julia
 julia copied to clipboard
julia copied to clipboard
Stabilize, optimize, and increase robustness of QuickSort
"Quicksort is unstable and attempts to stabilize it hurt performance" (citation needed).
I believe I have simultaneously stabilized and sped up quicksort, which should allow us to simplify sorting policy.
Instability comes from the partition algorithm. We currently use something like this
while i < j
while(v[i] < pivot) i += 1 end
while(v[j] > pivot) j -= 1 end
v[i], v[j] = v[j], v[i]
end
Which is an efficient in place unstable partition algorithm.
If we allow ourselves scratch space to conduct the partition, we can use something like this instead
for x in v
if x < pivot
t[i] = x
i += 1
else
t[j] = x
j -= 1
end
end
This new approach is still unstable, but it is predictably unstable. Everything before the pivot is stable, and everything after it is reversed. After several nested partitions, we still only need to reverse half the elements one time to reintroduce stability.
Benchmarks reveal that this approach is typically faster than the original, possibly because the order of comparisons and computations is known at the beginning of the partition rather than depending on the branches during the partition. In effect, the branches in this new algorithm have less impact on future code execution. I have not profiled this implementation at the CPU level and don't know for sure why it is a speedup.
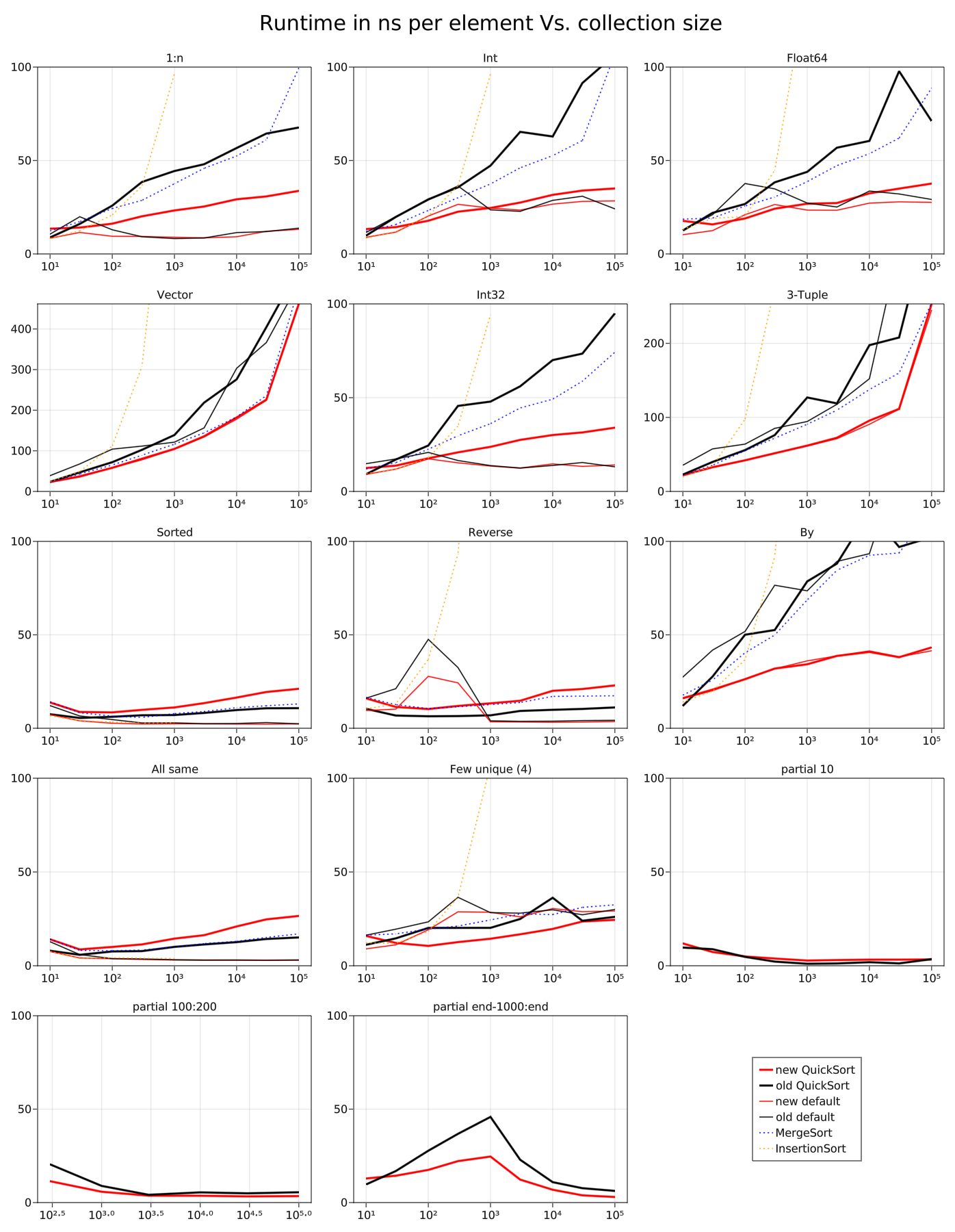 Caveat 1: I benchmarked on a somewhat inconsistently noisy machine.
Caveat 1: I benchmarked on a somewhat inconsistently noisy machine.
Caveat 2: This is sometimes a slowdown. See graphs.
