Fine Tuning g1_latin model
Hello, is there any opportunity to fine tune existing models? Im using trainer folder, and it seems that it trains a new model. Im trying to set config['saved_model'] = folder_with_downloaded_model, but it gives an error. Can you help please?
For more explanation:
I want to fine tune g2_latin model with my own generated dataset. When I set config['saved_mode'] = ../latin_g2.pth i get an error
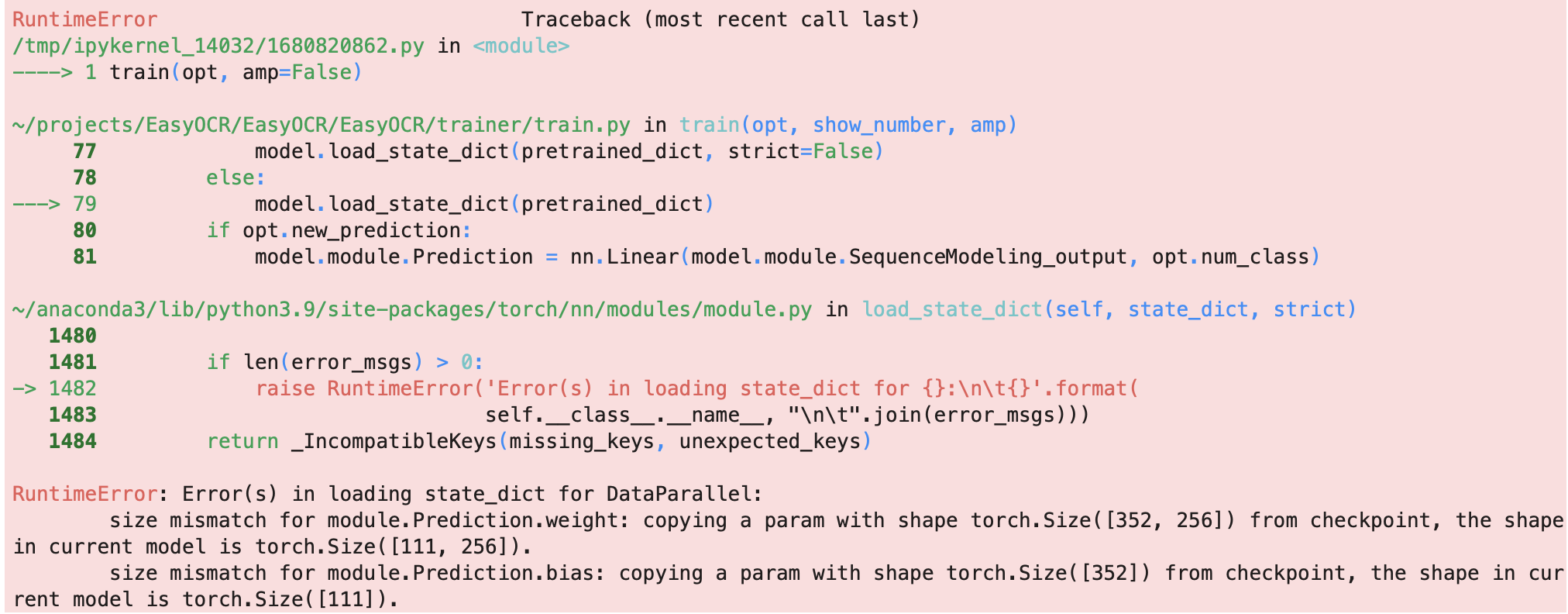
size mismatch change your char list https://github.com/JaidedAI/EasyOCR/blob/master/easyocr/config.py#L149
Any update on this? You were able to fine-tuning the g2_latin model with your own dataset?
I have the same mismatch error in the fine-tuning and changing the lang_char don't help me.
#lang_char: " !"#$%&'()+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_abcdefghijklmnopqrstuvwxyz{|}~ªÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿĀāĂ㥹ĆćČčĎďĐđĒēĖėĘęĚěĞğĨĩĪīĮįİıĶķĹĺĻļĽľŁłŃńŅņŇňŒœŔŕŘřŚśŞşŠšŤťŨũŪūŮůŲųŸŹźŻżŽžƏƠơƯưȘșȚțə̇ḌḍḶḷṀṁṂṃṄṅṆṇṬṭẠạẢảẤấẦầẨẩẪẫẬậẮắẰằẲẳẴẵẶặẸẹẺẻẼẽẾếỀềỂểỄễỆệỈỉỊịỌọỎỏỐốỒồỔổỖỗỘộỚớỜờỞởỠỡỢợỤụỦủỨứỪừỬửỮữỰựỲỳỴỵỶỷỸỹ€"#'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' lang_char: "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzªÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿĀāĂ㥹ĆćČčĎďĐđĒēĖėĘęĚěĞğĨĩĪīĮįİıĶķĹĺĻļĽľŁłŃńŅņŇňŒœŔŕŘřŚśŞşŠšŤťŨũŪūŮůŲųŸŹźŻżŽžƏƠơƯưȘșȚțə̇ḌḍḶḷṀṁṂṃṄṅṆṇṬṭẠạẢảẤấẦầẨẩẪẫẬậẮắẰằẲẳẴẵẶặẸẹẺẻẼẽẾếỀềỂểỄễỆệỈỉỊịỌọỎỏỐốỒồỔổỖỗỘộỚớỜờỞởỠỡỢợỤụỦủỨứỪừỬửỮữỰựỲỳỴỵỶỷỸỹ" #symbol: "!\"#$%&'()*+,-./:;<=>?@[\\]^_{|}~ €"
#symbol: " !"#$%&'()+,-./0123456789:;<=>?@[\]^_`{|}~ €"