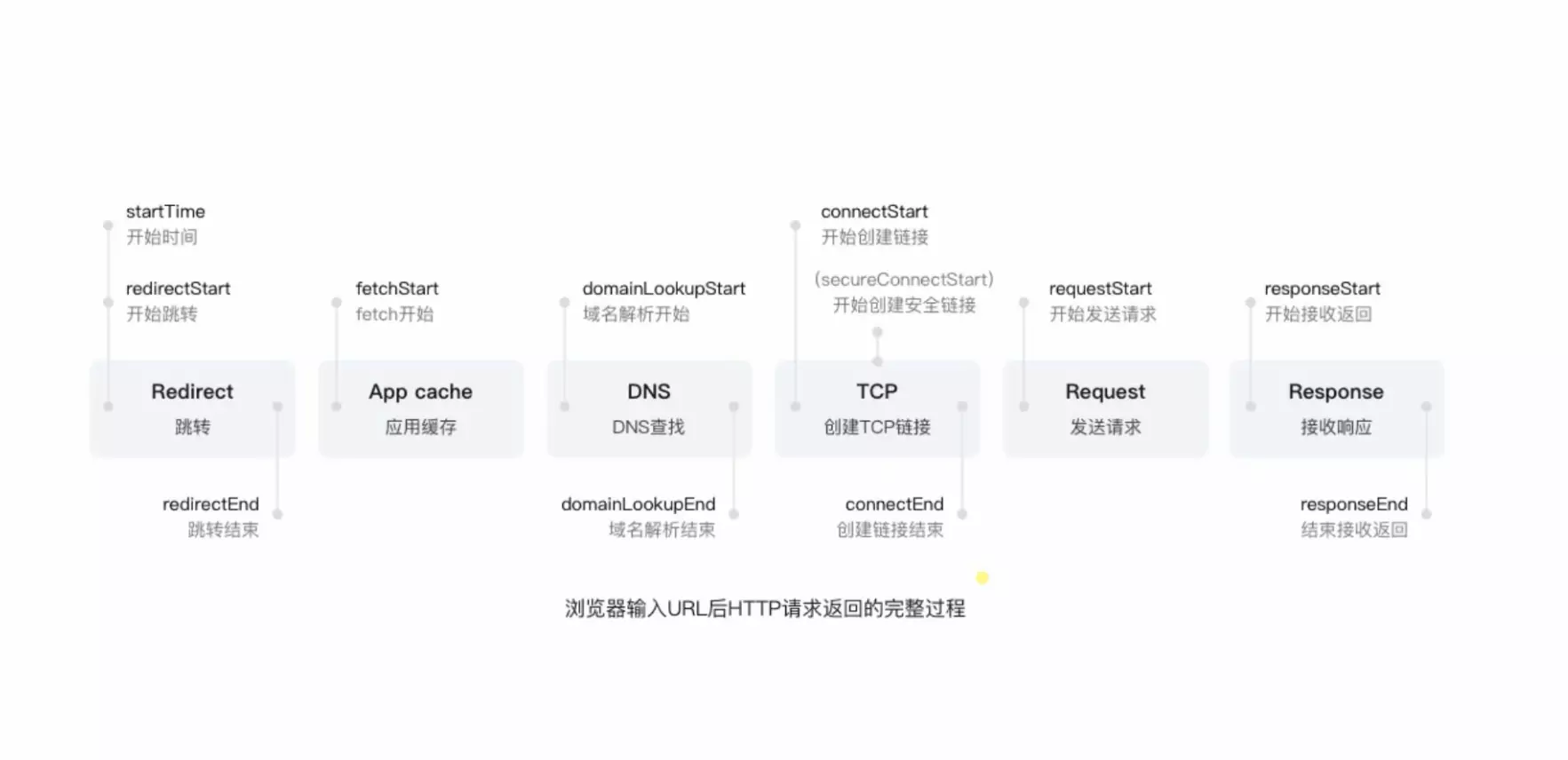
关于浏览器输入URL后HTTP请求返回的经历的过程
-
跳转,Redirect 301 Move Permanently(永久移动); 302 Found 临时移动 类似 307 Temporary Redirect【注意区别 304 Not Modified】
-
是否有缓存,APP cache 304 Not Modified 200 from memory cch
-
DNS查找,域名解析ip 客户端收到你输入的域名地址后,它首先去找本地的hosts文件,检查在该文件中是否有相应的域名、IP对应关系,如果有,则向其IP地址发送请求,如果没有,再去找DNS服务器。一般用户很少去编辑修改hosts文件。
-
创建TCP/IP链接,Tcp三次握手 完后才有http keep-alive 长链接(http1.1才有), HTTP寻在TCP之上
-
发送请求,Request
-
web服务器处理请求和转发: 如Apache、Tomcat、Node.js等服务器,浏览器开始下载HTML文档(响应报头状态码为200时)或者从本地缓存读取文件内容(浏览器缓存有效或响应报头状态码为304时)。
-
接收响应,Response
-
解析渲染DOM,CSS根据规则解析并结合DOM文档树进行网页内容布局和绘制渲染,Javascript提供DOM API操作 DOM,并读取浏览器缓存、执行事件绑定等,页面整个展示过程完成
但问题的答案并不是唯一的,或许在三五年前,这个问题还会有一个「相对」标准的答案。
- 浏览器在接收到这个指令时,会开启一个单独的线程来处理这个指令,首先要判断用户输入的是否为合法或合理的 URL 地址,是否为 HTTP 协议请求,如果是那就进入下一步
- 浏览器的浏览器引擎将对此 URL 进行分析,如果存在缓存「cache-control」且未过期,则会从本地缓存提取文件(From Memory Cache,200返回码),如果缓存「cache-control」不存在或过期,浏览器将发起远程请求
- 通过 DNS 解析域名获取该网站地址对应的 IP 地址,连同浏览器的 Cookie、 userAgent 等信息向此 IP 发出 GET 请求。
- 接下来就是经典的「三次握手」,HTTP 协议会话,浏览器客户端向 Web 服务器发送报文,进行通讯和数据传输。
- 进入网站的后端服务,如 Tomcat、Apache 等,还有近几年流行的 Node.js 服务器,这些服务器上部署着应用代码,语言有很多,如 Java、 PHP、 C++、 C# 和 Javascript 等。
- 服务器根据 URL 执行相应的后端应用逻辑,期间会使用到「服务器缓存」或「数据库」。
- 服务器处理请求并返回响应报文,如果浏览器访问过该页面,缓存上有对应资源,与服务器最后修改记录对比,一致则返回 304,否则返回 200 和对应的内容。
- 浏览器接收到返回信息并开始下载该 HTML文件(无缓存、200返回码)或从本地缓存提取文件(有缓存、304返回码)
- 浏览器的渲染引擎在拿到 HTML 文件后,便开始解析构建 DOM 树,并根据 HTML 中的标记请求下载指定的 MIME 类型文件(如 CSS、 JavaScript 脚本等),同时使用&设置缓存等内容。
