readabs
 readabs copied to clipboard
readabs copied to clipboard
ABS API interface
@baslat @MattCowgill Here's what I've got.
A few thoughts right off the bat:
-
I think the addition of
labelledas a dependency is well-justified. Storing the labels in additional columns would clutter the tables and distance them from the way they appear in the data explorer interface. -
The 'datakey' business is very fiddly. The minimalistic approach I've taken below is OK, but I think there's a lot of room to do better. One idea would be to accept a named list input and then construct the datakey string internally by matching the list names against the datastructure.
-
I think it would be good to offer an option to run chunked queries as you've done @baslat. We could leave it to the user to decide which variable to batch on (and maybe how many values to include per batch?) and then pull the values out of
abs_datastructure()
Cheers :)
Hey @kinto-b , I haven't had time for a thorough look through, but I thought it would be good to start a conversation and get a better understanding of your approach and we can combine forces. From my first look through, it seems like the interface to your functions in wholly in R (versus my implementation which requires the user to go to the ABS Data Explorer website); is that correct? Can your functions also take a user-provided query URL?
Re labelled, I agree that having multiple columns indicating code and label is annoying. However, I settled on using that output because of the ABS geographies, where I would often want to join or wrangle data based on either names or codes. I wanted to make sure if I was querying geographic data, the results included from geography name and geography code as columns. What are your thoughts on this issue?
Re datakeys: I agree that they are not a intuitive approach. One of my guiding principles was to not expose them at all to the user, because I think they are confusing (which is another reason why my functions rely on the user providing the query URL). What was your thinking on exposing them to the user?
Hopefully I'll have some time in the coming week to take a detailed look, but looking forward to hearing your thoughts in the meantime.
Thank you both so much - and thanks @baslat for your comments. I'm really sorry I haven't yet had time to properly look at either of your PRs. Hoping to have the time this week. Between work and parenting it has been a hectic time. Thanks again for your contributions to the package, I'm really excited about being able to integrate (some combination of?) your work
Hey @baslat, sounds good to me! And no stress @MattCowgill :)
On URLs
You're right, the functions I've written don't accept a full query URL. They only accept the various bits that make up the query URL: the dataflow id, the datakey, etc. I think it's fairly reasonable to support both approaches.
There are a few reasons I like the 'deconstructed' approach:
- It's a bit easier to understand the code once written. Compare:
abs_data("MYDATA", list(
STATE = 1:8, # All states
SEX = 1:2, # Male and female
))
# All states, male and female:
abs_data("https://api.data.abs.gov.au/ABS, MY_FLOW/1+2+3+4+5+6+7+8.1+2.....")
- As a result, it's way easier to tweak queries once you've got them, e.g.:
abs_data("MYDATA", list(
STATE = 1:8, # All states
SEX = 1, # Females
))
# All states, females:
abs_data("https://api.data.abs.gov.au/ABS, MY_FLOW/1+2+3+4+5+6+7+8.1.....")
- It's a lot cleaner to build a 'complex' query, e.g.:
abs_data("MYDATA", list(AGE = 18:100))
# The url gets really gnarly:
abs_data("https://api.data.abs.gov.au/ABS, MY_FLOW/..18+19+20+21+22+23+24+25+26+[ETC.]...")
On labels:
It's not too hard to pull the labels into a separate column when it's desirable like this:
my_data %>% mutate(x_label = labelled::to_character(x))
A note
I've discovered that the ABS codelists, which I've made available with abs_datastructure(), aren't dataflow specific.
When you hit abs_datastructure("MY_FLOW") you do get a codelist that contains all/only variables belonging to "MY_FLOW", but the values listed beside each variable may not all appear in "MY_FLOW".
You can end up with 404 errors if you try filtering to a value that's in the relevant codelist but not in the data, which is a bit of a headache.
Hey @kinto-b , I've had a play with your branch and I really like it, nice work! The abs_dataflows() functionality is neat, and it looks like a simpler implementation with fewer dependencies, so I think it's probably a better candidate for merging than my branch. I do have a few suggestions:
- consider giving the results of
abs_data()lowercase headers - consider rename
OBS_VALUEtovalue - consider mutating the
versioncolumn withbase::numeric_version() - consider
abs_datastructure()returning atibble - I think there is an argument to be made for allowing
abs_data()to take a query URL directly - as mentioned, I would love it if the "typical" ABS codes (eg ASGS, ANSZIC, ANSCO etc) returned both a name and code column. But, given the variety in the number of column names, maybe just enhancing the example to show how to mutate it into a new column would suffice.
