httparchive.org
 httparchive.org copied to clipboard
httparchive.org copied to clipboard
Desktop Summary Requests incomplete
February 2019 Summary Requests table is 272M lines, and 240GB
March 2019 Summary Requests table is 5M lines, 5GB
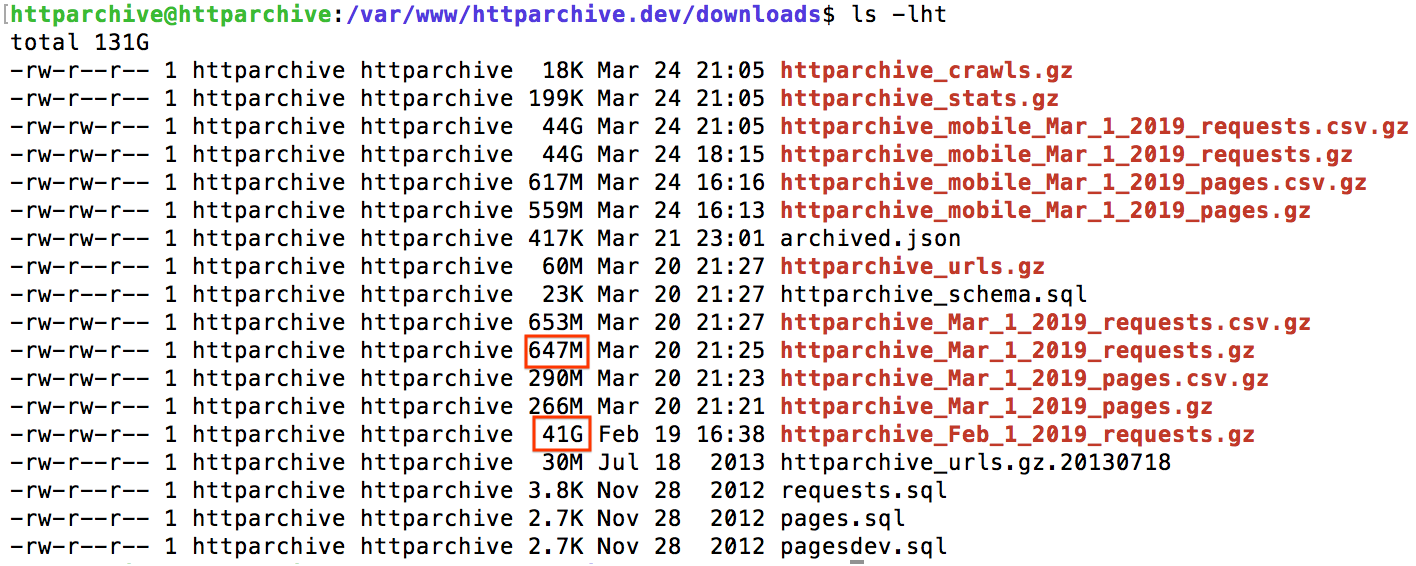
It appears a large amount of data is missing in the March data. The raw data files at https://legacy.httparchive.org/downloads.php are also different in size.
Confirmed that the downloads are serving a file way too small
Next step is to try to rerun the mysqldump
https://github.com/HTTPArchive/legacy.httparchive.org/blob/9ef583089600d05093c4992a0c92e77f00c26ae8/bulktest/update.php#L214
The local mysql tables seem to have been cleared out with the exception of the requests table:
mysql> select count(0) from requests;
+----------+
| count(0) |
+----------+
| 5119678 |
+----------+
1 row in set (0.00 sec)
mysql> select count(0) from requestsdev;
+----------+
| count(0) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)
mysql> select count(0) from requestsmobile;
+----------+
| count(0) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)
mysql> select count(0) from requestsmobiledev;
+----------+
| count(0) |
+----------+
| 0 |
+----------+
1 row in set (0.01 sec)
The requests that are in that table are only from tests on March 1:
mysql> select min(startedDateTime), max(startedDateTime) from requests;
+----------------------+----------------------+
| min(startedDateTime) | max(startedDateTime) |
+----------------------+----------------------+
| 1551418211 | 1551432347 |
+----------------------+----------------------+
1 row in set (0.00 sec)
So this is why the mysqldump of the requests table is only yielding 647 MB of data.
Not sure what happened to the requests table to cut it short and why only desktop was affected. Also not sure if we have any other backups available. The good news is that we do have the HAR files for all of these requests so it's not a total loss of data, but we would still need to convert the HAR data to the schema in the CSV-based summary tables. This is doable but would require some time. This task is also something that's been on our todo list as part of the mysql deprecation. See https://github.com/HTTPArchive/httparchive.org/issues/23
I'm still mildly concerned that this is a problem that might happen again, so it's best to keep an eye on the April crawl, especially around the 15th of the month when @pmeenan noticed a suspicious drop in disk space.
FWIW, the requests tables get dropped after the mysqldump completes so it's not unusual for them to be empty after the crawl but it looks like something triggered it mid-crawl for the desktop data :(
Yeah it seems something nuked the table before we could do our backups. That said, I'm curious how we ended up with a partial requests table if it's supposed to be dropped after each mysqldump.
Here's how it should work. There's a cron job to run batch_process.php every 30 minutes. batch_process will kick off the mysqldump when the crawl is complete:
https://github.com/HTTPArchive/legacy.httparchive.org/blob/7a5710dc83dd4ca7bb204573fd3fa58c5ea2c1f0/bulktest/batch_process.php#L41-L82
https://github.com/HTTPArchive/legacy.httparchive.org/blob/7a5710dc83dd4ca7bb204573fd3fa58c5ea2c1f0/bulktest/copy.php#L96-L100
https://github.com/HTTPArchive/legacy.httparchive.org/blob/6d1a872a3270360a14eb018871544a0c9c8adf28/crawls.inc#L285-L332
Paul and I made lots of progress on this. Here's a table with the summary_requests schema generated from the HARs: https://bigquery.cloud.google.com/table/httparchive:scratchspace.requests_2019_04_01_desktop?tab=preview
Would appreciate another set of eyes to make sure the results look good.
Here's the query that powers it:
https://gist.github.com/rviscomi/52494fdcfa561c88cfb1c4255ce3939d
Noticed today that the summary_pages tables are off as well. Metrics like the total font size are calculated based on the underlying requests, so in the absence of those the summary page data becomes 0.
We'll need to write a query that aggregates requests for each page and computes the summary stats.
November_1_2019 desktop summary requests table is also missing ~90% of the requests.
Number of total requests in...
- Sep 2019:
410,426,130 - Oct 2019:
407,445,152 - Nov 2019:
44,531,993
(as found by SELECT count (0) FROM httparchive:summary_requests.2019_11_01_desktop)
The gzipped archives in the buckets also look incomplete: https://console.cloud.google.com/storage/browser/httparchive/Nov_1_2019/?pli=1
Thanks for looking into this.
I think the November 2019 desktop requests CSV got corrupted somehow. I'm unable to regenerate the table without it failing to import into BQ. Leaving this issue open as a reminder to either resolve the CSV issue or generate the table via HAR data.