Randomness control for different `exploration_frac` in preference comparisons
Background
- Previously,
exploration_fracwas implemented to add exploratory trajectories for preference comparisons. Its aim was to add diversity to the dataset in order to escape from local minimum if any. - In particular,
int(exploration_frac * steps)transitions will be generated by\epsilon-greedily apply the current policy after generating the normal transitions.
Problems
- Transition distribution shifts between normal vs. exploratory trajectories due to default
deterministic_policyto be true. - Uncontrolled randomness among equivalent settings due to rounding, parallelisation and shuffling procedures.
1) Transition distribution shifts between normal vs. exploratory trajectories due to default deterministic_policy to be true for exploratory trajectories.
- For normal trajectories, policy actions are generated stochastically (default to be non-deterministic policy).
- For exploratory trajectories, policy actions are generated deterministically from the mode action of the current policy distribution.
- Hence, the transition distribution shifts comes from (A) shifting between current policy and random policy, and (B) choosing actions deterministically with the highest probability. We indeed want (A) to increase exploration, but not (B) because (B) might strongly increase exploitation especially with a low
random_prob. - In extreme cases, for equivalent settings below, the training curves could be much different.
a.
exploration_frac==0.0b.exploration_frac==0.2 & trajectory_generator_kwargs.random_prob=0.0
2) Uncontrolled randomness among equivalent settings due to rounding, parallelisation and shuffling procedures.
- Applying
rollout.generate_trajectories()twice might increase the number of total trajectories sampled by 1 due to rounding issues. - The algorithm buffer will collect all trajectories collected from all
SubProcessVecEnv. Oversampling might happen if having a largercommon.num_vec. - Trajectories are shuffled twice when we apply
rollout.generate_trajectories()twice.
Solutions
-
Turn
deterministic_policytoFalsefor the exploration wrapper. -
It seems to take more changes to fix 2) by changing how we collect the trajectories. If the empirical results of fixing 1) show little difference between training curves, we might be able to ignore this.
Thanks for spotting and describing this, not sure why I set deterministic_policy=True in the exploration wrapper. So it should be fine to make that False, at least I agree it should be the same in both cases. In your plot, it looks like having 20% deterministic trajectories helps to learn faster, right? If that's a consistent effect, maybe we'd want to switch everything to deterministic---or if that doesn't work, maybe we need a mixture that's consistent across exploratory and policy trajectories? Though I will say that non-deterministic policies sound like the more natural thing to me, so I'd be slightly inclined to just go with that if we have no idea what's better.
Re 2): if we can somehow avoid the pretty complicated code that's currently necessary because we have to sample twice, then that'd be great anyway. Not sure how though, and I'd hope the effects you describe aren't that big. (At least not systematically---they might very well lead to variance on the same order as the random seed, but that seems acceptable to me, I don't think the equivalent settings you describe need to give literally identical results)
I agree 1) should be fixed, just making the deterministic policy consistent between both (likely defaulting to False) seems fine for now.
For 2) I think we should test empirically the difference across multiple seeds. If mean value is not statistically significantly different, I think it's OK for these to be different. If we wanted though we could probably fix the over-sampling by truncating ( but this is a bit of a waste of compute...) and shuffle once on the outside after concatenating the trajectories. There'll still be some differences though due to different environment initial states in the environment (it may have been reset more times in the exploration_frac>0 case), but this really should not change the distribution.
Here are some empirical results on 1):
It seems that adding deterministic trajectories indeed helps to learn faster, but I guess if we want to turn PPO to deterministic, we should do it when we initialise the algorithm, right? Otherwise, it could be hard to keep track of the version of algorithm we're using. This also suggests the problem (1) we identified indeed changes the trajectory distribution.