- the 500 errors are a pain. The initial genesis of my approach was when I asked a former intern to download all the Data by Region from the ABS. She came up with the initial API approach, including the chunking approach, which was necessary because the query URLs didn't work and we needed all the data, and didn't want to manually muck around with the keys. So I see a use case for being able to query the API for a large data set without having to manually play with the data keys. Thoughts on adding a feature to chunk the query URL, either automatically or as an argument?
Really nice job!
Thanks so much @baslat!
I like all of those suggestions. I think giving the option to run chunk queries is a great idea. On first glance, I think it should be possible to do by:
- Looking in the codelist retrieved with
abs_datastructure()to find the variable with the most levels, and then - Running a separate query for each level.
But I'm not sure if this is the best way to do it. For one thing, it could be slow. For another, it could break given what I mentioned in my previous comment under the heading "note". For yet another, it could be a nuisance to the ABS servers and may lead to people being frozen out by vigilant sysadmins.
The one item on your list I would potentially quibble with is the variable renaming. If we leave it to the ABS to handle the naming, we won't get any naming conflicts. Whereas if we begin to fiddle, we potentially open the door to issues down the line. (For example, they might introduce a VALUE column alongside the OBS_VALUE column in a certain dataflow).
Unfortunately, I'm not going to have any time to look at this until the end of the month. If you want to make changes to this branch before then though, please be my guest. Otherwise, I'll definitely have a bit of free time after the 23rd.
Cheers!
True, fair point with the column renaming.
What about for a first pass at chunking we only did it by time period? That way we might be able to avoid the breaking issue you mentioned.
I should have more time next week to experiment.
I'm just getting a chance to look at this properly now. This is great!!!
Some initial thoughts:
-
I think the functions should have
apiin the name. A function name likeabs_data()is too generic, given that it will live in a package along with a range of other functions that are designed to import other types of ABS data. Maybeabs_api_data()? Orread_api()? -
I agree with all of @baslat's comments above. I take your point @kinto-b re: the
OBS_VALUEissue - let's think about that one
I'm going to play around with this over the next couple of days and come up with some more comments and possibly a commit or two. Thank you both so much for your work on this
Stellar!
Totally agree regarding names. I like both of your options. The one thing that would be nice is to pick a naming scheme which allows all three api functions to have the same prefix. So if read_api() then the others can potentially be read_api_dataflows() and read_api_datastructure()
By the way, I just remembered I've got a patch that makes the datakeys a bit easier to work with. It basically just allows a named list to be passed through instead of a string. So
# This
abs_data("MYDATA", list(STATE = 1:8, SEX = 1))
# Instead of
abs_data("MYDATA", "1...1&2&3&4&5&6&7&8..)
I'll pop it through this week when I get a free minute
Thanks both :)
Thanks very much for your review @HughParsonage !
I've just addressed your comments and added patch I mentioned which allows the datakey to be passed through as a named list.
It's a bit hacky, but I just wanted to put it up so y'all could take a look. The main difficulty has to do with what I mentioned above;
I've discovered that the ABS codelists, which I've made available with
abs_datastructure(), aren't dataflow specific.When you hit
abs_datastructure("MY_FLOW")you do get a codelist that contains all/only variables belonging to"MY_FLOW", but the values listed beside each variable may not all appear in"MY_FLOW".You can end up with 404 errors if you try filtering to a value that's in the relevant codelist but not in the data, which is a bit of a headache.
There's a hack in there to handle the situation in which the query hits a 404 because you've filtered a certain variable to levels that don't exist in the data. Not really sure it's the best way to go. Definitely needs a bit of discussion/thought
What about for a first pass at chunking we only did it by time period? That way we might be able to avoid the breaking issue you mentioned.
