[Low-Level Design] Built-in message broker for full-node events
Goal of this document
This low-level design intends to go deeper on the technical aspects of the project. If you want more abstract information, please consult the high-level design
Full-node execution

At first, when the full node is initiated, it moves to the LOAD state, where data is load from the database, without consulting the network. Once all local data is read, the full-node continuously sync with peers, changing to SYNC state.
In order to know which events will be triggered, we will store the states (LOAD and SYNC) as metadata. So, when the full node starts, we will check the metadata. If it is empty or LOAD, we do not know where it stopped and will emit all events. If it is SYNC, we will skip all event triggered during full node initialization until LOAD_FINISHED
Flags
The following flags will be provided:
| Flag | Description |
|---|---|
| --enable-event-queue | Enable the message broker mechanism |
| --retain-events | Indicates that event should not be removed after being queried by the client |
Event
Definition
An event is a data structure that captures a specific, atomic moment inside the node that might be useful for applications.
Basic Structure
Event
{
id: uint64, // Event order
full_node_uid: string, // Full node UID, because different full nodes can have different sequences of events
timestamp: int, // Timestamp in which the event was emitted. This will follow the unix_timestamp format
type: enum, // One of the event types
group_id: uint64, // Used to link events. For example, many TX_METADATA_CHANGED will have the same group_id when they belong to the same reorg process
data: {}, // Variable for event type. Check Event Types section below
}
Metadata
{
last_state: string // LOAD or SYNC
}
Data Structures
tx_input: {
value: int,
token_data: int,
script: string,
index: int,
tx_id: bytes,
}
tx_output: {
value: int,
script: bytes,
token_data: int
}
token: {
uid: string,
name: string,
symbol: string
}
tx: {
hash: string,
nonce: int,
timestamp: long,
version: int,
weight: float,
inputs: tx_input[],
outputs: tx_output[],
parents: string[],
tokens: token[],
token_name: string,
token_symbol: string,
metadata: tx_metadata
}
spent_outputs: {
spent_output: spent_output[]
}
spent_output: {
index: int,
tx_ids: string[]
}
tx_metadata: {
hash: string,
spent_outputs: spent_outputs[],
conflict_with: string[]
voided_by: string[]
received_by: int[]
children: string[]
twins: string[]
accumulated_weight: float
score: float
first_block: string or null
height: int
validation: string
}
tx_metadata_changed: {
old_value: tx_metadata,
new_value: tx_metadata
}
reorg: {
reorg_size: int,
previous_best_block: string, //hash of the block
new_best_block: string //hash of the block
}
Types
- LOAD_STARTED
- LOAD_FINISHED
- NEW_TX_ACCEPTED
- NEW_TX_VOIDED
- NEW_BEST_BLOCK_FOUND
- NEW_ORPHAN_BLOCK_FOUND
- REORG_STARTED
- REORG_FINISHED
- TX_METADATA_CHANGED
- BLOCK_METADATA_CHANGED
For a description of each event type, consult the Event Types section on the the high level design
Event capture
This is a diagram of the consensus algorithm, highlighting where each event will be triggered. ATTENTION: This is not a FULL diagram of the algorithm, but only with parts that are relevant to this design.
