REopt_API
 REopt_API copied to clipboard
REopt_API copied to clipboard
API-server deployment updates and memory limits, off-grid, emissions/RE, validator fixes
This PR includes:
- Changes to API-server deployment code made by @GUI to update it to the latest Rancher/Kubernetes version/environment which should help with deployment issues. Also, there is changes to the pod memory limits (and other things) to try to mitigate server memory overload. See https://github.com/NREL/REopt_API/pull/351 for description.
- Offgrid functionality from https://github.com/NREL/REopt_API/pull/343
- Emissions/RE functionality from https://github.com/NREL/REopt_API/pull/354
- Validator fixes from https://github.com/NREL/REopt_API/pull/350
TODO:
- Make a version for the CHANGELOG.md heading, remove the "Develop" under the previous release/version.
- Deploy to develop server
Thank you for your submission! We really appreciate it. Like many open source projects, we ask that you all sign our Contributor License Agreement before we can accept your contribution.
5 out of 6 committers have signed the CLA.
:white_check_mark: zolanaj
:white_check_mark: hdunham
:white_check_mark: adfarth
:white_check_mark: rathod-b
:white_check_mark: Bill-Becker
:x: GUI
You have signed the CLA already but the status is still pending? Let us recheck it.
@GUI this PR includes only the changes you made to the deployment scripts and memory limit tweaks. I tried to deploy the develop branch with these changes to the development server (Test Ranch), but it failed because it seems to have that "namespace conflict" issue that we've had in the past where the previous undeploy didn't fully remove the namespace. I've submitted an ITS ticket to try to fully remove the develop branch namespace from test ranch. The master branch deploy to test ranch has also failed recently, but the console logs from that deploy failure looks like something you may have fixed with updating werf, etc. I was hoping to get that develop branch deploy issue fixed before merging into master with this PR, but I'm also not opposed to merging anyway if that means progress deploying master with the updates/memory things, if we are confident the deploy issue is just from the incomplete namespace removal.
@GUI ITS was able to fully delete the develop branch namespace on test ranch, and after trying to deploy again I'm now getting a deploy failure that looks related to helm upgrading from 2 to 3. It also kind of looks like it still has some memory of the develop branch namespace because it says: "Found existing helm 2 release "reopt-api-development-develop", will try to render helm 3 templates and migrate existing release resources to helm 3" - so maybe they didn't fully delete it?
Also tried deploying the develop branch to staging to see if that different environment with the updates would work, but that also failed. I can't quite make out the cause of this deploy failure, which says "Unable to connect to the server: context deadline exceeded (Client.Timeout exceeded while awaiting headers)".
@Bill-Becker: The error related to deploying to development was due to some pieces of the Werf 1.1 deployment remaining, but since everything was purged from the main namespace, it was confused, since it thought there were things to upgrade that didn't exist. Once I manually cleaned up the remaining pieces, then the deployment to development appears to have succeeded.
For more context, Werf 1.1 uses a reopt-api-development-helm-release-storage namespace to store configmaps that contain details about each depoloyment. So those configmaps need to also be deleted if you've manually deleted the associated namespace for a deploy. Werf 1.2 completely does away with the need for this namespace, so once everything is upgraded, this shouldn't be an issue. I manually removed the offending configmaps with the following command:
kubectl -n reopt-api-development-helm-release-storage delete configmap/reopt-api-development-develop.v1 configmap/reopt-api-development-develop.v2 configmap/reopt-api-development-develop.v3 configmap/reopt-api-development-develop.v4 configmap/reopt-api-development-develop.v5 configmap/reopt-api-development-develop.v6 configmap/reopt-api-development-develop.v7
The following configmaps still exist. These may be fine to exist, if these branches are still deployed and you simply merge in these changes and let the Werf upgrade take place. However, these may need to be manually purged if the associated namespace has also been manually deleted.
