Honor language-specific rules for text-transform
text-transform: uppercase defines some language-specific rules such as i/İ for Turkic languages and άι/ΑΪ for Greek.
As shown with the following html, WeasyPrint does not seem to respect those rules:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" lang="tr">
<body>
<table>
<tr>
<th>Turkish:</th>
<td style="text-transform: uppercase">a b c ç d e f g ğ h ı i j k l m n o ö p r s ş t u ü v y z</td>
</tr>
<tr>
<th>Expected:</th>
<td>A B C Ç D E F G Ğ H I İ J K L M N O Ö P R S Ş T U Ü V Y Z</td>
</tr>
<tr>
<th>Greek:</th>
<td lang="el" style="text-transform: uppercase">ά ή άι</td>
</tr>
<tr>
<th>Expected:</th>
<td>Α Ή ΑΪ</td>
</tr>
</table>
</body>
</html>
Renders as:
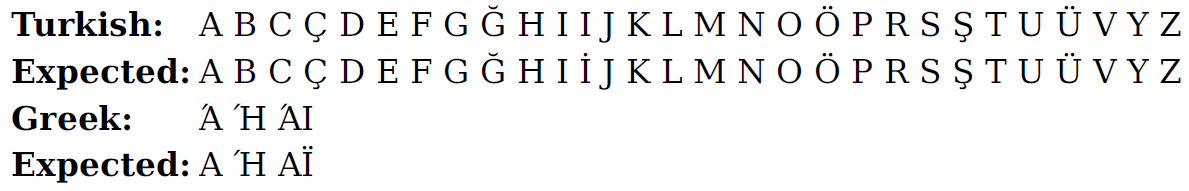
Firefox and Chrome handle it properly:

I’m also attaching the generated pdf.pdf with WeasyPrint 57.0.
We could rely on pyICU, but it should be possible to handle all the exceptions manually instead of depending on an external library. According to ICU’s repository, it looks like we have only 3 exceptions:
- Turkish/Azeri
- Greek
- Lithuanian
The goal is to change these functions to take style['lang'] as a parameter and to handle the language-specific differences using naive Python code (there’s no need to optimize this code that shouldn’t be called often).
The "hard" part is to understand what’s exactly defined in ICU’s file 😁️.
That’s a good issue for a first-time contributor, if anyone’s interested in this feature we’ll be happy to help you add some code for it!