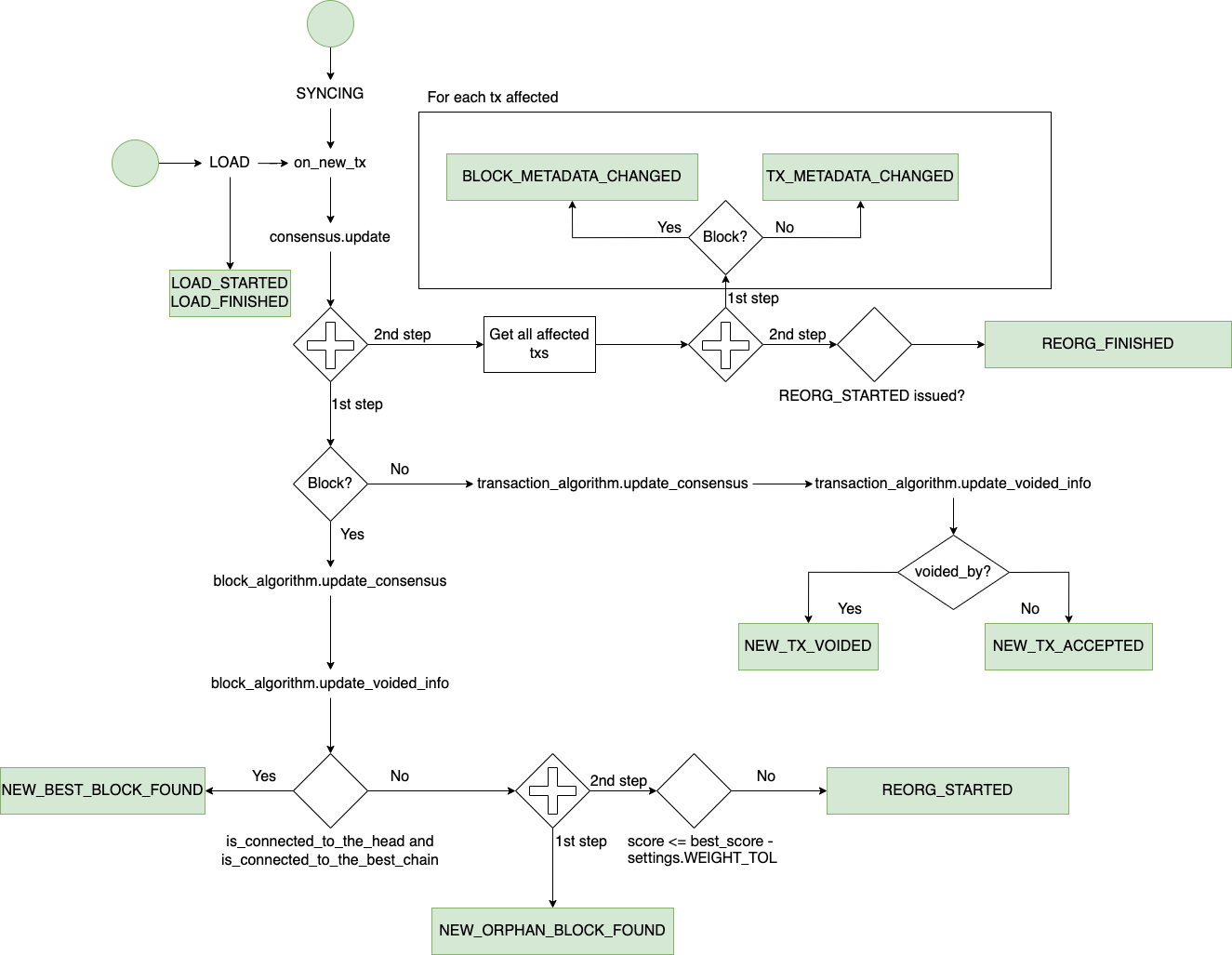
Storage
Engine
RocksDB will be used to store the captured events. Along with the fact that we will not add a new dependency, it is a great engine to navigate through a key range. A seek takes O(log(n)), and each subsequent key is retrieved in O(1).
Serialization
A new column-family will be created to store the events, so it stays decoupled from tx information.
Each event will be a dict on Python. To save the event, the whole dictobject will be translated to a string using json.dumps. Then, it will be inserted on the database. The key will be the event id, which takes 8 bytes. All information will be stored using big-endian format.
Deserialization
Each retrieved event from the database will be deserialized using event.decode('utf-8') and then json.loads will be used to transform it in a dict again.
Memory Storage
For txs, memory storage is available, especially for test purposes. We will also give this option for events. The storage will be simply a Dict, where the key will be the event_id represented in bytes, and the value will be the whole object. Then, we will provide methods to save and retrieve events, implementing the same interface used by Events RocksDB storage.
To decide which kind of storage to use, we will follow the same mechanism currently implemented (Evaluating the usage of --memory-storage flag).
REST API
This endpoint will be provided:
GET /event?last_received=:last_received&size=:size
Parameters:
last_received- The last event_id received in the previous request. If not provided, first entry will be retrieved.size- Number of events that the client wants to receive in the same response. Default is 10. Limit is 100.
Response:
The response will be an array with event objects. This is an example:
[
{
"id": 1,
"full_node_uid": "ecb8edcce0a34cb791923188cb3f18fd",
"timestamp": 1658868080,
"type": 2,
"group_id": 1,
"data": {
...
}
]
Error:
- If
last_receivedis an event that does not exist (Example: Last event_id on database is 1000, but client pass 2000 aslast_received, the API will return404 - Not Found. - If client pass a
size<= 1 or > 100, the API will return400 - Bad Request, informing that size is out of range.
