Mashiro
![]()
Mashiro
> @HAOCHENYE Thank you for your reply. So need i reinstall mmengine by the source? > > ``` > # 1. clone source code > git clone --depth 1 https://github.com/open-mmlab/mmengine.git...
> No acctually. 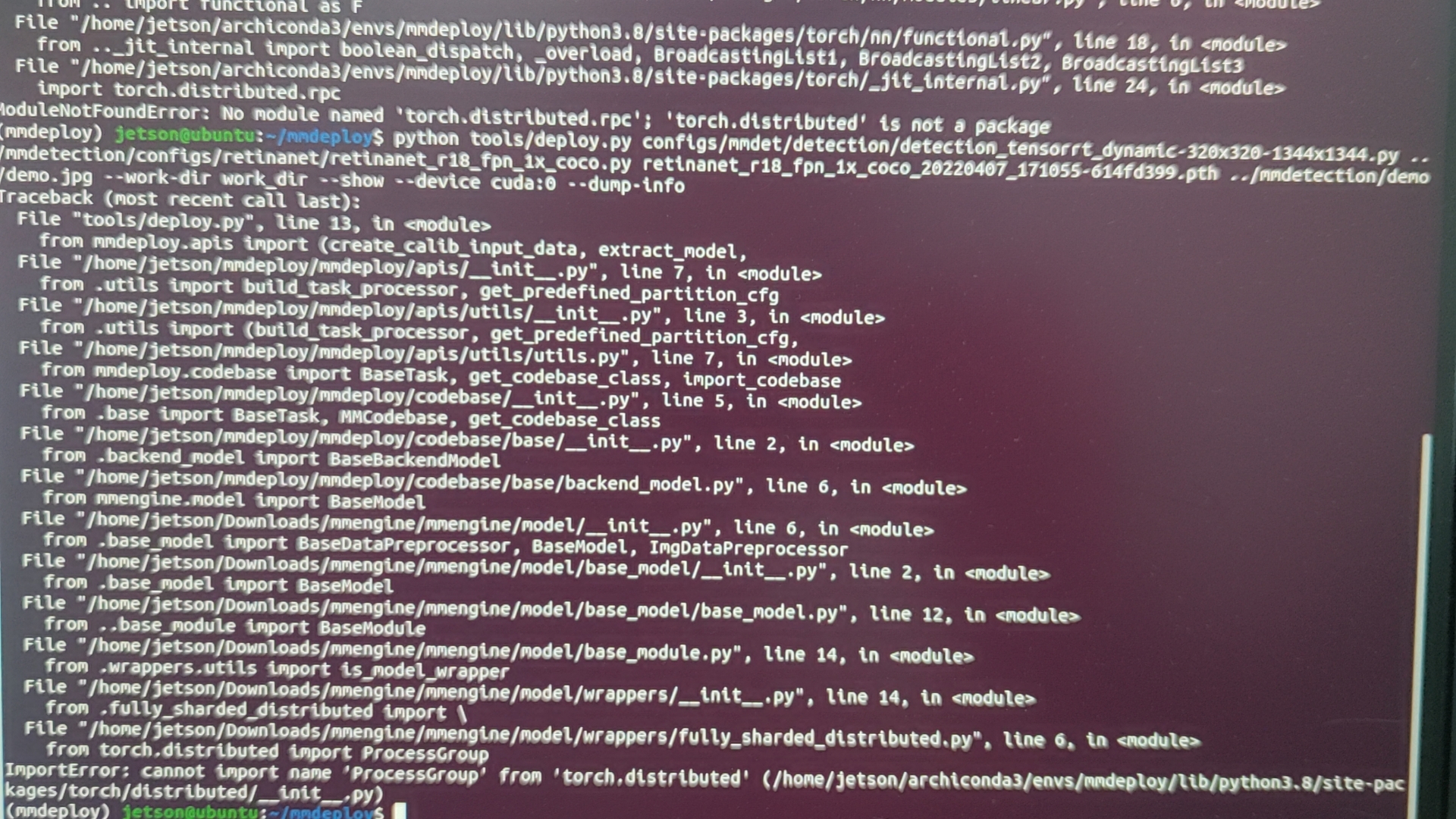 > > Do you have the other method? Have you put this code at the top of the `deploy.py` (after import `sys` and `unittest`, before any...
