label-studio-ml-backend
 label-studio-ml-backend copied to clipboard
label-studio-ml-backend copied to clipboard
get_result_from_job_id AssertionError while initializing redeployed LS/ML NER backend
I am trying to deploy NER example model trained on my local machine along with the Label Studio project to another machine. I've gone through following steps:
- Recreated Label Studio and ML Backend environments similarly as on a target machine
- Copied folder with the model itself (folder named with just integers) to target machine ML Backend folder.
- Extracted content (data, annotations and predictions) of the project through Label Studio API into json format (using
...export?exportType=JSON&download_all_tasks=truecommand) - Imported project json file into the newly created Label Studio project.
When trying to initialize and pair LS and ML Backend on a new machine, i am getting :
[2022-05-30 10:18:56,133] [ERROR] [label_studio_ml.model::get_result_from_last_job::128] 1647350146 job returns exception: Traceback (most recent call last): File "/Users/user/Projects/label-studio-ml-backend/label_studio_ml/model.py", line 126, in get_result_from_last_job result = self.get_result_from_job_id(job_id) File "/Users/user/Projects/label-studio-ml-backend/label_studio_ml/model.py", line 108, in get_result_from_job_id assert isinstance(result, dict) AssertionErrorand it keeps repeating for each job
Should any additional steps be performed during deploy of the project/model to other environments ?
I've tried with following LS versions (1.1.1 - my initial one, 1.4.1post1 - most recent one) and the most current code base of ML backend. Using Python 3.8 and MacOS for both source and target environments.
Hi @wojnarabc This error indicates that training of your model ended without any contrete result. ner example doesn't have fit method, but you can add it like that:
def fit(self, completions, workdir=None, **kwargs):
import random
return {'random': random.randint(1, 10)}
and the error should disappear. I will add this stub to the ner example in future release.
If you are using TransformersBasedTagger - please check that fit method ends with appropriate result.
Hello @KonstantinKorotaev, there is a fit method in example in ...examples/ner/ner.py folder starting in line 461. TransformersBasedTagger is part of it.
I run into the exact same problem with my custom backend.
I am in the process of upgrading my system to the latest LS and backend. Everything was working fine with LS 1.1.1 and the backend from a year ago.
After training, another job is sent for some reason, and then train_output is being cleared causing the backend to lose the knowledge about the last trained model.
I already set LABEL_STUDIO_ML_BACKEND_V2_DEFAULT = True
'train_output': {'model_path': '././my_backend/5.1655881660/1658156596'},
'value': 'image'}
[2022-07-18 17:03:37,760] [INFO] [werkzeug::_log::225] 192.168.123.133 - - [18/Jul/2022 17:03:37] "POST /train HTTP/1.1" 201 -
[2022-07-18 17:03:37,781] [INFO] [werkzeug::_log::225] 192.168.123.133 - - [18/Jul/2022 17:03:37] "GET /health HTTP/1.1" 200 -
[2022-07-18 17:03:37,787] [ERROR] [label_studio_ml.model::get_result_from_last_job::130] 1658156583 job returns exception:
Traceback (most recent call last):
File "/home/USER/.virtualenvs/ls-1.5/lib/python3.8/site-packages/label_studio_ml/model.py", line 128, in get_result_from_last_job
result = self.get_result_from_job_id(job_id)
File "/home/USER/.virtualenvs/ls-1.5/lib/python3.8/site-packages/label_studio_ml/model.py", line 110, in get_result_from_job_id
assert isinstance(result, dict)
AssertionError
So, to be more clear, I based my custom backend on pytorch_transfer_learning.py. I had to set LABEL_STUDIO_ML_BACKEND_V2_DEFAULT = True in model.py, because otherwise I run into the issue described in #118.
Now, when I monitor train_output after training, label studio initializes the backend with the correct train_output. But immediately after, another initialization event follows with an empty train_output.
I made an ugly workaround for this issue using an OS environment variable that saves the location of last trained model locally. Note that this causes issues if users switch between projects and it won't redeploy an existing model.