WebSocket communication
Messages will have an event_id, but they can be delivered through the network in a different order. It is the client's responsibility to handle the cases where a newer event is received before a old one. Also, it is the client's responsibility to store the last event received. In case a connection dies, the new connection will not know where it stopped.
Message types
| Message | Direction | Description | Request | Response |
|---|---|---|---|---|
| start_streaming_events | Client -> WebSocket | Tell WebSocket to stream events from a determined event_id. | event_id - If not provided, get the first item on the database. | SUCCESS/FAIL |
| stop_streaming_events | Client -> WebSocket | Tell WebSocket to stop the event streaming | BLANK | SUCCESS/FAIL and Last event_id sent |
| get_event | Client -> WebSocket | Get an specific event from the full-node, without streaming the subsequent events | event_id - mandatory | event or error if event_id was not provided |
| event | WebSocket -> Client | Send a event from the WebSocket to the client | event | SUCCESS/FAIL |
Communication example
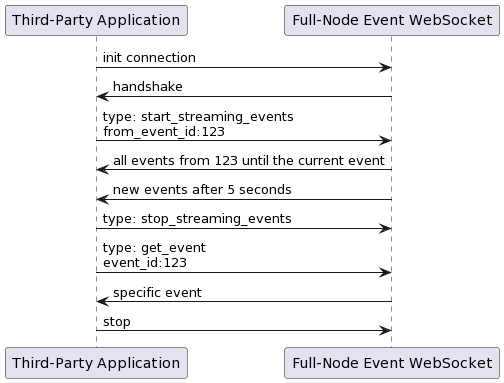
Testing Scenarios
For testing purposes, we will provide a separate Python application that will simulate a sequence of events. The user will be able to start this application via command line, passing one of the three initially available scenarios: SINGLE_CHAIN, BEST_CHAIN_WITH_SIDE_CHAINS, or MULTIPLE_FORKS.
Example: ./events_simulator.py --scenario SINGLE_CHAIN
A websocket server will be started and will wait connections from clients (following the same structure of the original websocket). Once requested (passing the start_streaming_events message), the events will be sent to the client. This way, the user do not need to run a full node to test the application.
A detailed document to instruct users on how to run the tests will be built as part of this task.
Final Task Breakdown
No changes from the task breakdown of the high level design.
Hi @lucas3003 . Thanks for the low-level design. Here are my thoughts and questions:
By default, events on this scenario will be captured unless the user provides the --skip-load-events flag.
-
Why would we emit these events? Haven't they been emitted before? I feel the most natural behavior would be to just skip them unless the user requests (and I'm not sure in which case it would be useful. Any suggestions?)
-
What happens if the user does not enable RocksDB Storage? Would you create your own RocksDB? Would you have a memory storage for events? Or would you disable the event system? We usually use the memory storage for testing purposes.
-
Rest API: What is the response format?
-
Testing Scenarios: A suggestion would be to create some testing databases with marks (e.g., a reorg occurs on event_id=4231). So developers can run their full nodes using these databases to run integration tests. I haven't given much thought for this suggestion. Feel free to skip it :)
Note: Nice diagram for the consensus algorithm.
Thanks for the comments @msbrogli. Here are the answers:
Why would we emit these events? Haven't they been emitted before? I feel the most natural behavior would be to just skip them unless the user requests (and I'm not sure in which case it would be useful. Any suggestions?)
I thought on a use case where the user downloads a snapshot to speed-up the initialization and want to maintain a database (Like Wallet Service) with all txs. Do you think this would be a feasible
What happens if the user does not enable RocksDB Storage? Would you create your own RocksDB? Would you have a memory storage for events? Or would you disable the event system? We usually use the memory storage for testing purposes.
Good point. I hadn’t thought about a memory storage. I included on the design because I think it makes sense for testing purposes.
Rest API: What is the response format?
Good point. I included the response format and an example.
Testing Scenarios: A suggestion would be to create some testing databases with marks (e.g., a reorg occurs on event_id=4231). So developers can run their full nodes using these databases to run integration tests. I haven't given much thought for this suggestion. Feel free to skip it :)
I liked the idea. Would it be kind of a big JSON with all events and a different structure indicating where reorg started, for example?
Why would we emit these events? Haven't they been emitted before? I feel the most natural behavior would be to just skip them unless the user requests (and I'm not sure in which case it would be useful. Any suggestions?)
