i have two gaussian_conditional ,when update model, why one update,another one dont update
firstly,thank you for your work!
i have two gaussian_conditional ,when update model, why one update,another one dont update
self.gaussian_conditional = GaussianConditional(None)
self.gaussian_conditional_z = GaussianConditional(None)
Which version/commit of CompressAI is this? The latest version should handle all these things automatically.
https://github.com/InterDigitalInc/CompressAI/blob/ee91d536bd934fc1f8b1532f78db4c94072ae26d/compressai/models/base.py#L62-L113
But if you want to figure out what's going on without git pulling the latest changes:
- Add a
print("This function runs.")statement when the function containing theupdate_registered_buffersis called. - Ensure the correct
load_state_dictis called.super()sometimes may not refer to what you are expecting.
my compressai version is 1.2.0,you say the new version can handle all these things automatically,I want to know if there are any other function updates in the new version?
Automatic definition of load_state_dict and update
from compressai.models.base import CompressionModel
class ExampleModel(CompressionModel):
def __init__(self, N, M):
super().__init__()
self.entropy_bottleneck_1 = EntropyBottleneck(M)
self.entropy_bottleneck_2 = EntropyBottleneck(M)
...
self.gaussian_conditional_1 = GaussianConditional()
self.gaussian_conditional_2 = GaussianConditional()
...
# def load_state_dict(...) should automatically work. No need to write your own!
# def update(...) should automatically work. No need to write your own!
No other significant breaking changes from 1.2.0 to 1.2.4, so upgrading should be easy.
Most users can stop reading here. The section below is for more "advanced usage".
Different scale tables
A single instance of GaussianConditional does effectively the same thing as multiple GaussianConditionals if they all use the same scale table. If you intend on initializing them with different scale tables, then update() does need to be overridden:
def update(self, scale_table=None, force=False):
updated = False
for _, module in self.named_modules():
if isinstance(module, EntropyBottleneck):
updated |= module.update(force=force)
assert scale_table is None # We're using our own scale_tables.
scale_table_1 = ...
scale_table_2 = ...
updated |= self.gaussian_conditional_1.update_scale_table(scale_table_1, force=force)
updated |= self.gaussian_conditional_2.update_scale_table(scale_table_2, force=force)
return updated
For load_state_dict, we can just inherit the default implementation in CompressionModel.load_state_dict.
I'm sorry I don't quite understand GaussianCondition .you means scale_table Is it a default table that won't change as the input image changes?
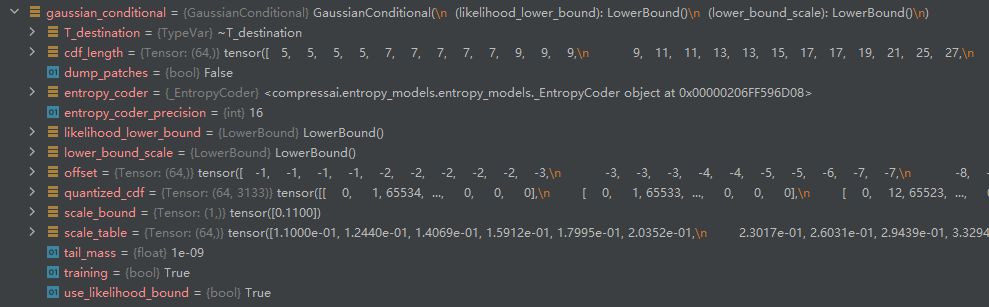
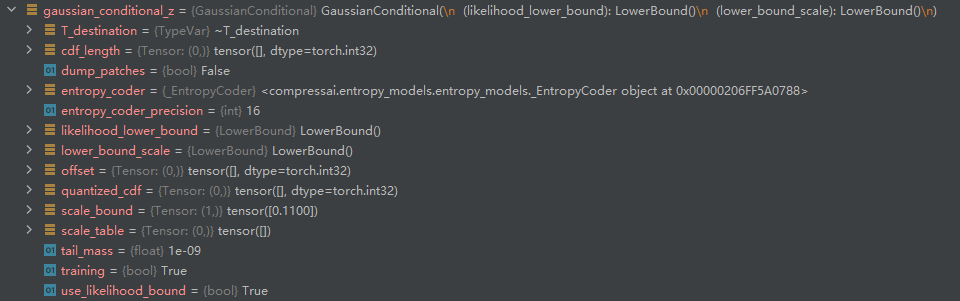
I mean, my two different Gaussian Conditions, one for modeling z and one for modeling y, have the same parameters for Gaussian Conditions. Is this normal?Their parameters both are shown below.

Yes, their non-trainable parameters should all have the same default initialized values. This is fine.
The section I wrote about "Different scale tables" was just in case you wanted to customize it further.