I can confirm that this idea by itself doesn't work. I tested with Data by Region, and it returns a combination of data, 400, 500 and 504 errors.
dbr_id <- abs_dataflows() |>
filter(name == "Regional Statistics, ASGS 2016, 2011-2020") |>
pull(id)
# test on full dataset
abs_data(dbr_id)
# 500 error
# test on latest year
abs_data(dbr_id, start_period = 2020)
# 637,917 rows
# test on earliest year
abs_data(dbr_id, start_period = 2011, end_period = 2011)
# 693,750 rows
# map over years
safe_api <- purrr::safely(abs_data)
years <- seq(2011, 2020)
dbr <- tibble(start_period = years, end_period = years) |>
purrr::pmap(safe_api, id = dbr_id)
dbr
# 2011 success
# 2012 404 error
# 2013 404 error
# 2014 404 error
# 2015 success
# 2016 500 error
# 2017 success
# 2018 success
# 2019 success
# 2020 504 error
@baslat Is that because some of the chunks (eg. 2012 in your example) are still too big? So it would possibly work if the chunks were smaller?
Hey all,
I just had a look at that example. Strangely, it appears that there actually isn't data for 2012-2014 in that table:
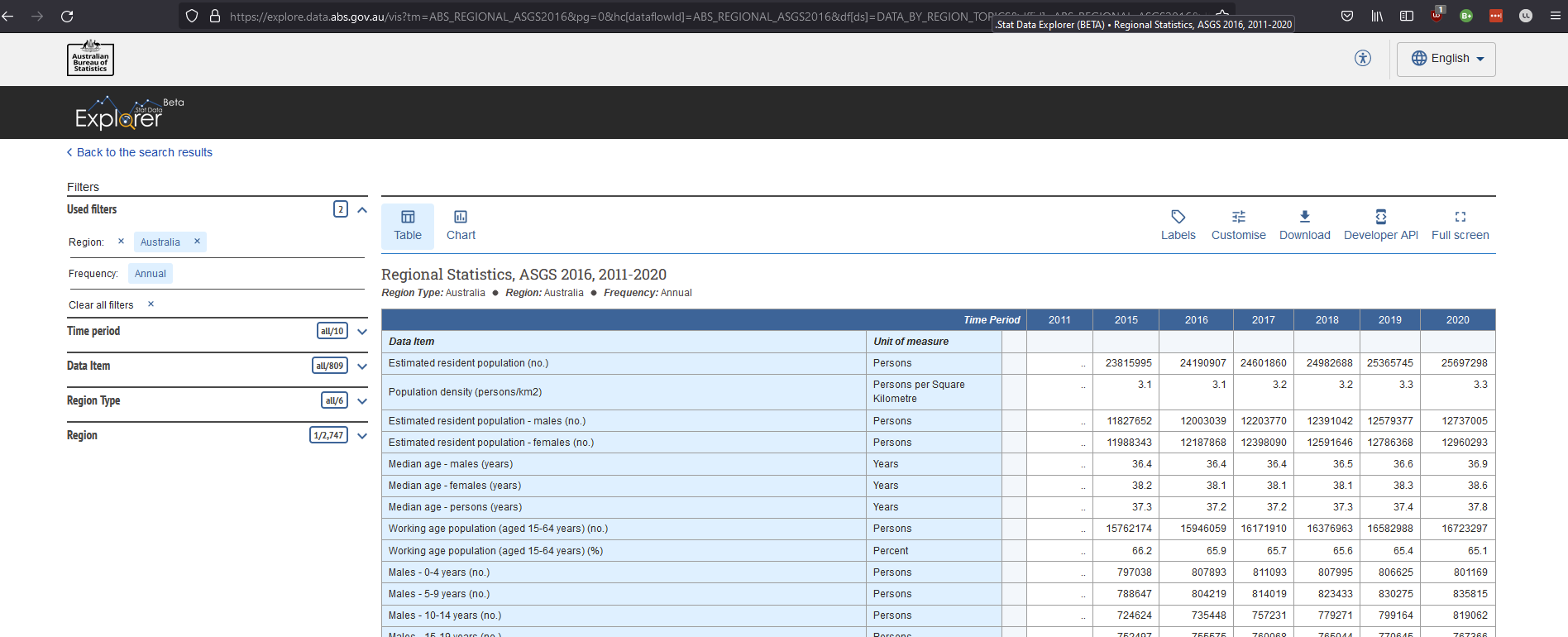
The 500/504 errors for 2016/2020 suggests that the data is still too big to retrieve.
