[BUG] Incorrect Reverse Mapping of Categories
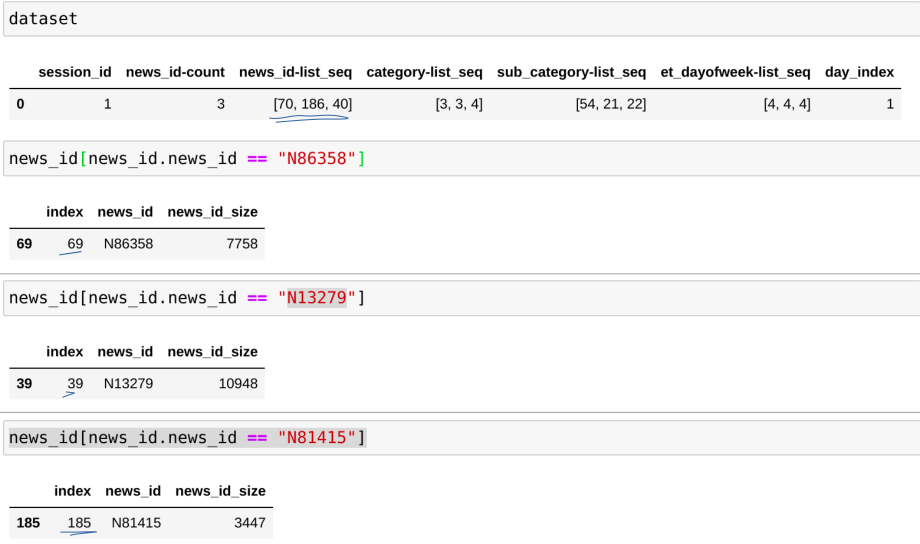
I transformed a data set using a saved NVTabular workflow. The dateset contains the following news_ids = ["N86358", "N81415", "N13279"].
The transformed data set converts the news_id into integer news ids. The transformed data set looks like this