I thought on a use case where the user downloads a snapshot to speed-up the initialization and want to maintain a database (Like Wallet Service) with all txs. Do you think this would be a feasible
I also had the same impression that --skip-load-events may not be a good flag. I was going to suggest reversing it to --emit-load-events, but maybe there's a better alternative. If there is a way to know which events have already been emitted, this could be used instead of a flag to decide whether to skip/not skip emitting loading events, a snapshot would not have the record of any events being emitted (and we will have to make sure of that when creating snapshots) so when the node starts it will see that no events have ever been emitted and would start emitting them from the start.
Does this make sense?
In the end I think the less choices the user has to make the better. In the case of the flag proposed, it looks like the user might not want to skip load events on the first run, but would want to skip load events on later runs, I'm not sure what errors this could lead if any to but it seems like something very easy to do by mistake.
What happens if the user does not enable RocksDB Storage? Would you create your own RocksDB? Would you have a memory storage for events? Or would you disable the event system? We usually use the memory storage for testing purposes.
Good point. I hadn’t thought about a memory storage. I included on the design because I think it makes sense for testing purposes.
Maybe it would make sense to require a RocksDB storage for using the event queue.
Other than that this design looks good to me.
a snapshot would not have the record of any events being emitted (and we will have to make sure of that when creating snapshots)
Is this possible to do? If so, how?
Maybe this should be considered in the design as well. Currently to create snapshots we simply zip the whole data folder.
I think this issue also connects with https://github.com/HathorNetwork/ops-tools/issues/426, where we want to monitor the storage size of the blockchain. If we will store events in RocksDB, they would need to be ignored in this monitoring. But it seems this doesn't affect decisions here, only in the other issue.
I also had the same impression that --skip-load-events may not be a good flag. I was going to suggest reversing it to --emit-load-events, but maybe there's a better alternative. If there is a way to know which events have already been emitted, this could be used instead of a flag to decide whether to skip/not skip emitting loading events, a snapshot would not have the record of any events being emitted (and we will have to make sure of that when creating snapshots) so when the node starts it will see that no events have ever been emitted and would start emitting them from the start.
It does make sense! We will emit LOAD_STARTED and LOAD_FINISHED events. We can check if these events were triggered and then skip events during LOAD phase. What do you think?
Maybe it would make sense to require a RocksDB storage for using the event queue.
I think it is easy to also implement an in-memory storage (Simply a Dict of events). But I do not know how widely used this would be.
Is this possible to do? If so, how?
Maybe this should be considered in the design as well. Currently to create snapshots we simply zip the whole data folder.
We can achieve that by not using the --enable-event-queue flag on the nodes we use to generate the snapshot.
I also had the same impression that --skip-load-events may not be a good flag. I was going to suggest reversing it to --emit-load-events, but maybe there's a better alternative. If there is a way to know which events have already been emitted, this could be used instead of a flag to decide whether to skip/not skip emitting loading events, a snapshot would not have the record of any events being emitted (and we will have to make sure of that when creating snapshots) so when the node starts it will see that no events have ever been emitted and would start emitting them from the start.
It does make sense! We will emit
LOAD_STARTEDandLOAD_FINISHEDevents. We can check if these events were triggered and then skip events during LOAD phase. What do you think?
I think that makes sense, finding these specific events seems relevant, so we don't have to make a O(n) scan for example. I think that a consideration for that should be included in the design.
Maybe it would make sense to require a RocksDB storage for using the event queue.
I think it is easy to also implement an in-memory storage (Simply a Dict of events). But I do not know how widely used this would be.
That's fine, but my concern was more about the consistency of behavior when using events stored in RocksDB, vs events stored in Memory, specifically in regards to skipping the events when loading. If were to be possible for a RocksDB storage to be used with Memory stored events, there would be a strange behavior where we never know the load events were emitted. I think this is covered by this design when we choose the storage engine based on the same flag that we use to choose the transactions storage.
I think this issue also connects with HathorNetwork/ops-tools#426, where we want to monitor the storage size of the blockchain. If we will store events in RocksDB, they would need to be ignored in this monitoring. But it seems this doesn't affect decisions here, only in the other issue.
I think this falls on the same case as the indexes. Since indexes aren't technically part of the blockchain. But I think the point of the ops-tools design is a little more broad to know how the node is using the storage, so measuring the storage of events would just have its own classification, like indexes would be measured separately.
I think that makes sense, finding these specific events seems relevant, so we don't have to make a O(n) scan for example. I think that a consideration for that should be included in the design.
It is actually O(n) because we store the event_id as key. To overcome this problem, I added a new column family, called metadata, where we will store LOAD if the node is loading the local database or SYNC if LOAD state has passed and the node is receiving and sending data through the network. Then, we will use O(1) to get the information.