Thank you very much for your answer. I have another question. There is a parameter in the code that is quality.For example, in the following model.
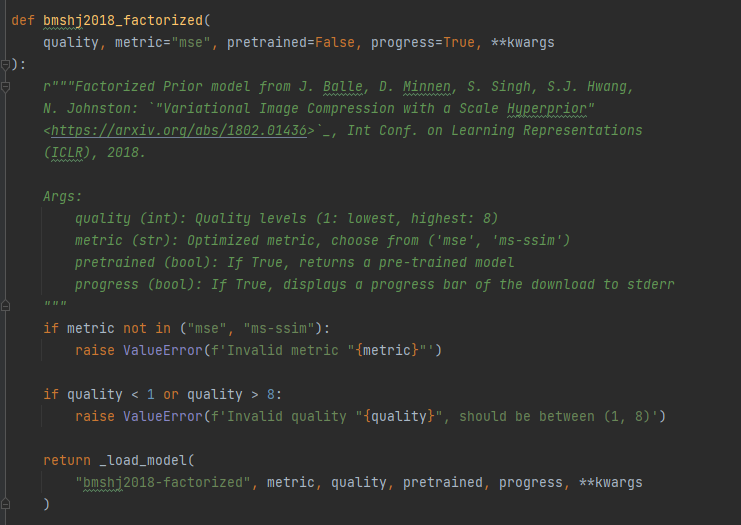 His quality parameters are as follows:
His quality parameters are as follows:
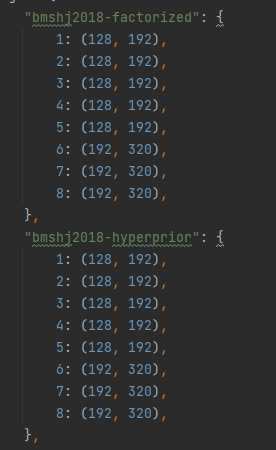 I want to know what this parameter means. Is it N and M in the network model? Do you write this to facilitate selecting different N and M for experiments?
I want to know what this parameter means. Is it N and M in the network model? Do you write this to facilitate selecting different N and M for experiments?
Yes, these are N, M, and are used when calling the model's __init__:
https://github.com/InterDigitalInc/CompressAI/blob/ee91d536bd934fc1f8b1532f78db4c94072ae26d/compressai/models/google.py#L242
The quality parameter refers to different image quality targets that each separate model was trained on. This is done by changing the $\lambda$ tradeoff hyperparameter in the loss function, $L = R + \lambda D$. The lambdas used for each quality are listed here: https://interdigitalinc.github.io/CompressAI/zoo.html#training
I don't quite understand what you mean. What you mean is that the qualities of 1-8 are λ Are there different values for?
The qualities are just a convenient way to number the different trained models which produce small files (quality=1) or large files (quality=8).
The lambdas shown were used to train these models. But you can train with any lambda you want.
oh,you mean that the specific training lambda is determined when I input training instructions, and the quality I choose will not affect the specific training process. For example, if I specify lambda=0.02, even if I choose quality=1, the lambda during training is still 0.02?
sorry,i have a another question.What exactly does aux_loss represent? When I train 10000 images with a batch size of 16 for 100 epochs, in the training output report, The value of aux_ loss is always high, ranging from around 15000 during initial training to around 5500 after 100 epochs. How can it be minimized?
aux_loss is described here:
- https://interdigitalinc.github.io/CompressAI/models.html#compressai.models.CompressionModel.aux_loss
- https://github.com/InterDigitalInc/CompressAI/issues/167
Usually, it goes down to ~30 after the first few epochs. It's unusual that it stays large in your case.
Possible scenarios:
- Perhaps aux_optimizer.zero_grad(), aux_loss.backward(), and aux_optimizer.step() aren't called in the correct order. Is your
train_one_epochthe same as the original from examples/train.py? - Perhaps the aux_optimizer doesn't have access to every instance of the
EntropyBottleneck.quantilesparameters. Do you have multipleEntropyBottleneckinstances in your model?
Also, what is the value of the standard RD loss after 100 epochs? Could you also check to see if the bpp from running eval_model matches the bpp_loss? (Run both on the same test image.)
my train_one_epoch is same as original from examples/train.py. what is s means?EntropyBottleneck() this function is entropy encoded for data, right? However, for example, the ScaleHyperprior model from the h_a obtained z ,z should be modeled using the Factorized Entropy Model. Has EntropyBottleneck() completed this operation? i use mse to eval model,RD loss is mse loss?this is my output output.txt
The RD loss (0.6) looks good. My guess is that at least one of the entropy bottlenecks .quantiles are not being optimized. Could you post the code for your model definition?