Future work indicated by this PR includes
- Move MergeSort to SortingAlgorithms.jl
- Now that every sorting algorithm in Base's sorting policy except InsertionSort uses scratch space, it becomes even more valuable to effectively pass scratch-space vectors around. For example, in this PR, fpsort! results in redundant scratch space allocations.
- We partition in quicksort and fpsort!. Generalizing partition! and factoring it out should result in substantial readability improvements in fpsort! which, in turn, should facilitate extending support optimized sorting for unions with Missing to all vectors. We could also export
partition!.
Closes #11429 Closes #42713 Closes #32675
It seems like solving #11429 as a side-effect, but at the cost of losing in-place property.
It seems like solving #11429 as a side-effect
Good observation! I've added tests to confirm, and indeed it does.
This depends on workspaces which depend on OffsetArrays. Hold pending availability of OffsetArrays in Sort.jl.
We're proceeding with workspaces/buffers for sorting without OffsetArrays. We will use a similar approach here as in radix_sort. It will work but be a bit ugly and have a bit of runtime overhead for certain inputs with offset indexing.
Benchmarks are here!
This is typically a speedup, but is a 3-7% regression in number of comparisons because it uses randomized pivot selection rather than median of 3. Lowering SMALL_ALGORITHM_THRESHOLD by a few elementems would more than make up for this increase in number of comparrions, but also result in an increase in runtime for most use cases. This is because insertion sort, to an even greater degree than this stabilized quicksort, is fast despite using more comparisons than other algorithms.
As a result of this regression in number of comparrions, as well as increased space usage and possibly other factors I don't understand, this PR is a regression for sorting long vectors of vectors (including sortslices with dims=1)
I believe this is more than made up for by the substantial improvements in sorting with the by keyword set, and the fact that it stabilizes quicksort which allows it to apply to types that were previously dispatched to mergesort. Of note, the compiler often sorts tuples, and this speeds up quicksort on tuples as well as allowing dispatch to switch from mergesort to quicksort for tuples. This results in an almost 2x speedup for the default tuple-sorting algorithm.
~The regressions in presorted, reverse-presorted, and all-same don't bother me too much because they are masked by the presorted, reverse-presorted, and all-same checks that happen by default for radixable types and will eventually also happen by default for all types. Further, while these regressions are big form a multiplicative standpoint, they are a result of a loss of taking advantage of structured data rather than a penalty above random—i.e. this version's runtime is more consistent than the previous version.~

This also eliminates quadratic time pathological inputs which were previously uncommon (nobody has opened an issue) but present:
julia> @elapsed sort!(vcat(1:10^6, -10^6:-1); alg=QuickSort)
48.216649071 # Before
0.118596533 # After
Benchmarking details
Source code: https://gist.github.com/LilithHafner/56fa5b3e4ed984bcd5af086adbcb98b8 Results as text: https://gist.github.com/LilithHafner/38f8366238f8a8e8c7c1659b76e8246a
Platform Info:
OS: macOS (x86_64-apple-darwin21.3.0)
CPU: 4 × Intel(R) Core(TM) i5-8210Y CPU @ 1.60GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-14.0.5 (ORCJIT, skylake)
Threads: 1 on 4 virtual cores
Environment:
LD_LIBRARY_PATH = /usr/local/lib
Total runtime: 20 minutes
This mostly looks good, but there are fairly substantial regressions for inputs that are either fully forward or reverse sorted that might be good to fix with an issorted check.
I suppose that wouldn't be too hard to add. I'd also add an undocumented keyword argument to suppress that check to avoid doing it twice in AdaptiveSort.
I just noticed that the regression for long vectors of vectors also applies to long vectors of strings. There's also a 22% regression here:
v = [randstring(4) for _ in 1:1_000_000]; @elapsed sort!(v)
I've added presorted and reverse-sorted checks and updated the benchmarks. This makes the graphs look real pretty, but doesn't help with almost presorted or almost reverse-presorted inputs.
I want to be clear that this algorithm change is not a strict improvement. It is and almost certainly will remain a performance regression in multiple meaningful cases. We will need to make a value judgment about whether the improvements (performance and otherwise) outweigh the regressions.
Bump. If possible, I'd like to get this into 1.9 because it redefines the AdaptiveSort type which was introduced in 1.9.
Note: consider https://github.com/JuliaCollections/SortingAlgorithms.jl/pull/19. If the pivot appears repeatedly, utilize that.
If the pivot appears repeatedly, utilize that.
Would it be possible to make it stable?
Upon further consideration, I can't think of a way that special case optimization is compatible with the partitioning approach of this PR. I think it's best to proceed without that addition and add it later if possible and advantagous.
I think that I've addressed all review comments so far. If it's viable, it would be nice to get this into 1.9.
Now that every sorting algorithm in Base's sorting policy except InsertionSort uses scratch space, it becomes even more valuable to effectively pass scratch-space vectors around. For example, in this PR,
fpsort!results in redundant scratch space allocations.
The way you explain this suggests to me that a better keyword for that PR would have been something like scratch since scratch space is the term you use to talk about it 😄
c.f. https://github.com/JuliaLang/julia/pull/45222#issuecomment-1189352106
I want to be clear that this algorithm change is not a strict improvement. It is and almost certainly will remain a performance regression in multiple meaningful cases. We will need to make a value judgment about whether the improvements (performance and otherwise) outweigh the regressions.