$ kubectl -n reopt-api-development-helm-release-storage get configmap
NAME DATA AGE
kube-root-ca.crt 1 25d
reopt-api-development-hes-nuclear.v1 1 298d
reopt-api-development-hybrid-inverter.v1 1 172d
reopt-api-development-hybrid-inverter.v2 1 146d
reopt-api-development-nova-analysis3.v1 1 181d
reopt-api-development-nova-analysis4.v1 1 181d
reopt-api-development-offgrid-electrolyzer.v1 1 298d
reopt-api-development.v1 1 418d
reopt-api-development.v2 1 306d
reopt-api-development.v3 1 265d
reopt-api-development.v4 1 248d
reopt-api-development.v5 1 237d
reopt-api-development.v6 1 215d
reopt-api-development.v7 1 121d
Regarding the Unable to connect to the server: context deadline exceeded errors when deploying to staging, I think this is perhaps still fallout from last Wednesday when the staging/production went haywire. While restarting things seemed to stabilize the app, I know when I last interacted with things on Wednesday, I saw seeing similarly strange timeouts when trying to actually run any kubernetes commands. So despite the app seeming stable now, I think something is still perhaps messed up at the cluster level that ITS will need to resolve, because currently I can't really run any kubernetes commands against it without timeouts:
$ kubectl -n reopt-api-staging-develop get all
Unable to connect to the server: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
I don't really know what's going on beyond these strange timeouts, though, but I think that will prevent any new deployments to staging or production. Did you already have a ticket open with ITS about some of this? Or did you want me to open up a new ticket?
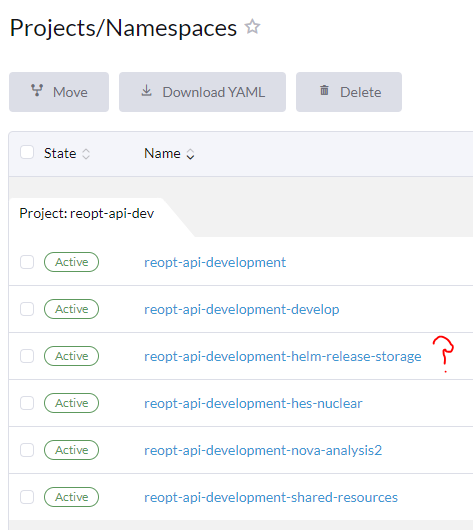
@GUI I'm pasting in the image I sent in the other email about the persisting databases of branches we (don't) want, and it looks like all except the hes-nuclear branch can have the configmaps deleted. I didn't know about the versioning that it's doing. I'm assuming we just want to keep the highest version if there is a branch that we want to keep with multiple versions. Does it create a new version when we deploy a branch that's already been deployed?
I don't have an ITS ticket open for the connection error, and that would be great if you could ping them and CC me for my info. Do we need to wait until that is resolved before we merge this into master and deploy? I assume so if you need to do any manual deleting of configmaps for master on the staging/production servers.
@Bill-Becker, ah, sorry I missed this earlier this week. I opened a ticket with ITS and copied you. But yes, we'll need to wait for them to resolve the cluster issue before we can deploy to staging/production.
Regarding the configmaps, I've manually cleaned up the remaining ones for other branches. If we run into any issues upgrading branches, we can revisit this, but once all branches are on Werf 1.2, then these should be totally defunct, so hopefully we won't have to worry about them much longer.
@hdunham Thanks! Unfortunately @GUI is actually waiting on ITS and their request to Rancher to try to fix the issue that they are having. Hopefully we'll get an update soon, but it's always uncertain when relying on external help!
@Bill-Becker: The staging and production cluster appear to be fixed by ITS now, so I was able to deploy successfully to staging (after a small tweak due to the newer version of k8s they're now running: https://github.com/NREL/REopt_API/pull/353/commits/2e2901eaa9329ac977c7db850d5b6c6b7a7df334). So if you wall want to review anything there or test any other staging/production deploys, I think things should finally be back in action.
@GUI Great news! I know Rancher was going to do a reboot of the cluster at 5pm yesterday, and then their platform engineering support was available to help - it would be good to at least understand the high level cause and fix, so we're more informed next time.
@hdunham The deployment stuff seems to be working, so let's work toward merging this. It looks like you made a lot of the updates to the Changelog - let me know if that is all set or we need to add more (the TODO is still in the description).
@hdunham Can you prioritize this since it should just be adding any additional changes to the CHANGELOG.md, and then we can get these server memory improvements on production?
@hdunham Can you prioritize this since it should just be adding any additional changes to the CHANGELOG.md, and then we can get these server memory improvements on production?
@Bill-Becker I'd finished making changed and approved the PR, the TODO was just meant to be a reminder for you to change "Develop" to the next version # right before merging. But I went ahead and did that just now, and I also removed both TODOs since you said you deployed successfully as well.