EntropyBottleneck encodes each channel separately using some arbitrary distribution trained for each channel. That is indeed a factorized entropy model. It is used on the z in ScaleHyperprior.
It might be because of the custom HighLowEntropyBottleneck.
If HighLowEntropyBottleneck is implemented like this:
class HighLowEntropyBottleneck(EntropyModel):
def __init__(self, N):
self.eb_l = EntropyBottleneck(N)
self.eb_h = EntropyBottleneck(N)
Then try this:
class my_model(JointAutoregressiveHierarchicalPriors):
def load_state_dict(self, state_dict, strict=True):
for name, module in self.named_modules():
if not any(x.startswith(name) for x in state_dict.keys()):
continue
if isinstance(module, EntropyBottleneck):
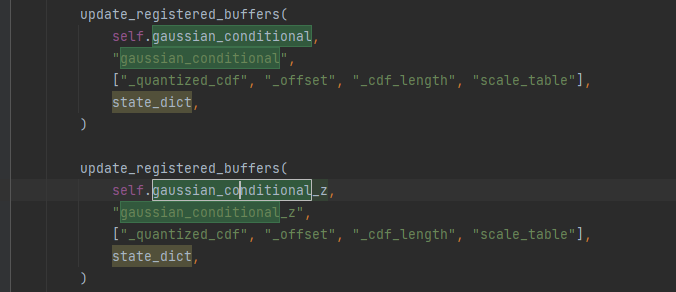
update_registered_buffers(
module,
name,
["_quantized_cdf", "_offset", "_cdf_length"],
state_dict,
)
# NOTE: The code below is not needed since the code above already does this.
#
# if isinstance(module, HighLowEntropyBottleneck):
# update_registered_buffers(
# module,
# name,
# ["eb_l._quantized_cdf", "eb_l._offset", "eb_l._cdf_length",
# "eb_h._quantized_cdf", "eb_h._offset", "eb_h._cdf_length"],
# state_dict,
# )
if isinstance(module, GaussianConditional):
update_registered_buffers(
module,
name,
["_quantized_cdf", "_offset", "_cdf_length", "scale_table"],
state_dict,
)
return nn.Module.load_state_dict(self, state_dict, strict=strict)
def update(self, scale_table=None, force=False):
if scale_table is None:
scale_table = get_scale_table()
updated = False
for _, module in self.named_modules():
if isinstance(module, EntropyBottleneck):
updated |= module.update(force=force)
# NOTE: The code below is not needed since the code above already does this.
# if isinstance(module, HighLowEntropyBottleneck):
# updated |= module.update(force=force)
if isinstance(module, GaussianConditional):
updated |= module.update_scale_table(scale_table, force=force)
return updated
def aux_loss(self):
loss = sum(m.loss() for m in self.modules() if isinstance(m, EntropyBottleneck))
return loss
Nevermind, there shouldn't be a functional difference between this and what you posted. (But you can give it a try just in case.)
yes,it like this class HighLowEntropyBottleneck(EntropyModel):
def __init__(self, entropy_bottleneck_channels, alpha=0.5):
super(HighLowEntropyBottleneck, self).__init__()
beta = 1. - alpha
eb_l_ch = int(alpha * entropy_bottleneck_channels)
eb_h_ch = int(beta * entropy_bottleneck_channels)
self.eb_l = EntropyBottleneck(channels=eb_l_ch)
self.eb_h = EntropyBottleneck(channels=eb_h_ch)
def forward(self, x):
x_h, x_l = x
x_q_h, x_h_likelihoods = self.eb_h(x_h)
x_q_l, x_l_likelihoods = self.eb_l(x_l)
return x_q_h, x_q_l, x_h_likelihoods, x_l_likelihoods
def compress(self, x):
x_h, x_l = x
x_h_bits = self.eb_h.compress(x_h)
x_l_bits = self.eb_l.compress(x_l)
return x_h_bits, x_l_bits
def decompress(self, strings, sizes):
x_h_string = self.eb_h.decompress(strings[0], sizes[0])
x_l_string = self.eb_l.decompress(strings[1], sizes[1])
return x_h_string, x_l_string
def update(self, force=False):
return self.eb_l.update(force=force) & self.eb_h.update(force=force)
The code you posted seems fine to me after a bit of review. I can't understand why it's not reducing the aux loss. The parameters for the aux optimizer are defined as follows:
parameters = {
"net": {
name
for name, param in net.named_parameters()
if param.requires_grad and not name.endswith(".quantiles")
},
"aux": {
name
for name, param in net.named_parameters()
if param.requires_grad and name.endswith(".quantiles")
},
}
...however, since what you showed are the default EntropyBottleneck modules, they should have .quantiles parameters. The other modules don't have a .quantiles parameter, so no problems there, either...