you need to put it before `from mmdeploy.apis... `
> thank you for your reply. I had change the torch version to 2.0 ,and put the code you show, still had the problem 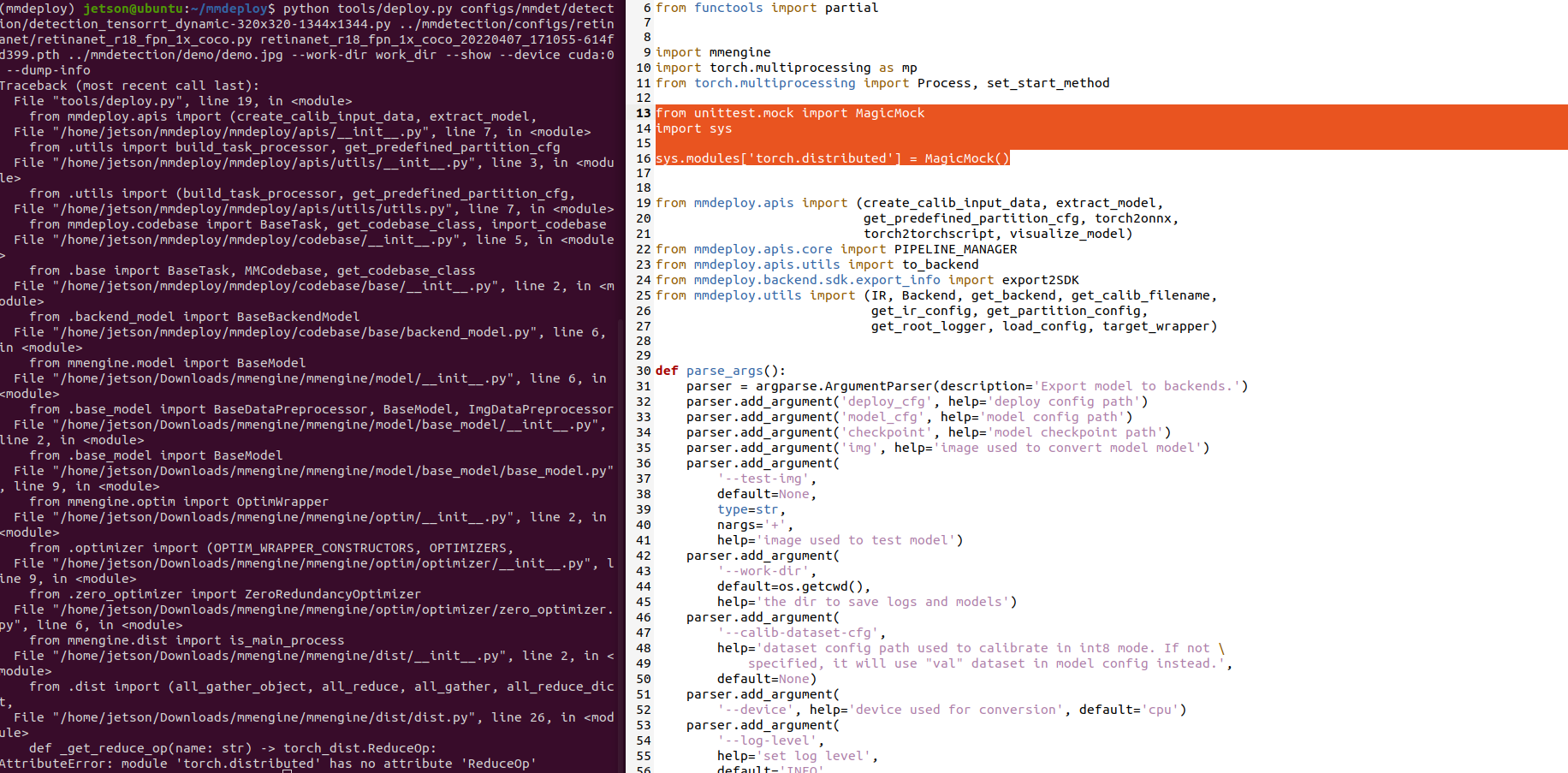 Emmm, this error is raised...
Please present the visualization results using both the cv2 and matplotlib backends to verify their correctness.
Approved!!! 
你可以尝试使用 `with autocast(enabled=False):` 在里面的代码临时关闭 autocast
非常感谢你的反馈,事实上我们也考虑过使用 `dict(type=XXX)` 的协议来自动 build 各个组件,这样就能免于在代码里通过 `build_from_cfg` 来显式地构建模块了。这样的想法确实很方便,但是在实际操作过程会遇到一些问题。以你提到的这种方式为例: **真的可以做到所有的模块,都遵循这种写法,通过在 `__init__` 上加装饰器的方式来免于在 `__init__` 内部调用 build function 么** 这其实是很困难的,以大家都熟悉的 Dataloader 为例,Dataloader 需要接受 dataset 参数,sampler 也需要接受 dataset 参数,batch_sampler 需要 sampler 参数。对于这类构造参数互相耦合的情况,通过装饰器来自动化构建实例的方式就很难走通了,我们可能需要引入更多的概念,例如占位符。但是过于复杂语法涉及实际上是违反了 Pthon Style Config...
Sorry for the late response. The reason for not calling add_scalars in [after_test_epoch](https://github.com/open-mmlab/mmengine/blob/f79111ecc0eea9fbb1b7d1361a79f7062ca1ac10/mmengine/hooks/logger_hook.py#L276) is that the test set typically does not have the ground truth, and we usually only calculate...
Visualizer is a globally accessible variable, and you can get the visualizer at any location using `visualizer = Visualizer.get_current_instance()` and then call the interface like `visualizer.add_scalar()` to record the information...