BELLE
 BELLE copied to clipboard
BELLE copied to clipboard
BELLE: Be Everyone's Large Language model Engine(开源中文对话大模型)

当我把下面这块模型保存代码移入epoch循环, if args.output_dir is not None: print_rank_0('saving the final model ...', args.global_rank)#It will overwrite the last epoch model model = convert_lora_to_linear_layer(model) if args.global_rank == 0: save_hf_format(model, tokenizer, args) 第一轮会顺利保存,当开始第二轮训练时候,报错信息如下: File...
Hello,我这边在自己的数据集上使用lora int8微调BELLE-LLAMA-7B-2M模型的时候发现一些问题,主要是添加了自定义special tokens之后,需要重新给这些添加的tokens初始化input embeddings,然后我一开始尝试resize_token_embeddings,但是这个函数训练和推理的时候都是随机初始化,所以不符合要求;然后我参考stanford alpaca( #line 65 in https://github.com/tatsu-lab/stanford_alpaca/blob/main/train.py)给input embeddings一个avage值,但是出现如下问题 问题:inference的时候input embeddings会有细微的差别,主要是训练的时候是load_in_8bit,而推理的时候是float16,这样在进行avage计算的时候会出现差异,为了解决这个问题,我尝试了直接重新把training时候的base model参数保存一份然后推理的时候加载,这个时候报如下错误: > probability tensor contains either `inf`, `nan` or element < 0 如果推理时候还是加载float16就没有以上错误,现在卡在这里了,不知道有没有大神来解答一下?感激不尽
Hi there @lianjiatech, great work. I'm trying to reproduce your work on the vocabulary expansion. But I couldn't find the code responsible for this step. I have only found [this](https://github.com/LianjiaTech/BELLE/blob/11e629476cffbad353ca1ab80ad3207db52c30a1/train/dschat_train_v1/utils/model/model_utils.py#L42)...
您好,我看github的介绍中有基于llama微调的模型得分结果,请问一下基于bloom微调的模型评估得分是怎样的。 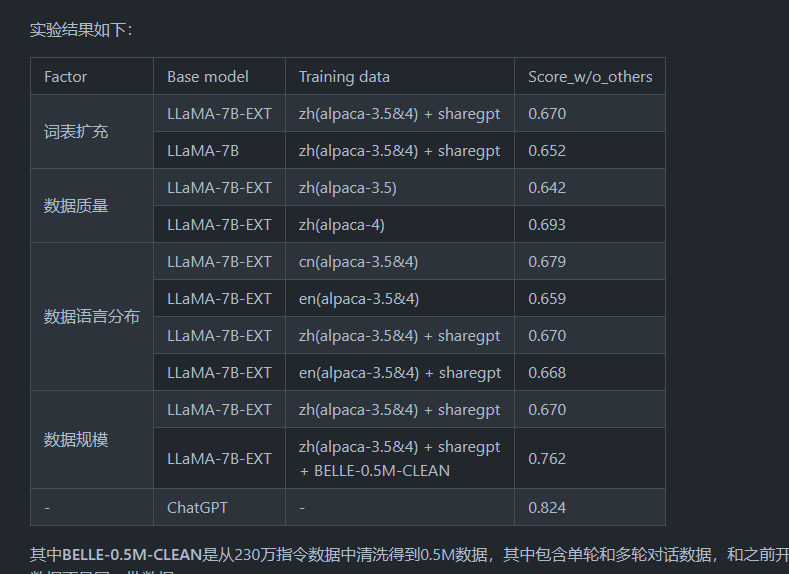
请问有关于bloom 做finetune的训练时间实验结果吗? 比如多少条数据,训练多少epoch,耗费显存及训练时间情况? 另外看到issue里面也有很多人提到,量化后速度变慢,我在实验过程中也发现了这个问题。同时,基于你们原先的代码,如下: model = AutoModelForCausalLM.from_pretrained( model_name_or_path, # load_in_8bit = load_in_8bit, torch_dtype=torch.float16, device_map=device_map) 如果我使用load_in_8bit=True,加载模型后训练时间远远大于设置torch_dtype=torch.float16. 我在load_in_8bit的训练时间大概200小时,但是改成float16的时候,只有40小时。 请问这个是什么情况导致? 硬件环境是A100 * 2
我用的:https://github.com/LianjiaTech/BELLE/tree/4f84c89372b435bae039b47f1f31078b1c6fc23e/train 这个finetune的结果: 问题很大
例如BELLE-0.5M-CLEAN,如不方便公开数据,方便公开一下数据清洗的方案吗?现在网上大量的公开中文数据集,质量普遍偏低,想请教一下数据清洗的方案和思路,谢谢。
Metadata
Owner
Metadata
BELLE: Be Everyone's Large Language model Engine(开源中文对话大模型)