Perhaps just for confirmation, it might be good to verify that the aux_optimizer contains all the required parameters. I believe these are stored in the variable aux_optimizer.param_groups (or something like that).
your means is i debug it and watch the parameters of aux_optimizer and aux_optimizer.param_groups?
 there may be some trouble?
there may be some trouble?
I think that looks fine for the untrained model. For the trained model, check:
print(net.entropy_bottleneck.eb_l.quantiles)
print(net.entropy_bottleneck.eb_h.quantiles)
The values should all be different from [-10, 0, 10], and look something similar to:
>>> from compressai.zoo import mbt2018
>>> net = mbt2018(quality=2, pretrained=True)
>>> print(net.entropy_bottleneck.quantiles)
Parameter containing:
tensor([[[ 4.0214e-02, 4.3686e-02, 4.6902e-02]],
[[-2.0358e+01, 6.2115e-01, 1.9330e+01]],
[[ 5.0907e-02, 5.4218e-02, 5.7158e-02]],
...
[[ 5.2013e-01, 5.3068e-01, 5.3920e-01]],
[[ 1.6951e-01, 1.7440e-01, 1.7930e-01]],
[[ 2.6147e-01, 2.6927e-01, 2.7660e-01]],
[[ 2.6363e-01, 2.7121e-01, 2.7847e-01]]], requires_grad=True)
i.e. Most channels have a magnitude <1, but there's a couple that have a magnitude of roughly 20.
Load the trained model using:
from compressai.zoo.image import model_architectures as architectures
architectures["your-model"] = YourModel
def load_checkpoint(arch: str, no_update: bool, checkpoint_path: str) -> nn.Module:
# update model if need be
checkpoint = torch.load(checkpoint_path, map_location="cpu")
state_dict = checkpoint
# compatibility with 'not updated yet' trained nets
for key in ["network", "state_dict", "model_state_dict"]:
if key in checkpoint:
state_dict = checkpoint[key]
model_cls = architectures[arch]
net = model_cls.from_state_dict(state_dict)
if not no_update:
net.update(force=True)
return net.eval()
net = load_checkpoint(arch="your-model", no_update=False, checkpoint_path="/path/to/ckpt.pth.tar")
print(net.entropy_bottleneck.eb_l.quantiles)
print(net.entropy_bottleneck.eb_h.quantiles)
i use update_model to run the checkpoint_best_loss.pth.tar and in this place i code it with
state_dict = load_checkpoint(filepath)
model_cls_or_entrypoint = models[architecture]
if not isinstance(model_cls_or_entrypoint, type):
model_cls = model_cls_or_entrypoint()
else:
model_cls = model_cls_or_entrypoint
net = model_cls.from_state_dict(state_dict)
print(net.entropy_bottleneck.eb_l.quantiles)
print(net.entropy_bottleneck.eb_h.quantiles)
and get these
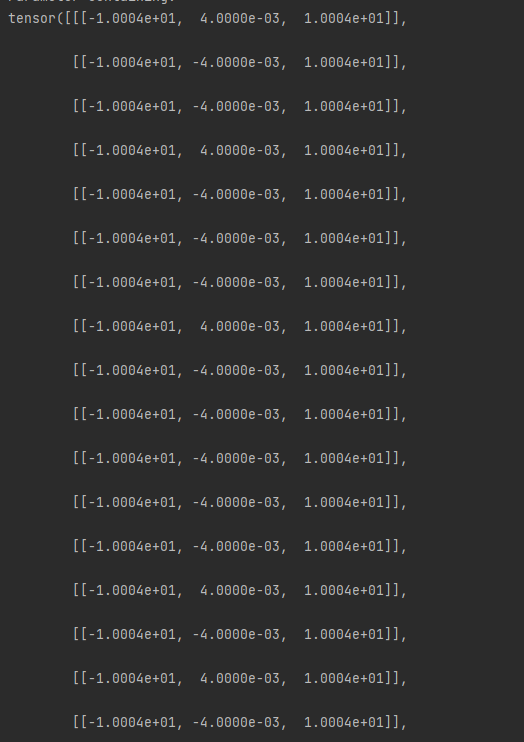 but this is a test train which just has 2 photos and 2 epoch,if you need a entire training,i will train it ,and send you later.
but this is a test train which just has 2 photos and 2 epoch,if you need a entire training,i will train it ,and send you later.
another question is i dont know why when i train it more than 100 epochs,the value of test MSE loss will be very unstable and large.you can comprare these two output. 100 epoch output.txt 150epoch output.txt first one is 100epoch training,test MSE loss will steadily decline but second one is 150epoch training,test MSE loss acting very strange Whether this is related to the fact that my test dataset has only 24 images, but I don't think it's the reason. It may be related to learning rate.