graphlet
 graphlet copied to clipboard
graphlet copied to clipboard
Create a generic, configurable system for entity resolution of heterogeneous networks using pre-trained LMs and GATs
Create a generic, configurable system for entity resolution of heterogeneous networks using pre-trained LMs and GATs
Graph Neural Networks (GNNs) accept arbitrary features as input... making an embedding produced by a model based on ditto a way to encode the properties of nodes in a heterogeneous network. Ditto designed this method for entity matching, which would seem to be analogous to link prediction in training a GNN. Ditto could therefore work as the first layer in a two-step entity resolution process: encode nodes using a pre-trained language model and then distribute node representations around a network to help an entity matching model consider the network neighborhood of each node in its matching.
To create a generic entity resolution system, we will:
- Automatically encode nodes as text documents including column and type hints from the ontology's Pandera classes.
- A pre-trained language model will create a fixed-length vector representation of the node text documents
- A Graph Attention Network (GAT) model will perform entity resolution as a binary classification problem, given two nodes' representations encoded via Ditto --> LM --> GNN, to predict
SAME_ASedges for the entire network at once rather than blocking and matching pairs of nodes. This avoids scaling blocking for large networks, which can be painful.
Encoding Node Features using Pre-Trained Language Models (LMs)
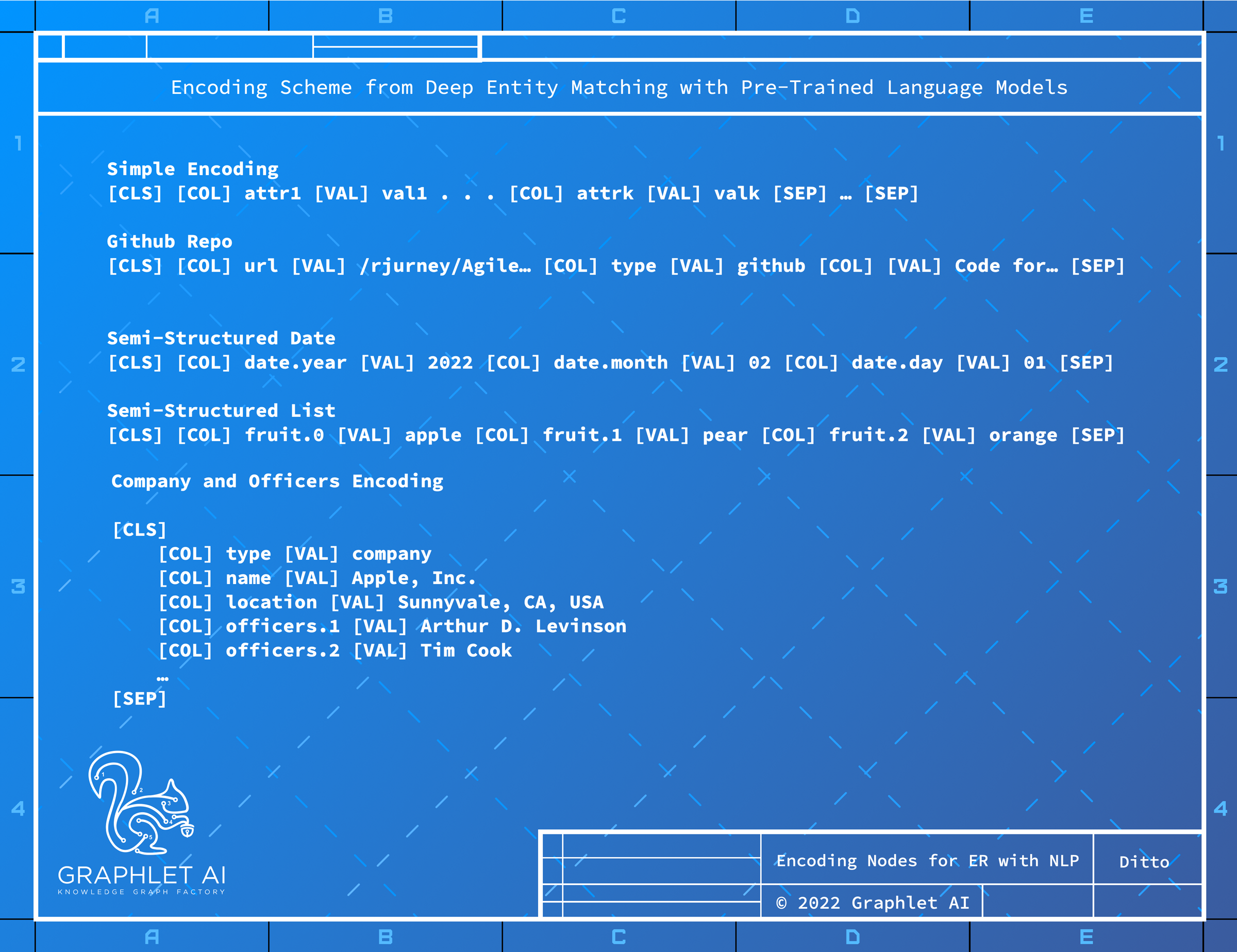
The landmark paper Deep Entity Matching with Pre-Trained Language Models outlines a way to encode records using pre-trained language models such as baby BERT models by providing clues about the column names as shown in the image below to help the model use what it learned from a huge amount of semi-structured data to encode any semi-structured record.
The code for this paper is available here: github.com/megagonlabs/ditto
We will use the Schema Model to generate a "Ditto format" text version of a node or edge as in ditto/ditto_light/summarize.py:
def transform(self, row, max_len=128):
"""Summarize one single example.
Only retain tokens of the highest tf-idf
Args:
row (str): a matching example of two data entries and a binary label, separated by tab
max_len (int, optional): the maximum sequence length to be summarized to
Returns:
str: the summarized example
"""
sentA, sentB, label = row.strip().split('\t')
res = ''
cnt = Counter()
for sent in [sentA, sentB]:
tokens = sent.split(' ')
for token in tokens:
if token not in ['COL', 'VAL'] and \
token not in stopwords:
if token in self.vocab:
cnt[token] += self.idf[self.vocab[token]]
For the full code, see https://github.com/megagonlabs/ditto/blob/master/ditto_light/summarize.py#L63-L84
Blocking for Pair-Wise Comparisons using LSH and Embeddings
