Batching Bags Causes Timeout Errors
What steps does it take to reproduce the issue?
When does this issue occur?
When running bagit command via a shell script with this command:
curl -H "X-Dataverse-key: $KEY_PROD" http://localhost:8080/api/admin/submitDataVersionToArchive/:persistentId/$version?persistentId=doi:$doi
@qqmyers suggested that I click around on the server GUI, while the bagit was running. The browser developer/network screen shots are below.
What happens? Bagit starts to time out and mostly empty zips are created - until we stop the script
When the script (command) is being run the system is unusable/unresponsive. See the screen shots.
Which version of Dataverse are you using?
V5.9
Screenshots:



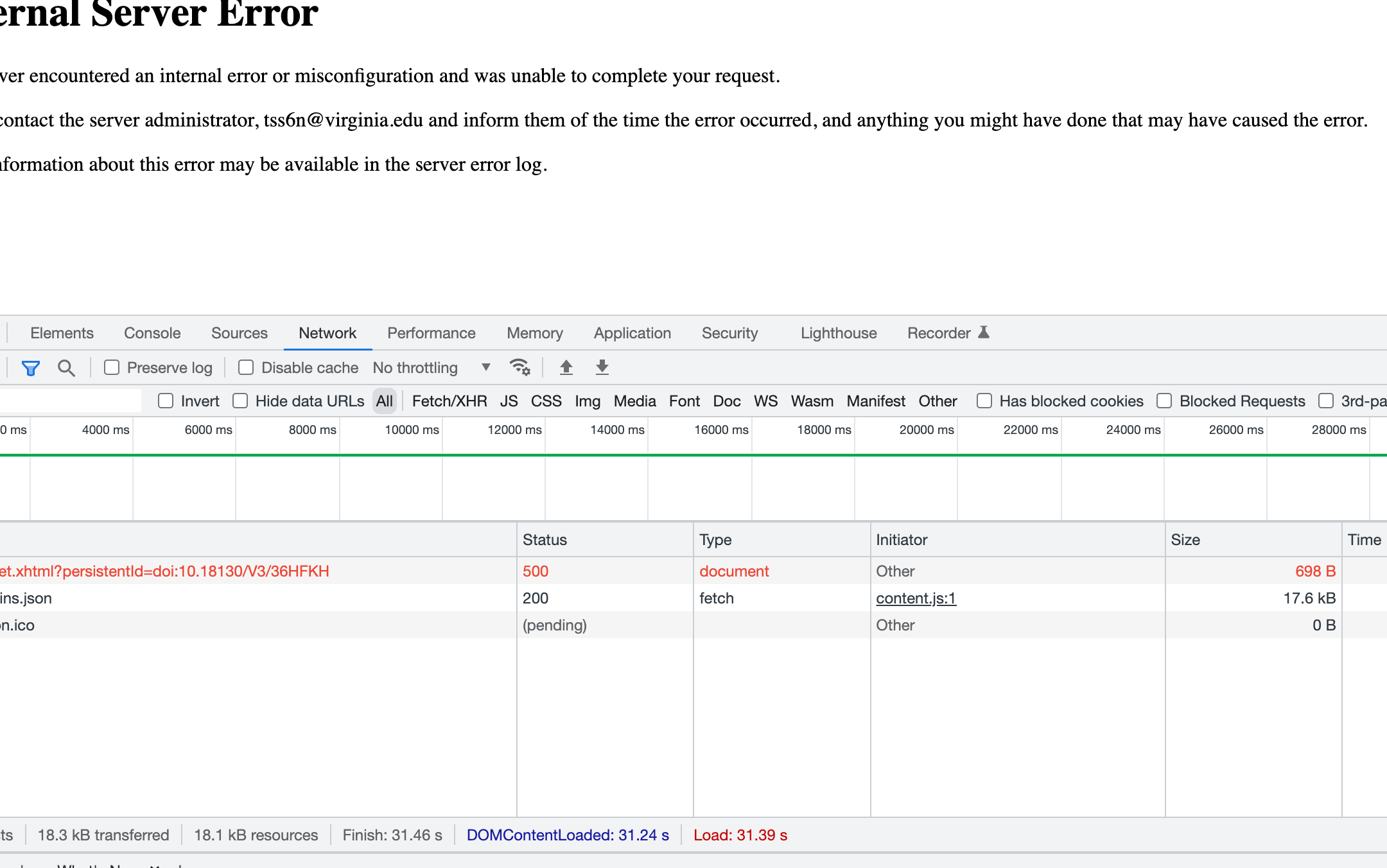


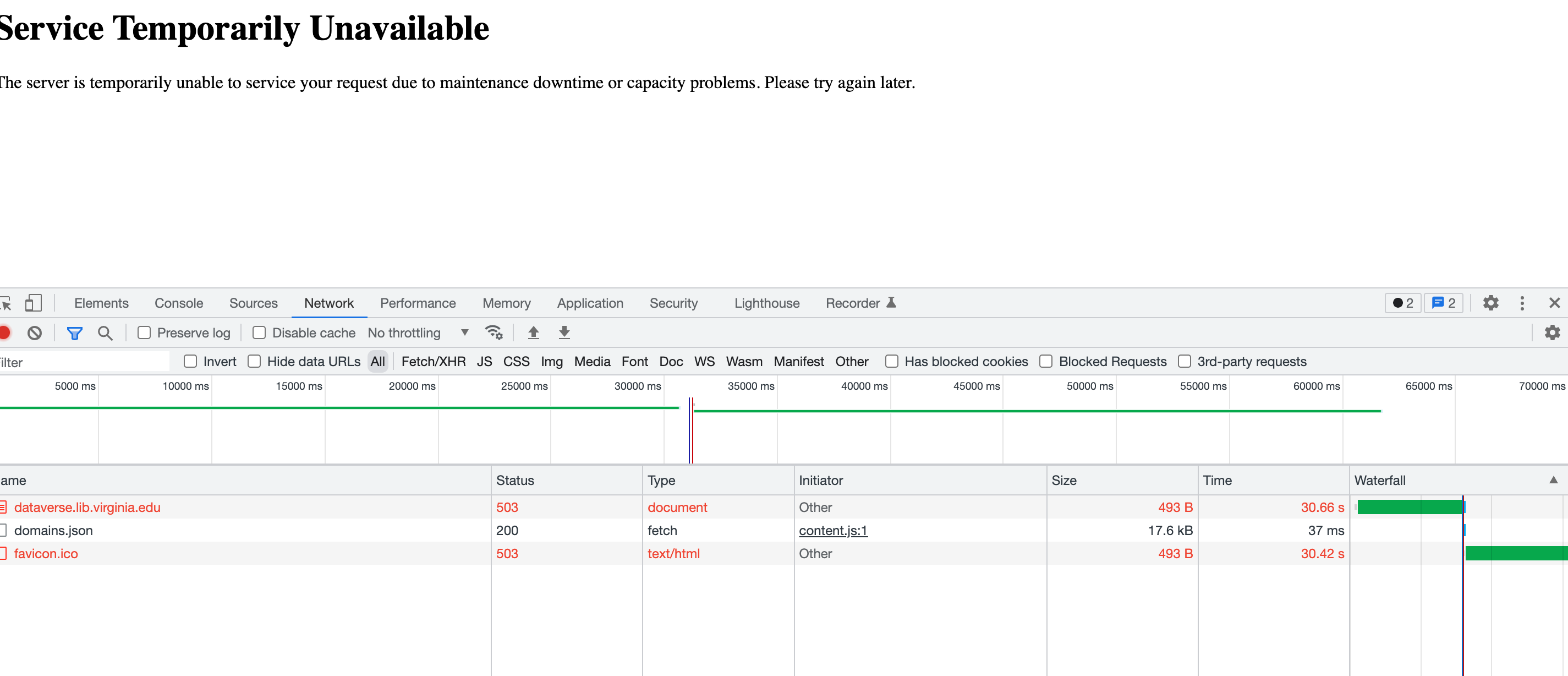
Partial Log
I can send more:
[2022-03-24T11:23:43.690-0400] [Payara 5.2021.10] [SEVERE] [] [edu.harvard.iq.dataverse.util.bagit.BagGenerator] [tid: _ThreadID=18658 _ThreadName=pool-389-thread-8] [timeMillis: 1648135423690] [levelValue: 1000] [[ Final attempt failed for https://dataverse.lib.virginia.edu/api/access/datafile/1125]]
[2022-03-24T11:23:43.690-0400] [Payara 5.2021.10] [SEVERE] [] [edu.harvard.iq.dataverse.util.bagit.BagGenerator] [tid: _ThreadID=18658 _ThreadName=pool-389-thread-8] [timeMillis: 1648135423690] [levelValue: 1000] [[ Could not read: https://dataverse.lib.virginia.edu/api/access/datafile/1125]]
[2022-03-24T11:23:43.690-0400] [Payara 5.2021.10] [SEVERE] [] [] [tid: _ThreadID=18658 _ThreadName=pool-389-thread-8] [timeMillis: 1648135423690] [levelValue: 1000] [[ org.apache.http.conn.ConnectionPoolTimeoutException: Timeout waiting for connection from pool at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.leaseConnection(PoolingHttpClientConnectionManager.java:316) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager$1.get(PoolingHttpClientConnectionManager.java:282) at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:190) at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186) at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89) at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110) at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:108) at edu.harvard.iq.dataverse.util.bagit.BagGenerator$3.get(BagGenerator.java:1004) at org.apache.commons.compress.archivers.zip.ZipArchiveEntryRequest.getPayloadStream(ZipArchiveEntryRequest.java:62) at org.apache.commons.compress.archivers.zip.ScatterZipOutputStream.addArchiveEntry(ScatterZipOutputStream.java:99) at org.apache.commons.compress.archivers.zip.ParallelScatterZipCreator.lambda$createCallable$1(ParallelScatterZipCreator.java:229) at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) at java.base/java.lang.Thread.run(Thread.java:834) ]]
[2022-03-24T11:23:43.780-0400] [Payara 5.2021.10] [SEVERE] [] [edu.harvard.iq.dataverse.api.Admin] [tid: _ThreadID=18650 _ThreadName=Thread-414] [timeMillis: 1648135423780] [levelValue: 1000] [[ Error submitting version due to conflict/error at Archive]]