- 渲染引擎根据 CSS 样式规则将 DOM 树扩充为渲染树,然后进行重排、重绘。 如果含有 JS 文件将会执行,进行 Dom 操作、缓存读存、事件绑定等操作。最终页面将被展示在浏览器上。 此答案精简的概括了「后端为主的 MVC 模式」及早期 Web 应用的浏览器响应的全过程。前端技术发展到现在,「前后端分离」「中间件直出」和「MNV*模式」也已问世,再谈及此问题,答案会有所不同。
就以「前后端分离」为例,在上方答案的第4步后,紧接着就不会直接进入后端服务器了。而会被 HTTP 和反向代理服务器,如 Ngnix,拦截。
- 前置步骤1、2、3、4
- Ngnix 在监听到 HTTP(80端口)或 HTTPS(443端口)请求,根据 URL 做服务分发,分发(rewrite)到后端服务器或静态资源服务器,首页请求基本是分发到静态服务器,返回一个 HTML 文件
- 步骤7、8、9、10
- 执行 JS 脚本,异步 ajax、 fetch 发起 POST、 GET 请求,重新进入 Ngnix 分发,此次分发到后端服务器,步骤5、6、7,然后返回一个 xml 或 json 格式的信息,一般含有 code(返回码)和 result(依赖信息) js 回调根据返回码执行不同的逻辑,增删改页面元素,此时可能会发生重排或重绘。首页加载结束。 从以上步骤可以发现,浏览器可能会触发两次重绘,极易产生「白屏」或「页面抖动」现象,为了解决这个问题「中间件直出」的模式应运而生。另外为了扩充大前端的阵营,吸纳 IOS 和 Android,Google 设计了「MNV*模式」,典型代表就是 ReactNative,但此模式已经脱离了浏览器的范畴,此处就不再做扩展。
以上讨论的渲染过程中使用到了较多的浏览器功能,如用户地址栏输入框、网络请求、浏览器文档解析、渲染引擎渲染网页、 JavaScript 引擎执行 js 脚本、客户端存储等。 接下来我们介绍下浏览器的基本结构组成
HTTP/2 和 HTTP/1.1优势和注意事项
HTTP/2 和 HTTP/1.1 的使用没什么区别,仍然可以在 body 中使用类 xml 的语法,使用 header 协议头字段, 状态码, cookies, methods, URLs, 等等。开发者熟悉使用的东西都还可以继续在 HTTP/2 使用。
HTTP/2的优势如下:
多路复用传输(Multiplexing):允许浏览器在单个TCP连接中包含多个请求,从而使浏览器能够并行地请求所有的资源;
服务器推送(Server push):服务器可以在浏览器知道需要该资源前,推送给浏览器(如:CSS、JS、Image),从而通过减少请求数量来加速页面加载时间;
流传输优先级(Stream priority):允许浏览器去控制资源的加载优先级,例如,浏览器先请求 HTML 渲染再去加载其他的 CSS 和 JS 文件;
头部压缩(Header compression): HTTP/1.1 请求的头部总是重复一样的内容,而 HTTP/2 则强制对所有请求的头部进行了去重压缩;
实际的强制加密(De facto mandatory encryption):虽然加密不是硬性要求的,但是大多数浏览器只支持 TLS(HTTPS) 上的 HTTP/2。