Open-Assistant
 Open-Assistant copied to clipboard
Open-Assistant copied to clipboard
Allow the user to set a response style
This may seem unnecessary, as e.g. ChatGPT can already emulate styles when asked. However, the current crowdsourced data consists of a mixture of styles, which may seem jarring to users. One option is to have contributors stick to one style, but not everyone is comfortable with writing professional-sounding responses, and first-class support for other styles could be a selling point for OA.
I can think of 3 main response styles:
- formal - as seen in ChatGPT; few contractions, long-winded explanations
- casual - as seen in the easter egg responses for Siri/Alexa/Cortana/etc; friendly, witty, exclamation marks, might even have a favorite color
- terse (struggling to settle on a name for this) - as seen in InstructGPT; just provides the response with no elaboration
The crowdsourced data could then either be categorized at time of writing ("please use this style") or tagged later ("what style does this match?").
Low-effort mockups
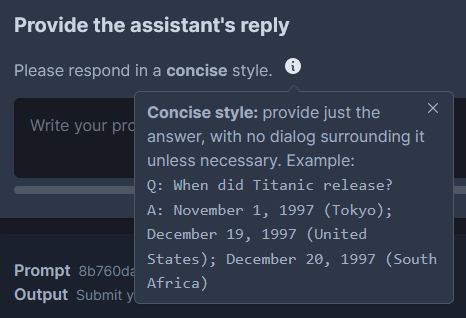
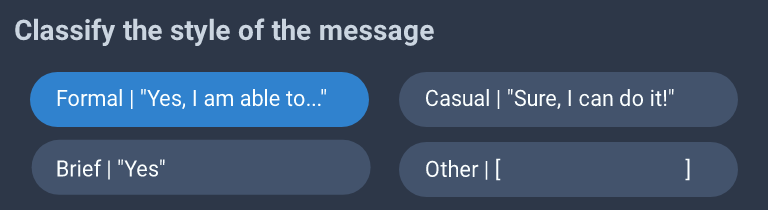
Additionally, external datasets could be tagged with style too; for example, math_dataset would be "terse", competition_math would be "formal", and the Khan Academy subset of AMPS would be "casual".
It may be desirable to assign a pre-prompt (or a set thereof) to each style, then allow the user to customize it to create a custom style. However, I'm not sure if it would generalize well enough for that to work well. Prompt tuning, perhaps? Few-shot?
I think this is both a modeling issue and a data issue. Maybe we can break off:
Additionally, external datasets could be tagged with style too; for example, math_dataset would be "terse", competition_math would be "formal", and the Khan Academy subset of AMPS would be "casual".
Into it's own issue?
I didn't realize until now that the website has a Serious vs. Humorous label axis, which isn't quite the same as formal vs. casual, but is close enough to matter. This leaves the terse style, which I'm not sure if people even want?
My current idea is that the model could be explicitly trained to be good at copying the style from a few-shot prompt, by adding random answers from the same user (or the same dataset) into the context. This would make it easier for end users to create their own styles in a manner similar to character.ai.
@Sobsz
terse style, which I'm not sure if people even want?
I guess it may be plausible in some not-so-chat-oriented contexts e.g. when generating legal documents or summarizations. Also from my experience chatting with ChatGPT I wish it would have a toggle like "be less watery" :).
@Sobsz do you have time to work on this issue? Can you put together a plan to collect data and train for styles? If not, we can try to get more people involved. It's a great idea.
After some thought, I'm not sure if data collection would even be necessary. In my experience, LLMs are pretty good at few-shot style emulation without being explicitly trained to do so. This means we could make this a purely client-side feature: customizable prompts that are automatically prepended before each chat. (Although, it might be useful to encourage consistency of style within an answer chain, e.g. by putting it in the guidelines and/or adding a "Similar Style" rating axis.)
Here's an example of such a few-shot prompt, made by another contributor: https://github.com/Rallio67/language-model-agents/blob/main/Prompts_for_agents.py It's designed for untuned models, but it should work as an example of what I mean.
One disadvantage is that (AFAIK) a larger context for takes up more resources for GPT-based models, so it might still be beneficial resource-wise to train the model to follow short preludes like Style: Formal, with the data for that collected from highly-rated responses where the Serious-Humorous score meets some threshold. (Or do prompt tuning for that instead!)
Experiments in this direction were conducted via system prompts & text labels, see sampling report & sampling report2.