Qingyun
![]()
![]()
![]()
Qingyun
@czczup thank you very much for the information The model modules should have the ability to handle this kind of case. I will check and fix this. Thanks for your...
@czczup thanks for your sharing! In the latest commit, I have modified `DINOHead.loss_dn_single()` at mmdet/models/dense_heads/dino_head.py to return Tensor(0) as each loss for dn. (`extract_dn_outputs()` has been modified too) 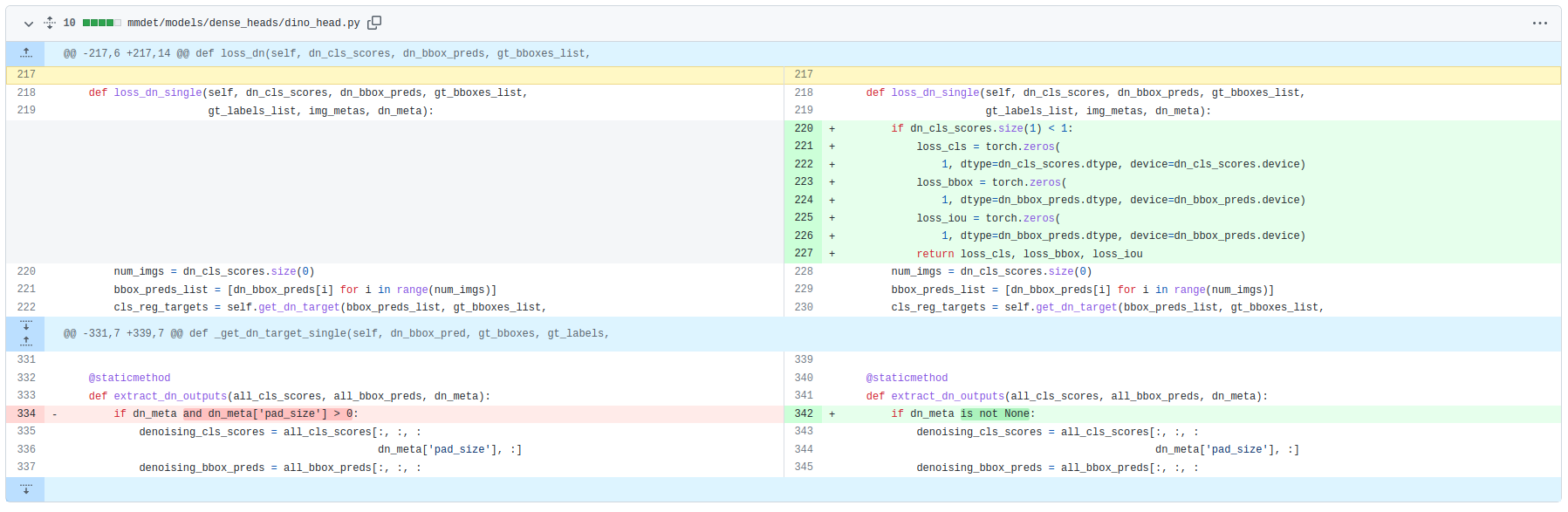
## My Finished work In the past week, I have finished **aligning inference accuracy** (with converted ckpt released by the authors, FrozenBatchNorm and Convs with bias in neck were used),...
# Results of preliminary training experiments of the current version # Results of DINO_4scale_R50_12e ## Train with origin repo code ### script: ```shell PARTITION_NAME=$1 NUM_GPUS=8 srun -p $PARTITION_NAME -n 1...
@zhaoguoqing12 你好,这个问题我们已经在 [390b25a](https://github.com/open-mmlab/mmdetection/pull/8362/commits/390b25a93a0deb6a834598161deeb0ce32822998) 基本解决 请问你是运行最新版本再次出现该问题吗。你可以检查你本地仓库的版本,目前最新版本为 [d380deb](https://github.com/open-mmlab/mmdetection/pull/8362/commits/d380debb4bfebbc5c446a47f60acf3d9a593758e),如果你本地不是最新版本,可以通过 git pull https://github.com/Li-Qingyun/mmdetection.git add-dino 更新本地仓库。如果是最新版本出现的问题,请麻烦提供一下环境版本,本地修改,运行命令 等信息
@zhaoguoqing12 如果是你自己的仓库出现相同的问题,你需要保证 loss_dict.keys() 是固定不变的。例如:在目前版本的DINO中loss_dict应当有39项目,我的检查方法为,在 loss_dict 被 reduce 之前: ```Python3 if len(loss_dict) != 39: import ipdb; ipdb.set_trace() ``` 通过移动帧发现 loss_dict.keys() 中缺少 dn 相关的 loss,所以在获取dn loss的函数中增加 无目标情况的分支,来保证所有的情况下,loss_dict 都稳定地由 39 项构成。目前这里的操作能暂时解决该问题,后续review阶段可能会用更好的方式替代。(例如,在没有目标的情况下,loss_giou和loss_bbox就自然为0,这种情况下补充的 loss_dn为0,但没有计算图) 我发现...
We start to refactor modules of DETR-like models to enhance the usability and readability of our codebase. For not affecting the progress of experiments in the current version and the...
The work will be done by other contributors.
@DeppMeng Is there an extra 's' on the line 30 of models/attention.py ? _LinearWithBiass or _LinearWithBias ?
I'm also looking forward to the open-source code of the optimizer strategies.