[BUG] TypeError when using Multi-GPU and workflow ops to datetime
Describe the bug
TypeError: Improperly matched output dtypes detected in event_time_ts, int64 and datetime64[s]
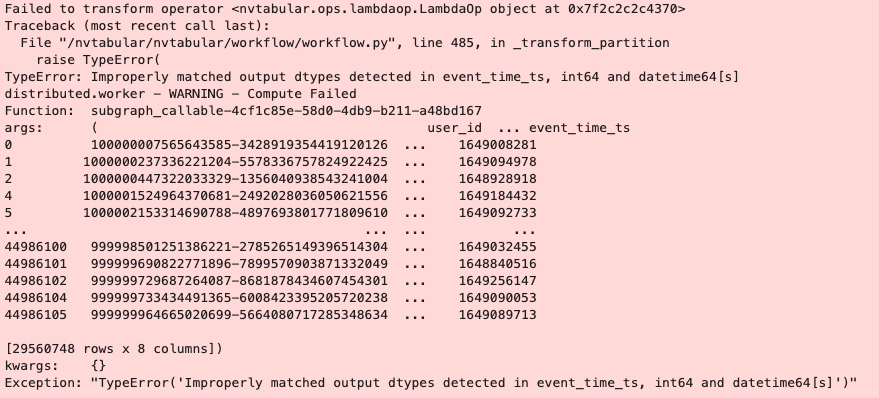
Steps/Code to reproduce bug
session_time = ( session_ts >> nvt.ops.LambdaOp(lambda col: cudf.to_datetime(col, unit='s')) >> nvt.ops.Rename(name = 'event_time_dt') )
dataset = nvt.Dataset(df) workflow = nvt.Workflow(filtered_sessions) workflow.fit(dataset) sessions_gdf = workflow.transform(dataset).to_ddf()
sessions_gdf.head(2)
Expected behavior When I use 1 GPU, it works well. But when I choose to use 2 GPUs, this error shows up.
@liguo88 which NVT pipeline are you running? is it from Transformers4Rec repo examples? can you please provide a simple reproducible example with a small synthetic dataset you can generate?
@rnyak Thank you for your response. Yes it is from Transfomers4Rec repo examples. It woks well for single GPU, but having previous issue for 2 GPUs.
Fake Data:
 Here is an example:
Here is an example:
import os
import cupy as cp
import numpy as np
import cudf
import nvtabular as nvt
from dask.distributed import Client
from dask_cuda import LocalCUDACluster
import dask_cudf
import transformers4rec
cluster = LocalCUDACluster() # by default use all GPUs in the node. I have two.
client = Client(cluster)
df = cudf.read_parquet('test-fake.parquet')
#NVT workflow
cat_feats = ['l1_brand'] >> nvt.ops.Categorify(start_index=1)
#create time features
session_ts = ['event_time_ts']
session_time = (
session_ts >>
nvt.ops.LambdaOp(lambda col: cudf.to_datetime(col, unit='s')) >>
nvt.ops.Rename(name = 'event_time_dt')
)
sessiontime_weekday = (
session_time >>
nvt.ops.LambdaOp(lambda col: col.dt.weekday) >>
nvt.ops.Rename(name ='et_dayofweek')
)
def get_cycled_feature_value_sin(col, max_value):
value_scaled = (col + 0.000001) / max_value
value_sin = np.sin(2*np.pi*value_scaled)
return value_sin
def get_cycled_feature_value_cos(col, max_value):
value_scaled = (col + 0.000001) / max_value
value_cos = np.cos(2*np.pi*value_scaled)
return value_cos
weekday_sin = sessiontime_weekday >> (lambda col: get_cycled_feature_value_sin(col+1, 7)) >> nvt.ops.Rename(name = 'et_dayofweek_sin')
weekday_cos= sessiontime_weekday >> (lambda col: get_cycled_feature_value_cos(col+1, 7)) >> nvt.ops.Rename(name = 'et_dayofweek_cos')
time_features = (
session_time+
sessiontime_weekday +
weekday_sin +
weekday_cos
)
groupby_feats = ['user_id', 'event_time_ts'] + cat_feats + time_features
groupby_features = groupby_feats >> nvt.ops.Groupby(
groupby_cols=["user_id"],
sort_cols=["event_time_ts"],
aggs={
'l1_brand': ["list", "count"],
'event_time_ts': ["first"],
'event_time_dt': ["first"],
'et_dayofweek_sin': ["list"],
'et_dayofweek_cos': ["list"]
},
name_sep="-")
groupby_features_list = groupby_features[
'l1_brand-list',
'et_dayofweek_sin-list',
'et_dayofweek_cos-list'
]
SESSIONS_MAX_LENGTH = 30
MINIMUM_SESSION_LENGTH = 3
groupby_features_trim = groupby_features_list >> nvt.ops.ListSlice(-SESSIONS_MAX_LENGTH) >> nvt.ops.Rename(postfix = '_seq')
# calculate session day index based on 'timestamp-first' column
day_index = ((groupby_features['event_time_dt-first']) >>
nvt.ops.LambdaOp(lambda col: (col - col.min()).dt.days +1) >>
nvt.ops.Rename(f = lambda col: "day_index")
)
selected_features = groupby_features['user_id', 'l1_brand-count'] + groupby_features_trim + day_index
filtered_sessions = selected_features >> nvt.ops.Filter(f=lambda df: df["l1_brand-count"] >= MINIMUM_SESSION_LENGTH)
dataset = nvt.Dataset(df)
workflow = nvt.Workflow(filtered_sessions)
workflow.fit(dataset)
sessions_gdf = workflow.transform(dataset).to_ddf()
print(sessions_gdf.head(2))
@liguo88 can you pull the latest container merlin-pytorch:22.10 and tell us if the issue still occurs or not? thanks.