1118] get output_tensors 1: OUTPUT1 W0413 05:20:11.704075 1647 libfastertransformer.cc:1124] index: 1 get output_type: INT32 W0413 05:20:11.704085 1647 libfastertransformer.cc:1138] output shape: [1 1 ] W0413 05:20:11.704111 1647 libfastertransformer.cc:1155] PERFORMED GPU copy: YES W0413 05:20:11.704117 1647 libfastertransformer.cc:804] get response size = 1 W0413 05:20:11.704168 1647 libfastertransformer.cc:817] response is sent W0413 05:20:11.705480 1647 libfastertransformer.cc:1344] model fastertransformer, instance fastertransformer_0, executing 1 requests W0413 05:20:11.705489 1647 libfastertransformer.cc:664] TRITONBACKEND_ModelExecute: Running fastertransformer_0 with 1 requests W0413 05:20:11.705495 1647 libfastertransformer.cc:718] get total batch_size = 1 W0413 05:20:11.705502 1647 libfastertransformer.cc:1018] get input count = 2 W0413 05:20:11.705512 1647 libfastertransformer.cc:1085] collect name: INPUT_ID size: 164 W0413 05:20:11.705520 1647 libfastertransformer.cc:1085] collect name: REQUEST_INPUT_LEN size: 4 W0413 05:20:11.705526 1647 libfastertransformer.cc:1091] the data is in CPU W0413 05:20:11.705531 1647 libfastertransformer.cc:1095] the data is in CPU W0413 05:20:11.705537 1647 libfastertransformer.cc:974] before ThreadForward 0 W0413 05:20:11.705588 1647 libfastertransformer.cc:976] after ThreadForward 0 W0413 05:20:11.705599 1647 libfastertransformer.cc:855] Start to forward W0413 05:20:12.610362 1647 libfastertransformer.cc:858] Stop to forward W0413 05:20:12.610452 1647 libfastertransformer.cc:1118] get output_tensors 0: OUTPUT0 W0413 05:20:12.610465 1647 libfastertransformer.cc:1124] index: 0 get output_type: INT32 W0413 05:20:12.610471 1647 libfastertransformer.cc:1138] output shape: [1 1 528 ] W0413 05:20:12.610519 1647 libfastertransformer.cc:1118] get output_tensors 1: OUTPUT1 W0413 05:20:12.610525 1647 libfastertransformer.cc:1124] index: 1 get output_type: INT32 W0413 05:20:12.610531 1647 libfastertransformer.cc:1138] output shape: [1 1 ]
------------Question 1------------:
Does the version 20.12 support T5 multi-gpu?
I start the server with mpi -np 2, it doesn't work. what should i do ? terminate called after throwing an instance of 'std::runtime_error' what(): [FT][ERROR] Assertion fail: /workspace/build/fastertransformer_backend/src/libfastertransformer.cc:552
[zjk3-chatbot-g8v100-node02:03802] *** Process received signal *** [zjk3-chatbot-g8v100-node02:03802] Signal: Aborted (6) [zjk3-chatbot-g8v100-node02:03802] Signal code: (-6) [zjk3-chatbot-g8v100-node02:03802] [ 0] /usr/lib/x86_64-linux-gnu/libpthread.so.0(+0x143c0)[0x7f25e158e3c0] [zjk3-chatbot-g8v100-node02:03802] [ 1] terminate called after throwing an instance of 'std::runtime_error' what(): [FT][ERROR] Assertion fail: /workspace/build/fastertransformer_backend/src/libfastertransformer.cc:552
------------Question 2------------: If i want to start 2 instance in 2-gpus, every gpu can serve independently, what should i do?
- The error happens here https://github.com/triton-inference-server/fastertransformer_backend/blob/dev/v1.1_beta/src/libfastertransformer.cc#L552, which means your tensor_para_size_ * pipeline_para_size_ != number of GPU you have. You need to use CUDA_VISIBLE_DEVICES to setup what GPU you want to use.
- For multi-gpu serving, we don't verify the multiple instances feature and assume it is not supported. In multi-gpu inference scenario, we assume we occupy the whole GPU and hence we cannot put multiple instances on it.
I remove the some installation which leads to error in older version, you can try again.
