roboxtractor
 roboxtractor copied to clipboard
roboxtractor copied to clipboard
Extract endpoints marked as disallow in robots files to generate wordlists.
roboXtractor
![]()
![]()
![]()
![]()
This tool has been developed to extract endpoints marked as disallow in robots.txt file. It crawls the file directly on the web and has a wayback machine query mode (1 query for each of the previous 5 years).
Possible uses of roboXtractor:
- Generate a customized wordlist of endpoints for later use in a fuzzing tool (-m 1).
- Generate a list of URLs to visit (-m 0).
🛠️ Installation
If you want to make modifications locally and compile it, follow the instructions below:
> git clone https://github.com/Josue87/roboxtractor.git
> cd roboxtractor
> go build
If you are only interested in using the program:
> go get -u github.com/Josue87/roboxtractor
Note If you are using version 1.16 or higher and you have any errors, run the following command:
> go env -w GO111MODULE="auto"
🗒 Options
The flags that can be used to launch the tool:
| Flag | Type | Description | Example |
|---|---|---|---|
| u | string | URL to extract endpoints marked as disallow in robots.txt file. | -u https://example.com |
| m | uint | Extract URLs (0) // Extract endpoints to generate a wordlist (>1 default) | -m 1 |
| wb | bool | Check Wayback Machine. Check 5 years (Slow mode) | -wb |
| v | bool | Verbose mode. Displays additional information at each step | -v |
| s | bool | Silen mode doesn't show banner | -s |
You can ignore the -u flag and pass a file directly as follows:
cat urls.txt | roboxtractor -m 1 -v
Only the results are written to the standard output. The banner and information messages with the -v flag are redirected to the error output,
👾 Usage
The following are some examples of use:
roboxtractor --help
cat urls.txt | roboxtractor -m 0 -v
roboxtractor -u https://www.example.com -m 1 -wb
cat urls.txt | roboxtractor -m 1 -s > ./customwordlist.txt
cat urls.txt | roboxtractor -s -v | uniq > ./uniquewordlist.txt
echo http://example.com | roboxtractor -v
echo http://example.com | roboxtractor -v -wb
🚀 Examples
Let's take a look at some examples. We have the following file:

Extracting endpoints:

Extracting URLs:

Checking Wayback Machine:
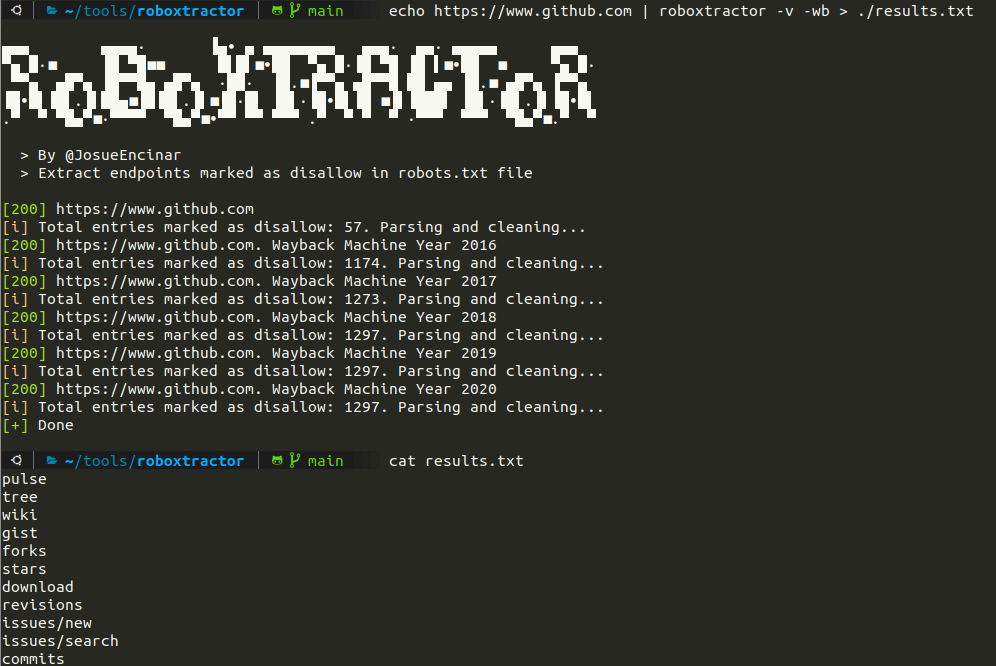
Github had many entries in the file, which were not useful, a cleaning process is done to avoid duplicates or entries with *. Check the following image:

For example:
-
/gist/*/*/*is transformed asgist. -
/*/tarballis trasformed astarball. -
/,/*or similar entries are removed.
🤗 Thanks to
The idea comes from a tweet written by @remonsec that did something similar in a bash script. Check the tweet.