5ch-analysis
 5ch-analysis copied to clipboard
5ch-analysis copied to clipboard
5chの過去ログをスクレイピングして、過去流行った単語(ex, 香具師, orz)などを追跡調査
5ch(旧2ch)をスクレイピングして、過去流行ったネットスラングの今を知る
5ch(旧2ch)ではここ数年はTwitterを使用するようになってしまいましたが、ネットのミームの発信地点であって、様々なスラングを生み、様々な文化を作ってきたと思います。
学生時代、2chまとめとか見ていたので、影響を受けてきたネット文化で、感覚値からすると、どうにも流行り廃りがあるようです。
5chの過去ログを過去18年ほどさかのぼって取得する方法と、懐かしいネットスラングのドキュメントに占める出現具合を時系列でカウントすることで、時代の変遷でどのように使用の方法が変化したのか観測することができます。
文末に「orz」って付けたら若い人から「orzってなんですか?」と聞かれて心身共にorzみたいになってる
— ばんくし (@vaaaaanquish) October 19, 2018

5chの過去ログをスクレイピングするには
前々から5chのコーパスは欲しかったのですが、どこから、どうやって取得すればいいのかわからなかったのですが、なんとかPython3 + requests + BeautifulSoupの組み合わせで確立した方法があるのでご紹介します。
幅優探索による過去ログのスクレイピング
URL同士のリンクばネットワーク構造になります。
スクレイピングする際の戦略として、ネットワークをどうたどるか、という問題で、幅優先探索を行いました。
2chの過去ログから辿れるログは平面的に大量のリンクを2~3回たどれば目的のデータにアクセスできる構造で幅優先探索に適していたからという理由です。

起点となる一点を決める
かねてから2chの全ログ取得は夢でしたが、様々な方法を検討しましたが、ログが保存されているURLの一覧が存在しないということで諦めていたのですが、ついに発見するに至りました。
以下のURLからアクセスすることができ、多くのスレの過去ログサーバを参照しています。
そのためここからアクセスすることで2chの過去ログをスクレイピングすることができます。
http://lavender.5ch.net/kakolog_servers.html
レガシーなhtmlフォーマットに対応する
Pythonのhtmlパーサーを前提に話しますが、旧2chのHTMLは正しいHTMLというわけでないようです。
tableタグを多用するデザインが2017年度半ばまで主流だったようで、このときのタグに閉じるの対応なく、lxml, html.parserなどを使うと失敗します。
そのため、一部の壊れたhtmlでもパースできるようにhtml5libパーサーを利用してパースすることができます[1]
この問題は、BeautifulSoupのパーサを以下のようにhtml5libに設定すれば解決することができます。
soup = bs4.BeautifulSoup(html, 'html5lib')
並列アクセスを行う
2chの過去ログは、一つ一つのサーバに名前がついていて、各サーバが異なったサブドメインを持っています。
そのため、異なった実サーバをもっていると考えられるので、サーバごとにアクセスを並列化することで高速化することができます。加えて、もともとPythonのrequestsとBeautifulSoupを使ったhtml解析が重い作業なので、マルチコアリソースを最大限利用して、並列アクセスする意義があります。
集計するネットスラングの選定
一般的なネットスラングは時代の変遷の影響を受けるという感覚値がありました。
具体的には、その日における単語の頻度が人気があると高くなり、低くなると下がっていくという感覚値があり、時系列にしたとき、人気の発生から、使われなくなるまでが観測できるのではないかと思い、集計しました。
過去、20年間に存在してきた様々なネットスラングについて、様々なまとめ[2]があり、みているととても懐かしくなります。
記憶に強く残っていたり、違和感があったり、今でも使わているのだろうか?最近見ていないがどの程度減ったのか?、という視点で選んだ単語がこれらになります。
(下記に記したGitHubの集計コードを変更することによって、任意のキーワードで再集計することができます、よろしかったらやってみてください)
- orz
- 尊師
- 香具師
- 笑(文末)
- 初音ミク
- 結月ゆかり
- コードギアス
- hshs
- iphone
- うp
- 自宅警備員
- ワンチャン
- ステマ
- 情弱
- チラ裏
- 今北産業
- 禿同
- w(文末)
- メシウマ
- まどマギ
- ソシャゲ
- ジワる
- ナマポ
- (ry
- ggrks
- オワコン
この計算は、下記のGitHubのexamples/time_term_freq.pyで行うことができて、プログラムを変えることで集める単語を変更することができ、再集計することができます。
htmlをjsonl化する
スクレイピングしたhtmlをスレの内容を取り出し、jsonl(一行に一オブジェクトのjson)にしておくといろいろと集計が都合がよいです。
scan_items.pyというプログラムでパースできるので、参考にしてください。
$ python3 scan_items.py
結果
examples/time_term_freq.pyを実行することで得られます。





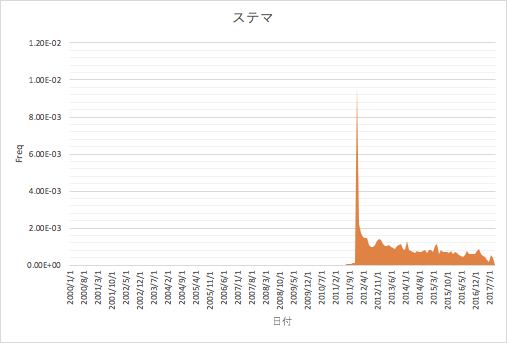










仮説どおり、ネットスラングは流行り廃りがあり、今は殆ど使われなくなったものがどの時期から消えていったのか視覚化されました。
また、文末にwをつけるなどの草を生やす表現は今も強くなりつづけており、しばらく使っても老害扱いされないでしょう(安心)。
感覚値と実際にデータで表されるネットスラング表現の隔たりが明らかにされ、発祥や時代感が不明確であったりしたものが整理され、発見的な集計となりました。
コード
[https://github.com/GINK03/5ch-analysis]