About the training on our datasets
Thansk, we have learned a lot from your excellent work, we train the MaskDINO on a self-built datasets containing 2000 images, after 40000 iters, the metrics are nearly AP,AP50,AP75,APs,APm,APl 74.8523,92.0707,81.0479,44.8492,79.8165,77.5198
the metrics are pretty good! however, after the visulize of prediction results, there are much boundboxes around a same object, and there are much small areas on the big object,
Since DETR serial methods generally do not need to use NMS, I may want to know do you meet this question in the testing phase, how to solve this problem?
thanks again

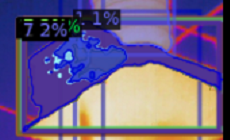 and this, two much small regions are segmented and apper on the big objectes.
and this, two much small regions are segmented and apper on the big objectes.
The AP is pretty high, therefore the predictions are supposed to have very few duplicate predictions. As we are using the sigmoid focal loss, so for visualization, you need to set a threshold for the predictions, for example, only select the prediction with a classification score larger than 0.3. You can also change this threshold to find the optimal one.
thanks for your response, we have tried to change the OVERLAP_THRESHOLD, OBJECT_MASK_THRESHOLD (in config file) and confidence-threshold (in demo.py) But it does not work.
where to change the classification score and any other threshold ?
thanks again
Meanwhile, as the output in dashboard 'detected 100 instances in 3.34s' since the query number is set as 100 there are only about 10 instances in the images, should we minimize the query numbers to obtain better results?
You need to write a visualization script, in which you manually select the queries with classification scores larger than 0.3, and then visualize them.
100 queries is good in your case.