HugeCTR
 HugeCTR copied to clipboard
HugeCTR copied to clipboard
SparseEmbedding layer to be able to accept multiple input column names in bottom_name argument
Is your feature request related to a problem? Please describe.
- In
hugectr.SparseEmbeddinglayer, only single input feature name can be provided in thebottom_nameargument. There are scenarios where multiple feature columns have to share the same embedding layer. - For example, in a DNN based recommendation model [paper], there are two feature columns --
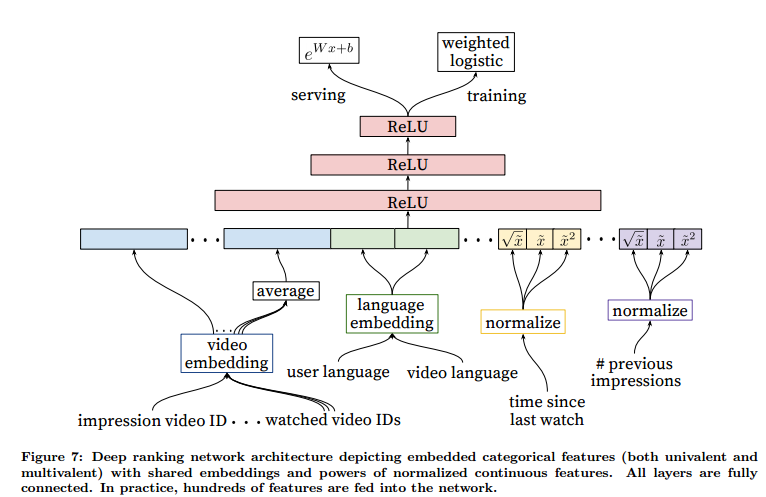
impression_video_idandwatched_video_ids, where the former is a univalent categorical feature column and the latter one is a multivalent categorical feature column. They both share the same embedding layer,video_embeddingas shown in the below figure. Similar case foruser_languageandvideo_language.
Describe the solution you'd like
As you can pass multiple feature column names in other layers like hugectr.DenseLayer, SparseEmbedding layer should also be able to accept a list in bottom_names argument, and return embeddings for values in all the columns passed in that list.
Hi @ayushjn20, thanks for your feature request.
- Workaround
The workaround is to perceive impression_video_id and watched_video_ids as a whole (assume that impression_video_id is univalent and watched_video_ids is 10-multivalent, and there are totally 1000 movies). Similarly, we can regard user_language and video_language as a whole (assume they are both univalent and there are totally 50 languages).
reader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Parquet,
slot_size_array = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1000, 0, 50],
...)
model.add(
hugectr.Input(...,
data_reader_sparse_param_array =
[hugectr.DataReaderSparseParam("impression_watched_video_ids", 1, True, 11),
hugectr.DataReaderSparseParam("user_video_languages", 1, True, 2)]
)
)
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = ???,
embedding_vec_size = 32,
combiner = "sum",
sparse_embedding_name = "video_embedding",
bottom_name = "impression_watched_video_ids"))
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = ???,
embedding_vec_size = 16,
combiner = "sum",
sparse_embedding_name = "language_embedding",
bottom_name = "user_video_languages"))
The dimension of video_embedding is (~, 11, 32) and the dimension of language_embedding is (~, 2, 16), which can be consistent with the paper. Please NOTE that LocalizedSlotSparseEmbeddingHash can not be used with this workaround, and the configuration for slot_size_array is a little bit tricky and confusing given that the first 11 entries in slot_size_array actually belong to the same embedding table and the last 2 entries are of the same table.
- Future Plan
In the future, we are going to support
concatcombiner in the embedding layer, and enable internal mapping mechanism from the configured columns to the actual HugeCTR slot. Both will make it much easier in terms of usage to support different columns sharing the same embedding table.
Hi @KingsleyLiu-NV ,
Thank you for your suggestions. We were successful in getting embeddings using the above mentioned ideas. We made a slight modification to your implementation for our purpose,
reader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Parquet,
slot_size_array = [0, 1000, 0, 50],
...)
model.add(
hugectr.Input(...,
data_reader_sparse_param_array =
[hugectr.DataReaderSparseParam("impression_watched_video_ids", [1, 10], False, 2),
hugectr.DataReaderSparseParam("user_video_languages", [1, 1], True, 2)]
)
)
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = ???,
embedding_vec_size = 32,
combiner = "mean",
sparse_embedding_name = "video_embedding",
bottom_name = "impression_watched_video_ids"))
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = ???,
embedding_vec_size = 16,
combiner = "mean",
sparse_embedding_name = "language_embedding",
bottom_name = "user_video_languages"))
An example input which is compatible with the above configuration is,
{
"impression_video_id": 27,
"watched_video_ids": [120, 239, 100, 2, 10], # This will be an array of max len 10.
"user_language": 12,
"item_language": 16,
...
}
This way, we do not have to split the watch_video_ids into 10 different inputs (slots). Although, it does not gives us individual embeddings for all those 11 (1 impression and 10 watched) video ids, rather the output will be of shape (~, 2, 32), where the first 32 dim vector is the video embedding of impression_video_id and the second 32 dim vector is the mean vector of those 10 watched_video_ids, which is what we want as per the paper.
@ayushjn20 Glad to hear that the workaround helps. As you have mentioned, we can only get the mean of the embeddings of 10 watched_video_ids if we put them in the same slot. To get the output of shape (batch_size, 10, 32) (which can be extracted from video_embedding of (batch_size, 11, 32)), you need to split them into 10 slots (padding could be required here since 10 is the max_len of watched_video_ids). This inconvenience can be saved in the future when concat combiner is enabled for the embeddings in the same slot.