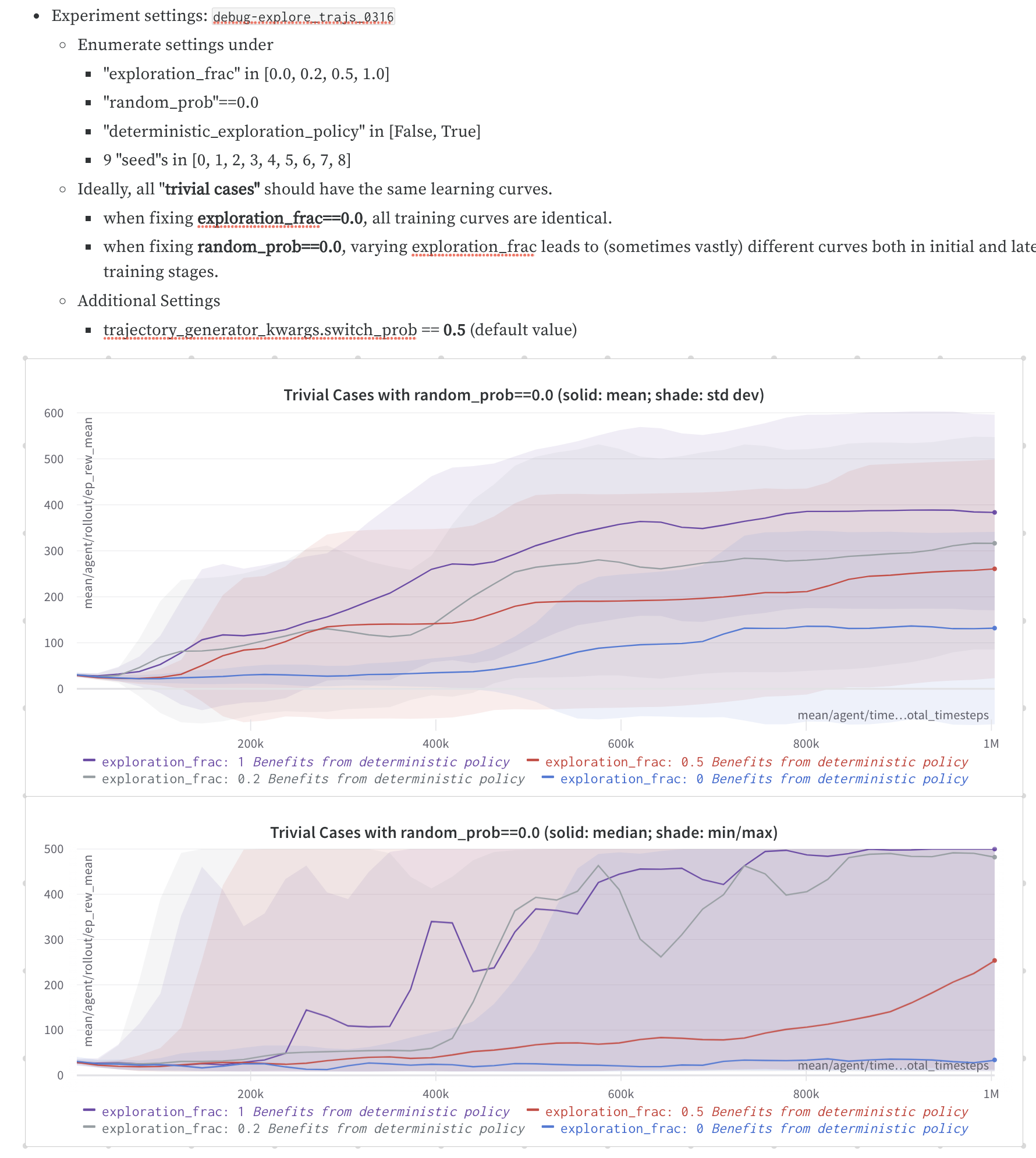
By setting up deterministic policies for both normal and exploratory trajectories, here are some experiment results. It's hard to conclude different settings give similar results because of high variance across different seeds.