[2022-03-24T11:23:44.308-0400] [Payara 5.2021.10] [FINE] [] [edu.harvard.iq.dataverse.util.bagit.BagGenerator] [tid: _ThreadID=19068 _ThreadName=pool-435-thread-1] [timeMillis: 1648135424308] [levelValue: 500] [CLASSNAME: edu.harvard.iq.dataverse.util.bagit.BagGenerator$3] [METHODNAME: get] [[ Status: 500]]
[2022-03-24T11:23:44.308-0400] [Payara 5.2021.10] [FINE] [] [edu.harvard.iq.dataverse.util.bagit.BagGenerator] [tid: _ThreadID=19068 _ThreadName=pool-435-thread-1] [timeMillis: 1648135424308] [levelValue: 500] [CLASSNAME: edu.harvard.iq.dataverse.util.bagit.BagGenerator$3] [METHODNAME: get] [[ Get # 1 for https://dataverse.lib.virginia.edu/api/access/datafile/1694]]
[2022-03-24T11:23:44.529-0400] [Payara 5.2021.10] [WARNING] [] [edu.harvard.iq.dataverse.util.bagit.BagGenerator] [tid: _ThreadID=18144 _ThreadName=pool-333-thread-4] [timeMillis: 1648135424529] [levelValue: 900] [[ Attempt# 5 : Unable to retrieve file: https://dataverse.lib.virginia.edu/api/access/datafile/234 org.apache.http.conn.ConnectionPoolTimeoutException: Timeout waiting for connection from pool at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.leaseConnection(PoolingHttpClientConnectionManager.java:316) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager$1.get(PoolingHttpClientConnectionManager.java:282) at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:190) at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186) at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89) at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110) at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:108) at edu.harvard.iq.dataverse.util.bagit.BagGenerator$3.get(BagGenerator.java:1004) at org.apache.commons.compress.archivers.zip.ZipArchiveEntryRequest.getPayloadStream(ZipArchiveEntryRequest.java:62) at org.apache.commons.compress.archivers.zip.ScatterZipOutputStream.addArchiveEntry(ScatterZipOutputStream.java:99) at org.apache.commons.compress.archivers.zip.ParallelScatterZipCreator.lambda$createCallable$1(ParallelScatterZipCreator.java:229) at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) at java.base/java.lang.Thread.run(Thread.java:834) ]]
[2022-03-24T11:23:44.529-0400] [Payara 5.2021.10] [SEVERE] [] [edu.harvard.iq.dataverse.util.bagit.BagGenerator] [tid: _ThreadID=18144 _ThreadName=pool-333-thread-4] [timeMillis: 1648135424529] [levelValue: 1000] [[ Final attempt failed for https://dataverse.lib.virginia.edu/api/access/datafile/234]]
[2022-03-24T11:23:44.529-0400] [Payara 5.2021.10] [SEVERE] [] [edu.harvard.iq.dataverse.util.bagit.BagGenerator] [tid: _ThreadID=18144 _ThreadName=pool-333-thread-4] [timeMillis: 1648135424529] [levelValue: 1000] [[ Could not read: https://dataverse.lib.virginia.edu/api/access/datafile/234]]
