HRNet-Facial-Landmark-Detection
 HRNet-Facial-Landmark-Detection copied to clipboard
HRNet-Facial-Landmark-Detection copied to clipboard
post-processing
Dear author, how can I understand the post-processing part in the decode_preds function?
# pose-processing
for n in range(coords.size(0)):
for p in range(coords.size(1)):
hm = output[n][p]
px = int(math.floor(coords[n][p][0]))
py = int(math.floor(coords[n][p][1]))
if (px > 1) and (px < res[0]) and (py > 1) and (py < res[1]):
diff = torch.Tensor([hm[py - 1][px] - hm[py - 1][px - 2], hm[py][px - 1]-hm[py - 2][px - 1]])
coords[n][p] += diff.sign() * .25
coords += 0.5
preds = coords.clone()
It is a common practice to compensate for the quantization effect. Since the landmark is encoded in a heatmap of lower resolution (generally 1/4th) than the original image, when recovering the coordinates after inference, a sub-pixel shift towards the next highest pixel value is used.
From Stacked Hourglass Networks for Human Pose Estimation, pg 8:
To improve performance at high precision thresholds the prediction is offset by a quarter of a pixel in the direction of its next highest neighbor before transforming back to the original coordinate space of the image.
Some details are also provided in Distribution-Aware Coordinate Representation for Human Pose Estimation in Coordinate Decoding section.
Hope this helps!
It is a common practice to compensate for the quantization effect. Since the landmark is encoded in a heatmap of lower resolution (generally 1/4th) than the original image, when recovering the coordinates after inference, a sub-pixel shift towards the next highest pixel value is used.
From Stacked Hourglass Networks for Human Pose Estimation, pg 8:
To improve performance at high precision thresholds the prediction is offset by a quarter of a pixel in the direction of its next highest neighbor before transforming back to the original coordinate space of the image.
Some details are also provided in Distribution-Aware Coordinate Representation for Human Pose Estimation in Coordinate Decoding section.
Hope this helps!
Thanks a lot
It is a common practice to compensate for the quantization effect. Since the landmark is encoded in a heatmap of lower resolution (generally 1/4th) than the original image, when recovering the coordinates after inference, a sub-pixel shift towards the next highest pixel value is used.
From Stacked Hourglass Networks for Human Pose Estimation, pg 8:
To improve performance at high precision thresholds the prediction is offset by a quarter of a pixel in the direction of its next highest neighbor before transforming back to the original coordinate space of the image.
Some details are also provided in Distribution-Aware Coordinate Representation for Human Pose Estimation in Coordinate Decoding section.
Hope this helps!
Hi,thanks for the reference. Why do we need to shift 0.5 pixel in here ?
Hi,thanks for the reference. Why do we need to shift 0.5 pixel in here ?
@MengHao666 The 1/4 offset is made from the center of the heatmap pixel. The center of the heatmap pixel with coordinates (x,y) is 0.5+(x,y).
See the image below with green point being the final pred with sub-pixel shift. [I made a slight misrepresentation, the sub-pixel shift should be- (x' +/- 0.25, y' +/- 0.25)] as it can be in any direction]
Someone can maybe confirm this just to be sure.
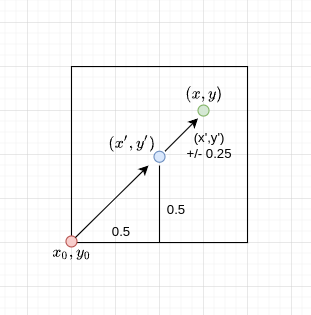
any directio
In my own understanding, the +0.5 is for the interpolation to decrease the final scaled error. The 1/4 offeset is considering the heatmap , but do you thnk the +0.5 and 0.25 are dpendent on experience, that is something hyper-parameters?
any directio
@kuldeepbrd1 In my own understanding, the +0.5 is for the interpolation to decrease the final scaled error. The 1/4 offeset is considering the heatmap , but do you thnk the +0.5 and 0.25 are dpendent on experience, that is something hyper-parameters?
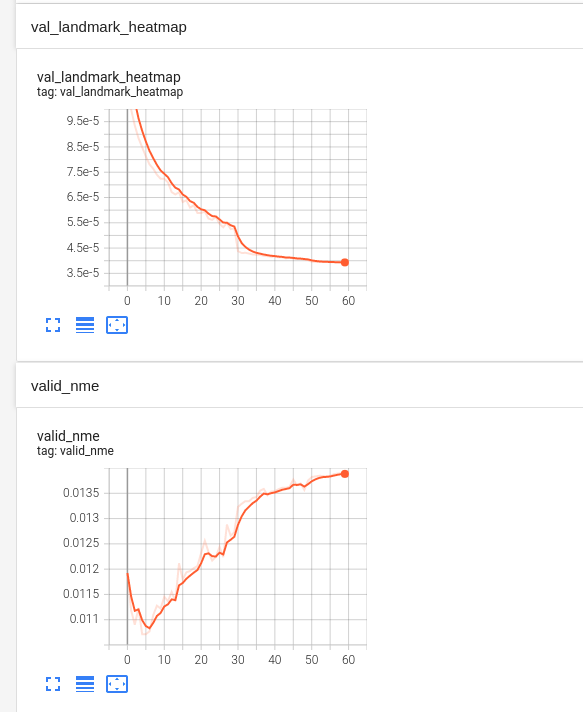
Training on my own dataset, I have a very interesting result here with the same so-called post-processing . In the evaluation process, the `NME' first drop and then increase at the very begining 5th epoch. However, the landmark heatmap loss always decrease. I couldn't figure it out. Why? Anyone have any idea?