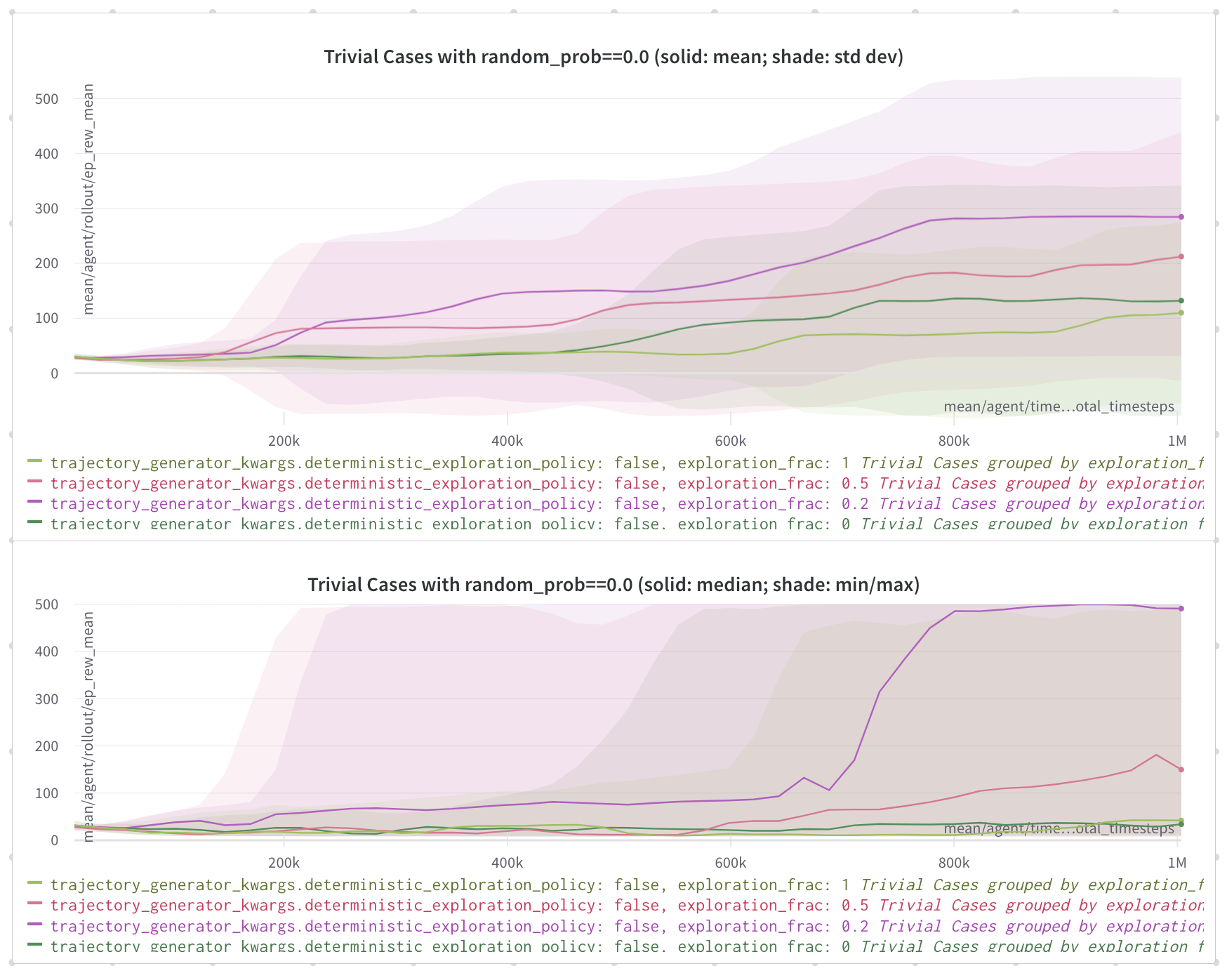
My next step is to control the factors in (2) and see if they give similar results.
I don't think we want PPO to be deterministic. If I understand correctly, rollouts collected for purpose of RL training will always need to be stochastic (this is where the exploration comes from in policy gradients), so the trajectories we get from buffering wrapper will be stochastic. Probably best to keep it consistent stochastic everywhere.
If there's a big performance difference, we could consider not reusing the RL-sampled rollouts, and always sample deterministic trajectories ourselves. (This would also help avoid the mild difference in distribution between buffering wrapper, collected over multiple policy updates, and additional rollouts.) But while this might be more efficient in # of timesteps of reward training, it may not be in terms of wallclock time, as the buffering wrapper rollouts are effectively free.
To check I understand the first figure -- higher exploration_frac corresponds to higher # of deterministic samples? The SD of these is quite big, so I hesitate to conclude much, but it does look like exploration_frac (determinism, ironically) is positively correlated with return.
I don't think we want PPO to be deterministic.
I agree. Pull request made in #423.
To check I understand the first figure -- higher exploration_frac corresponds to higher # of deterministic samples? The SD of these is quite big, so I hesitate to conclude much, but it does look like exploration_frac (determinism, ironically) is positively correlated with return.
Yes. Because random_prob is set to be 0, all the exploratory trajectories are "deterministically" generated, and exploration_frac is positively correlated with return.