# ...
from label_studio_ml import model
model.LABEL_STUDIO_ML_BACKEND_V2_DEFAULT = True
# ...
class ImageClassifierAPI(model.LabelStudioMLBase):
def __init__(self, label_config=None, train_output=None,**kwargs):
super(ImageClassifierAPI, self).__init__(**kwargs)
# ...
if self.train_output:
print(f"trying to use {self.train_output['model_path']} as model path")
self.model = ImageClassifier(self.classes, self.boxType)
self.model.load(self.train_output['model_path'])
elif os.environ.get("LAST_TRAINED_MODEL") is not None:
model_path = os.environ.get("LAST_TRAINED_MODEL")
print(f"trying to use {model_path} as model path")
self.model = ImageClassifier(self.classes, self.boxType)
self.model.load(model_path)
else:
self.model = ImageClassifier(self.classes, self.boxType)
# ...
def fit(self, annotations, workdir=None, batch_size=12, num_epochs=100, **kwargs):
self.model.train(annotations, workdir, self.boxType, batch_size=batch_size, num_epochs=num_epochs)
# Save workdir in environment
os.environ["LAST_TRAINED_MODEL"] = workdir
return {'model_path': workdir}
Having to manually change LABEL_STUDIO_ML_BACKEND_V2_DEFAULT = True and Label studio loosing the returned dict from the fit function is a bit awkward to work with though.
@jrdalenberg LABEL_STUDIO_ML_BACKEND_V2_DEFAULT this variable tells your ML backend that you are using active learning cycle. Starting from version 1.4.1 of Label Studio training is invoked with webhooks. Please check this documentation.
def fit(self, annotations, workdir=None, batch_size=12, num_epochs=100, **kwargs): self.model.train(annotations, workdir, self.boxType, batch_size=batch_size, num_epochs=num_epochs)
Your fit method seems to be expecting annotations, but from version 1.4.1 there will be an event instead of annotations. Maybe this is leading to empty train_output.
If you want to switch this logic off - disable webhook in LS. Check this example if you want to use active learning cycle.
Your fit method seems to be expecting annotations, but from version 1.4.1 there will be an event instead of annotations. Maybe this is leading to empty train_output.
I see. It’s still odd that train_output is returned once and then cleared right after, though.
Check this example if you want to use active learning cycle.
Thanks! I did not see this in the object recognition examples. I’ll test it out after my vacation 😄
same bug
/opt/label-studio-ml-backend/coco-detector/mmdetection.py(137)fit() -> logger.info(f'tasks={tasks}, workdir={workdir}, kwargs={kwargs}') (Pdb) bt /usr/lib/python3.10/threading.py(966)_bootstrap() -> self._bootstrap_inner() /usr/lib/python3.10/threading.py(1009)_bootstrap_inner() -> self.run() /usr/lib/python3.10/threading.py(946)run() -> self._target(*self._args, **self._kwargs) /usr/lib/python3.10/socketserver.py(683)process_request_thread() -> self.finish_request(request, client_address) /usr/lib/python3.10/socketserver.py(360)finish_request() -> self.RequestHandlerClass(request, client_address, self) /usr/lib/python3.10/socketserver.py(747)init() -> self.handle() /opt/pyvenv-labelstudio-ml-backend/lib/python3.10/site-packages/werkzeug/serving.py(342)handle() -> BaseHTTPRequestHandler.handle(self) /usr/lib/python3.10/http/server.py(425)handle() -> self.handle_one_request() /opt/pyvenv-labelstudio-ml-backend/lib/python3.10/site-packages/werkzeug/serving.py(374)handle_one_request() -> self.run_wsgi() /opt/pyvenv-labelstudio-ml-backend/lib/python3.10/site-packages/werkzeug/serving.py(319)run_wsgi() -> execute(self.server.app) /opt/pyvenv-labelstudio-ml-backend/lib/python3.10/site-packages/werkzeug/serving.py(308)execute() -> application_iter = app(environ, start_response) /opt/pyvenv-labelstudio-ml-backend/lib/python3.10/site-packages/flask/app.py(2464)call() -> return self.wsgi_app(environ, start_response) /opt/pyvenv-labelstudio-ml-backend/lib/python3.10/site-packages/flask/app.py(2447)wsgi_app() -> response = self.full_dispatch_request() /opt/pyvenv-labelstudio-ml-backend/lib/python3.10/site-packages/flask/app.py(1950)full_dispatch_request() -> rv = self.dispatch_request() /opt/pyvenv-labelstudio-ml-backend/lib/python3.10/site-packages/flask/app.py(1936)dispatch_request() -> return