I just had a play around with allowing the user to specify a variable to chunk on. Inside the function we then lookup in the datastructure the values that variable adopts and loop over them. But this runs into the same difficulty I mentioned above: namely that values which appear in the data structure may not appear in the data itself and then you get 404 errors. So what do you do with the 404s? We can't just silently ignore them because they might actually be significant. But we can't really display them either since at least some of them are guaranteed to be meaningless
Codecov Report
Base: 87.66% // Head: 88.74% // Increases project coverage by +1.08% :tada:
Coverage data is based on head (
20f28d7) compared to base (f7808e0). Patch coverage: 98.60% of modified lines in pull request are covered.
Additional details and impacted files
@@ Coverage Diff @@
## master #199 +/- ##
==========================================
+ Coverage 87.66% 88.74% +1.08%
==========================================
Files 28 29 +1
Lines 1127 1253 +126
==========================================
+ Hits 988 1112 +124
- Misses 139 141 +2
| Impacted Files | Coverage Δ | |
|---|---|---|
| R/check_latest_date.R | 100.00% <ø> (ø) |
|
| R/download_abs.R | 100.00% <ø> (ø) |
|
| R/download_data_cube.r | 88.23% <ø> (ø) |
|
| R/read_abs.R | 90.90% <ø> (ø) |
|
| R/scrape_abs_catalogues.r | 100.00% <ø> (ø) |
|
| R/separate_series.R | 100.00% <ø> (ø) |
|
| R/zzz.R | 100.00% <ø> (ø) |
|
| R/read_api.R | 98.34% <98.34%> (ø) |
|
| R/fst-utils.R | 100.00% <100.00%> (ø) |
|
| R/get_abs_xml_metadata.R | 91.54% <100.00%> (+0.24%) |
:arrow_up: |
| ... and 1 more |
Help us with your feedback. Take ten seconds to tell us how you rate us. Have a feature suggestion? Share it here.
:umbrella: View full report at Codecov.
:loudspeaker: Do you have feedback about the report comment? Let us know in this issue.
Where did we get to with this? I think it's a really good bit of work and should be merged in, and it probably doesn't have to handle every shortcoming of the API itself (i.e. the batch stuff and missing data mentioned earlier).
Hi @baslat, thanks for reminding me this is outstanding. I guess there's two options:
- Merge as-is, labelling the new function(s) as
experimentalto be clear that they may change; - Resolve the issues above (eg. what to do about 'batching') before merging
Thoughts?
I vote for labelling as experimental, noting that it looks like there are now merge conflicts that need addressing before it could be merged.
Hey both, if you're happy to merge without 'chunking' implemented, then I'm happy to put the finishing touches on and write up some unit tests. I'll have a fair bit of free time after November 11 so can look at doing it then :)
Hi again, I had another look and it's actually more polished than I remember so there weren't really too many finishing touches to add. I just wrote up tests covering the essentials and added myself as a contributor.
Let me know if there's anything else to do before merging :)
Hey @kinto-b, sorry for the delay, haven't forgotten this, will get to it soon
Hey Matt, I just wanted to follow up on this to see where you got to with it? I think I'm about to enter a fairly busy period, so may not have a lot of time free in the next few months to make changes if you discover any issues with the PR
This is all really good @kinto-b and I don't think further changes are required.
My only remaining question is whether labelled should be a hard dependency (Imports) or should be moved to Suggests. In the latter case, abs_api_label_data() would check to see if {labelled} is installed and return a labelled DF if so, returning a regular tibble if not. Thoughts?
@MattCowgill Stellar! Thanks :)
If we want to keep labelled in Suggests, which I think is reasonable, then I reckon we should add a label=TRUE default arg to these functions which controls whether labels are applied. If label=TRUE but labelled is not installed, then an error should be thrown prompting the user to install labelled or set label=FALSE.
If it's silently handled under the hood, it might lead to reproducibility issues. For instance: suppose I don't have labelled. I write code that depends on the return value of read_api() being unlabelled. Then I install labelled. Now unexpectedly my script is broken.
Yep, good point. I like the approach you've proposed. If you're happy with that, I'll make that change in the morning and merge this PR @kinto-b. Yay!
On reflection @kinto-b I've decided to keep labelled in Imports and just return a labelled data frame.
DONE! Thank you so much for all your work @kinto-b & @baslat and thanks for your (extreme) patience
Woohoo! 🎉 Thanks @baslat and @MattCowgill for your help! and thanks @HughParsonage for your review!