Another question , when i start the FT backend T5 model
when i translate en2de by using (python /workspace/fastertransformer_backend/tools/t5_utils/t5_end_to_end_test.py
) , the i get this, it's weird.

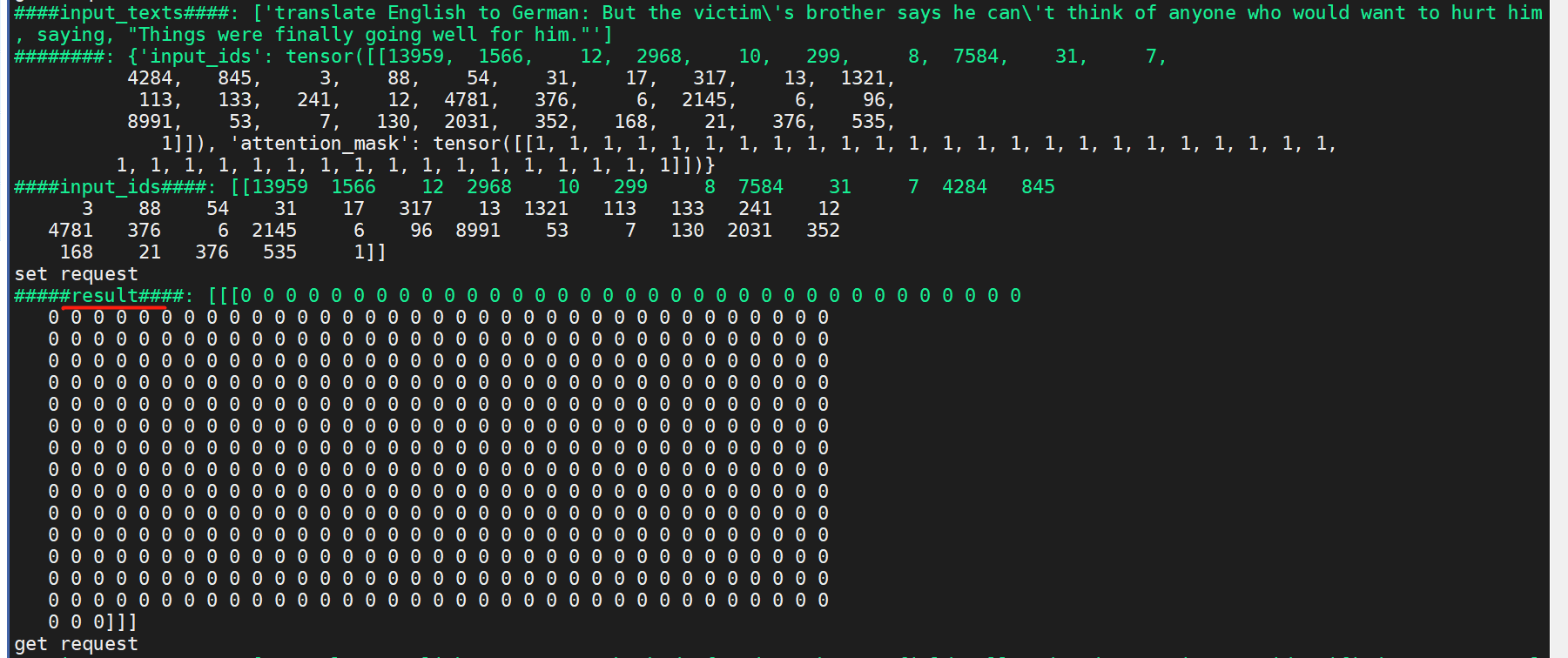
I start the serving with just 1 gpu, but with 2 gpus in convert process.
Then i change the convert gpu to 1 and start serving with 1 gpu , then it looks right,

Hi, i still have some question.
- Is the huggingface T5 v1.1 (https://huggingface.co/google/t5-v1_1-base) supported by ft triton backend ?
- Megatron-LM T5 is supported according to the readme, but i want to use T5 in my dialogue generation task like translation task, but i haven't find the finetune task like translation in Megatron-LM T5. (Maybe i can use the T5 like standard transformer , no need to pretrain, and i just use it in my translation. )
- From the model card, T5 v1.1 uses the GEGLU, which is not supported in FasterTransformer now.
- You should ask this question in the Megatron-LM repo. We are not sure the details of Megatron-LM.