self.view_functionsrule.endpoint /opt/label-studio-ml-backend/label_studio_ml/exceptions.py(39)exception_f() -> return f(*args, **kwargs) /opt/label-studio-ml-backend/label_studio_ml/api.py(93)_train() -> job = _manager.train(annotations, project, label_config, **params) /opt/label-studio-ml-backend/label_studio_ml/model.py(711)train() -> job_result = cls.train_script_wrapper( /opt/label-studio-ml-backend/label_studio_ml/model.py(667)train_script_wrapper() -> train_output = m.model.fit(data_stream, workdir, **train_kwargs) /opt/label-studio-ml-backend/coco-detector/mmdetection.py(137)fit() -> logger.info(f'tasks={tasks}, workdir={workdir}, kwargs={kwargs}')
022-08-19 03:17:21,961] [ERROR] [label_studio_ml.model::get_result_from_last_job::131] 1660820149 job returns exception: Traceback (most recent call last): File "/opt/label-studio-ml-backend/label_studio_ml/model.py", line 129, in get_result_from_last_job result = self.get_result_from_job_id(job_id) File "/opt/label-studio-ml-backend/label_studio_ml/model.py", line 111, in get_result_from_job_id assert isinstance(result, dict) AssertionError
# train, see https://labelstud.io/guide/ml_create.html
def fit(self, tasks, workdir=None, **kwargs):
# Retrieve the annotation ID from the payload of the webhook event
# Use the ID to retrieve annotation data using the SDK or the API
# Do some computations and get your model
#import pdb; pdb.set_trace()
logger.info(f'tasks={tasks}, workdir={workdir}, kwargs={kwargs}')
return {'checkpoints': '3.1660708258/1660885087/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth', 'model_file': "3.1660708258/1660885087/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth", "model_version":"3.1660708258/1660885087", 'classes': 80}
## JSON dictionary with trained model artifacts that you can use later in code with self.train_output
Load new model from: /opt/mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py /opt/mmdetection/checkpoints/faster_rcnn/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth load checkpoint from local path: /opt/mmdetection/checkpoints/faster_rcnn/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth Load new model from: /opt/mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py /opt/mmdetection/checkpoints/faster_rcnn/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth load checkpoint from local path: /opt/mmdetection/checkpoints/faster_rcnn/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth [2022-08-19 05:06:31,709] [INFO] [werkzeug::_log::225] 192.168.1.7 - - [19/Aug/2022 05:06:31] "POST /train HTTP/1.1" 201 - [2022-08-19 05:06:32,102] [INFO] [werkzeug::_log::225] 192.168.1.7 - - [19/Aug/2022 05:06:32] "GET /health HTTP/1.1" 200 - Load new model from: /opt/mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py /opt/mmdetection/checkpoints/faster_rcnn/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth load checkpoint from local path: /opt/mmdetection/checkpoints/faster_rcnn/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth [2022-08-19 05:06:33,168] [INFO] [werkzeug::_log::225] 192.168.1.7 - - [19/Aug/2022 05:06:33] "POST /setup HTTP/1.1" 200 -
seems return values not work
Hi @idreamerhx
seems return values not work
I don't see any error in your log, what do you mean by not work?
assert isinstance(result, dict) AssertionError
This means that your training procedure didn't return results, could you please check what your fit method returns?
This should be a bug somehow. Because the results should be a list of dict but it tells me it is wrong.
I mean this assertion is too restrictive. A dummy result would tricker the assertion error. This should not be desired.
I'm also getting the same assertion error problem. Does the model always have to return a dictionary? I'm following the examples provided in Label Studio and it seems like lists of dicts are also allowed: https://github.com/heartexlabs/label-studio-ml-backend/blob/db6d1d6d3efde1db503532f1f77a6977a7f100d2/label_studio_ml/examples/simple_text_classifier/simple_text_classifier.py#L93
Hi @seanswyi Predictions should be a list of dicts. Assertion error is about training job failure.