[2022-03-24T11:23:44.529-0400] [Payara 5.2021.10] [SEVERE] [] [] [tid: _ThreadID=18144 _ThreadName=pool-333-thread-4] [timeMillis: 1648135424529] [levelValue: 1000] [[ org.apache.http.conn.ConnectionPoolTimeoutException: Timeout waiting for connection from pool at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.leaseConnection(PoolingHttpClientConnectionManager.java:316) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager$1.get(PoolingHttpClientConnectionManager.java:282) at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:190) at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186) at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89) at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110) at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:108) at edu.harvard.iq.dataverse.util.bagit.BagGenerator$3.get(BagGenerator.java:1004) at org.apache.commons.compress.archivers.zip.ZipArchiveEntryRequest.getPayloadStream(ZipArchiveEntryRequest.java:62) at org.apache.commons.compress.archivers.zip.ScatterZipOutputStream.addArchiveEntry(ScatterZipOutputStream.java:99) at org.apache.commons.compress.archivers.zip.ParallelScatterZipCreator.lambda$createCallable$1(ParallelScatterZipCreator.java:229) at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) at java.base/java.lang.Thread.run(Thread.java:834) ]]
Related thread: https://groups.google.com/g/dataverse-community/c/gj6wPMqxF_0/m/eiLQFBwRBQAJ
FWIW: In general, I think these are consistent with the Bag generation using up the available connections. (Although 'Error submitting version due to conflict/error at Archive' seems like the script was trying the same datasetversion as a previous attempt.) If the files are on S3, increasing the S3 connection pool size might help (added in some recent release.) Otherwise, the workaround would probably be to slow the script down.
The better long term option will be the new batch API (being supported by/tested at TDL now) that queues up jobs to archive all unarchived versions or just the most recent version of each dataset if that's not archived. This API creates a given bag using ~4 threads (as happens today) but waits for each Bag to complete before doing the next so it shouldn't use as many resources as firing off more than one archiving job in parallel. FWIW: There are also changes coming to support having a status for archiving jobs (particularly useful if the archive has internal processing steps) which will add an API to get the status. That would allow a script to poll to see if the current archiving job is complete before launching the next if you don't want to use the batch api.
(It may also be possible to change the current Java code to use the @Asynchronous annotation and use Java EE's capabilities to limit the number of threads that can be used across all invocations of the archive API. I think that could avoid a situation where archiving jobs use all the connections to S3 and interfere with the UI.)