And when I try to get to the original news ids than the result does not match to the news ids mentioned in the above list.
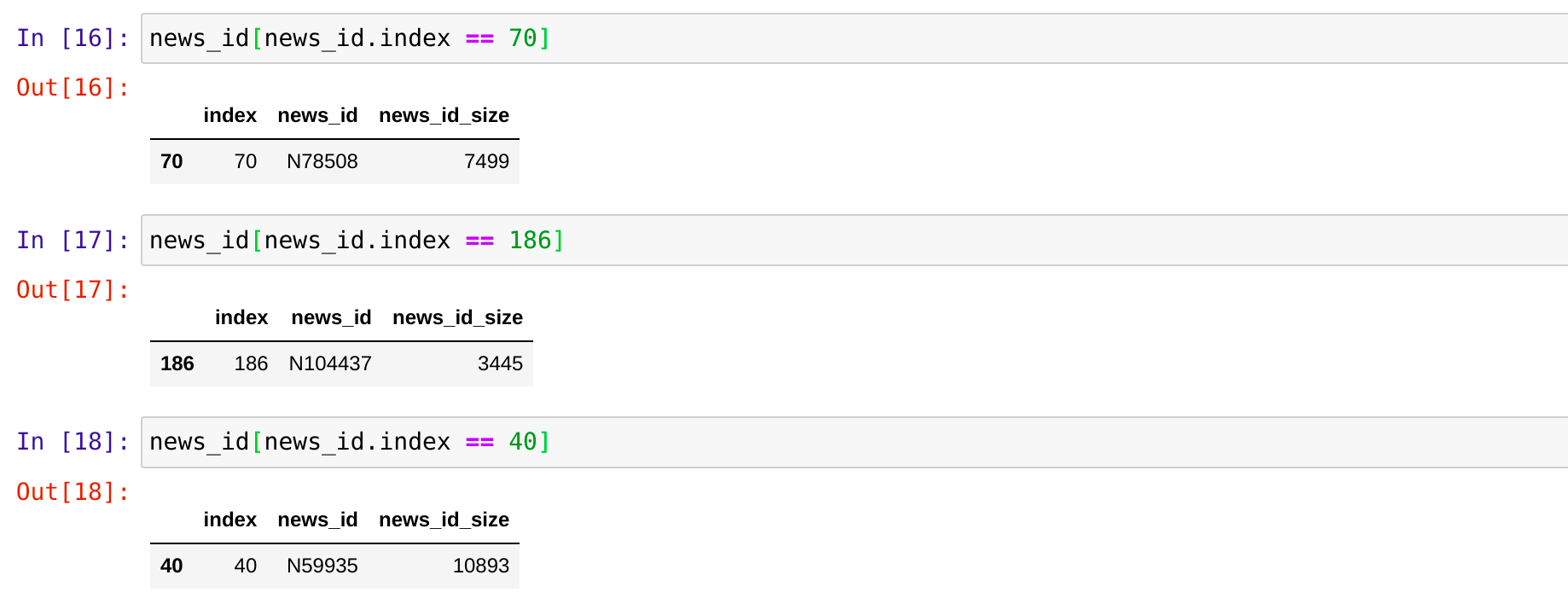
Also another thing I have noticed is that if I search for these **news_ids = ["N86358", "N81415", "N13279"]**` in the data frame created from the unique.news_id.parquet file than there is always a difference of 1 between the converted data set news ids and the one i get if i do a manual search in the parquet file
O.S: Ubuntu 20 NVtabular version 0.9.0
NVTabular doesn't yet have an explicit reverse mapping from categorical ids to their original values so this seems like a reasonable workaround, but there's one thing to be aware of that makes it a bit less straightforward than it would seem:
By default, the Categorify operator reserves index 0 to encode null/missing values, which is likely the source of the off-by-one issue you're seeing.
@karlhigley thank you for your response, yes I am aware that it encodes the null values to 0 by default. For example when I Ioad the mappings from the parquet file l get the following output. At index 0 we can see null values are encoded
import cudf
news_id = cudf.read_parquet("./data/data_chunks/workflow_etl_mind_2/categories/unique.news_id.parquet")
news_id = news_id.reset_index()
news_id.head()
| index | news_id | news_id_size |
|---|---|---|
| 0 | NA | 1 |
| 1 | N98178 | 60638 |
| 2 | N32154 | 47078 |
| 3 | N30899 | 47003 |
| 4 | N47257 | 42147 |
So i am assuming now if the integer id after transformation is 70 then when I search for the 70th index in the the news_id data frame then its going to be index 69 right because in python indexes start from 0.
Please let me know if my understanding is correct?
@SaadAhmed433 can you please generate a minimal reproducible example with your NVT pipeline. you can create a simple fake dataset of 10-20 rows and add your NVT code snippet, so we can better answer your question and reproduce the issue. Thanks.
for this statement
So i am assuming now if the integer id after transformation is 70 then when I search for the 70th index in the the news_id data frame then its going to be index 69 right because in python indexes start from 0.
the index in the news_id df actually means the new encoded id for your original news_id . so you should search for the exact value here.
Sure, @rnyak , please see the code below.
The dataset used can be downloaded from here
import cudf
import nvtabular as nvt
#load the dataset
data = cudf.read_csv("./fake_data.csv")
data.head()
| news_id | category | sub_cat |
|---|---|---|
| N23144 | health | weightloss |
| N86255 | health | medical |
| N93187 | news | newsworld |
| N75236 | health | voices |
| N99744 | health | medical |
#define the categorical features for applying the Categorify op
cat_feats = ["news_id", "category", "sub_cat"] >> nvt.ops.Categorify(start_index=1)
#instantiate the workflow
workflow = nvt.Workflow(cat_feats)
#create a dataset object
dataset = nvt.Dataset(data)
#applu and transform to get a dataframe
workflow.fit(dataset)
transfomed_df = workflow.transform(dataset).to_ddf()
#save the workflow
workflow_path = './test_workflow'
workflow.save(workflow_path)
Now I print the transformed dataset and compare
transformed_df = transformed_df.compute()
transformed_df.head()
| news_id | category | sub_cat |
|---|---|---|
| 38 | 4 | 12 |
| 93 | 4 | 23 |
| 96 | 3 | 5 |
| 82 | 4 | 11 |
| 101 | 4 | 23 |
news_id_mapping = cudf.read_parquet("./test_workflow/categories/unique.news_id.parquet")
category_mapping = cudf.read_parquet("./test_workflow/categories/unique.category.parquet")
sub_cat = cudf.read_parquet("./test_workflow/categories/unique.sub_cat.parquet")
Now when I select the 38 integer id in thetransformed_df and search it in the news_id_mapping data frame I always have to subtract 1 from the integer id otherwise it will give me incorrect mapping. The same happens with every other column.
print(news_id_mapping[news_id_mapping.index == 37], "\n")
print(category_mapping[category_mapping.index == 3], "\n")
print(sub_cat[sub_cat.index == 11], "\n")

If you select the exact ids you will get the wrong results.
For e.g
print(news_id_mapping[news_id_mapping.index == 38], "\n")
print(category_mapping[category_mapping.index == 4], "\n")
print(sub_cat[sub_cat.index == 12], "\n")

@SaadAhmed433 Now when I select the 38 integer id in thetransformed_df and search it in the news_id_mapping data frame I always have to subtract 1 from the integer id otherwise it will give me incorrect mapping.
this is because you add start_index=1 in the Categorify. If you do not add it, you can use the exact_id.
we will look into that and fix it. thanks.
This is due to Categorify(start_index) is not generating the mappings in the unique parquet files as expected.
Closing this one. The related bug ticket is here: https://github.com/NVIDIA-Merlin/NVTabular/issues/1544