Errors after setting LABEL_STUDIO_ML_BACKEND_V2_DEFAULT=True in model.py:
[2023-03-14 10:37:49,673] [ERROR] [label_studio_ml.model::get_result_from_last_job::132] 1678761465 job returns exception: Job 1678761465 was finished unsuccessfully. No result was saved in job folder.Please clean up failed job folders to remove this error from log. Traceback (most recent call last): File "label-studio-ml-backend/label_studio_ml/model.py", line 130, in get_result_from_last_job result = self.get_result_from_job_id(job_id) File "label-studio-ml-backend/label_studio_ml/model.py", line 111, in get_result_from_job_id assert isinstance(result, dict), f"Job {job_id} was finished unsuccessfully. No result was saved in job folder."
AssertionError: Job 1678761465 was finished unsuccessfully. No result was saved in job folder.Please clean up failed job folders to remove this error from log. [2023-03-14 10:37:49,673] [ERROR] [label_studio_ml.model::get_result_from_last_job::132] 1678761463 job returns exception: Job 1678761463 was finished unsuccessfully. No result was saved in job folder.Please clean up failed job folders to remove this error from log. Traceback (most recent call last): File "label-studio-ml-backend/label_studio_ml/model.py", line 130, in get_result_from_last_job result = self.get_result_from_job_id(job_id) File "label-studio-ml-backend/label_studio_ml/model.py", line 111, in get_result_from_job_id assert isinstance(result, dict), f"Job {job_id} was finished unsuccessfully. No result was saved in job folder."
AssertionError: Job 1678761463 was finished unsuccessfully. No result was saved in job folder.Please clean up failed job folders to remove this error from log.
How should we work around?
Assertion error is about training job failure.
Do you have folders with job results 1678761463 and 1678761465?
Hello, I have the same problem:
I've created a custom backend based on example in mmdetection.py. I don't use active learning (I think, i did not set that up). Every time I will switch to next image for annotation, I am getting this output in console:
[2023-03-17 09:30:05,107] [ERROR] [label_studio_ml.model::get_result_from_last_job::132] 1679041803 job returns exception: Job 1679041803 was finished unsuccessfully. No result was saved in job folder.Please clean up failed job folders to remove this error from log.
Traceback (most recent call last):
File "d:\coding\developement\python\label-studio-ml-backend\label_studio_ml\model.py", line 130, in get_result_from_last_job
result = self.get_result_from_job_id(job_id)
File "d:\coding\developement\python\label-studio-ml-backend\label_studio_ml\model.py", line 111, in get_result_from_job_id
assert isinstance(result, dict), f"Job {job_id} was finished unsuccessfully. No result was saved in job folder." \
AssertionError: Job 1679041803 was finished unsuccessfully. No result was saved in job folder.Please clean up failed job folders to remove this error from log.
The exception is caused because _get_result_from_job_id is returning None because os.path.exists(result_file) is returning False:
def _get_result_from_job_id(self, job_id):
"""
Return job result or {}
@param job_id: Job id (also known as model version)
@return: dict
"""
job_dir = self._job_dir(job_id)
if not os.path.exists(job_dir):
logger.warning(f"=> Warning: {job_id} dir doesn't exist. "
f"It seems that you don't have specified model dir.")
return None
result_file = os.path.join(job_dir, self.JOB_RESULT)
if not os.path.exists(result_file): <--- THIS CHECK RESULTS IN FLSE
logger.warning(f"=> Warning: {job_id} dir doesn't contain result file. "
f"It seems that previous training session ended with error.")
return None
logger.debug(f'Read result from {result_file}')
with open(result_file) as f:
result = json.load(f)
return result
What is strange for me is that I do have job_result.json file in the required directory but probably it is not there when the check occurs? It must be created later. The contents of file is empty json.
and here is my predict() method:
def predict(self, tasks, **kwargs):
assert len(tasks) == 1
task = tasks[0]
image_url = self._get_image_url(task)
image_path = self.get_local_path(image_url)
image = cv2.imread(image_path)
output = Inference.infer_from_image(self.model, image)
indices, boxes, confidences = Inference.filter_outputs(self.config, image, output)
results = []
all_scores = []
for i in indices:
score = confidences[i]
# print(f'{confidences[i]:.2f}')
x, y, width, height = self.convert_to_ls(boxes[i][0], boxes[i][1], boxes[i][2], boxes[i][3], image.shape[1], image.shape[0])
results.append({
'from_name': self.from_name,
'to_name': self.to_name,
'type': 'rectanglelabels',
'value': {
'rectanglelabels': ['head'],
'x': x,
'y': y,
'width': width,
'height': height
},
'score': float(score)
})
all_scores.append(score)
avg_score = sum(all_scores) / max(len(all_scores), 1)
return [{
'result': results,
'score': float(avg_score)
}]
But I dont think this is due to predict() as I've said earlier, the check:
if not os.path.exists(result_file): is failing for some reason.