@qqmyers I did some more testing on bagit -
'Error submitting version due to conflict/error at Archive' I think is because our script is trying to bag each version, which of course may have the "same" files. (we will stop bagging every version and only bag the latest version - for this initial grab "all" UVa Dataverse datasets)
Another "back of the envelope" calculation as to how long bagging jobs take, found that a ~200MB zip (to completion) took 3 minutes and ~600MB zip (to completion) took 8 minutes.
We are running local servers (CentOS currently - preparing for the cloud in 3 months or so!!!)
Waiting in anticipation for the TDL batch bagit API. ;-)
Hmm - the bags should be named per version and shouldn't collide with other versions. It's possible that that is messed up in some archiver - which archiving class are you using.
Also - FWIW: In running the batch API at TDL, we ran into old test datasets missing files (i.e. the actual bytes on disk had been deleted) which allowed me to find a couple subtle bugs where those 404 calls would keep open connections and cause further ones to fail, and a bug where a partial bag could be created. Those fixes will also be coming in and may be part of what you saw above. (And, between TDL and DataCommons, we'll have a way to mark archiving attempts as 'failed' so that further batch calls won't retry ones where the files are missing on disk.)
It is not the zip filenames that are causing the problem. Yes, each version gets its own zip.
I think it is a problem that one bagit command is accessing (or trying to) the same file as another bagit command (for a different version of the same dataset). The script is trying the same dataset files as a previous attempt (because it is just a different version of the dataset).
Hmm - trying to archive multiple versions could have the problems you're describing but the "Error submitting version due to conflict/error at Archive" error should only be from a problem with creating folders/files/s3 objects/Duracloud space/object etc on the target archive. It's possible that some other error with two versions running at the same time (like you describe) is triggering that warning by mistake instead of reporting what really went wrong.
The better long term option will be the new batch API
The batch API shipped with 5.12 according to the release notes:
"Support for batch archiving via API as an alternative to the current options of configuring archiving upon publication or archiving each dataset version manually."
@shlake does that help?
2023/09/25: Added to 6.1 milestone as per conversation during prioritization meeting. 2023/09/25: Follow up with @shlake to find out if the problem is still happening in 5.1.4.
- @shlake will retry using 5.14 and report back
@cmbz UVa is at 5.14 and have successfully bagged our datasets.
We did not experience any time out issues.
This issue can be closed. Thanks.