Hi @TrueWodzu
What is strange for me is that I do have job_result.json file in the required directory but probably it is not there when the check occurs? It must be created later. The contents of file is empty json.
This file is created during training session. If it is empty - training session ended with error.
Hi @KonstantinKorotaev thank you for your answer. So is this bug? Because it seems like the file is required but at the same time, some of us don't want to train. How can I prevent it from happening?
@KonstantinKorotaev I don't have training turned on so def _get_result_from_job_id(self, job_id): should handle a case where training is not on and do not throw exception?
A simple change in the code solves the problem of exception:
def _get_result_from_job_id(self, job_id):
"""
Return job result or {}
@param job_id: Job id (also known as model version)
@return: dict
"""
job_dir = self._job_dir(job_id)
if not os.path.exists(job_dir):
logger.warning(f"=> Warning: {job_id} dir doesn't exist. "
f"It seems that you don't have specified model dir.")
return None
result_file = os.path.join(job_dir, self.JOB_RESULT)
if not os.path.exists(result_file):
logger.warning(f"=> Warning: {job_id} dir doesn't contain result file. "
f"It seems that previous training session ended with error.")
return {} <---- A simple change here from None to empty json solves the issue.
logger.debug(f'Read result from {result_file}')
with open(result_file) as f:
result = json.load(f)
return result
Hi @TrueWodzu I have added environment variable to integrate your changes in branch. Please check if it's appropriate solution for you.
Hi @KonstantinKorotaev many thanks for the change! While it definitely works for me, I am just wondering is this a correct approach? What I mean by that is, is it really required right now to have fit method defined? Because in LabelStudio project I have training turned off:
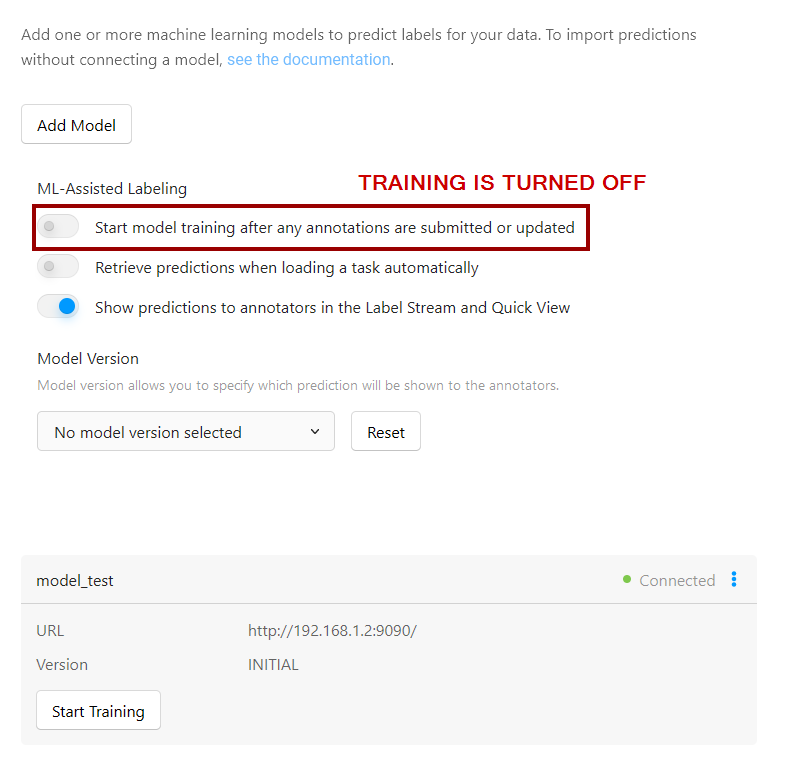
So if I have training turned off, then there should be no exception about result_file?
Hi @TrueWodzu
So if I have training turned off, then there should be no exception about result_file?
Yes, but intention for this error is to get message in case of anybody tried to load model that wasn't trained successfully. I will add this flag so anybody can ignore such errors in future.