Csv retrieval
Closes #ISSUE_NUMBER
I have:
- [x] Formatted any Python files with black
- [ ] Brought the branch up to date with master
- [x] Added any relevant Github labels
- [x] Added tests for any new additions
- [x] Added or updated any relevant documentation
- [ ] Added an Architectural Decision Record (ADR), if appropriate
- [ ] Added an MPLv2 License Header if appropriate
- [ ] Updated the Changelog
Description
Implements the initial draft of the long-term storage -> flowdb pipeline (pictured, ignore the colours)
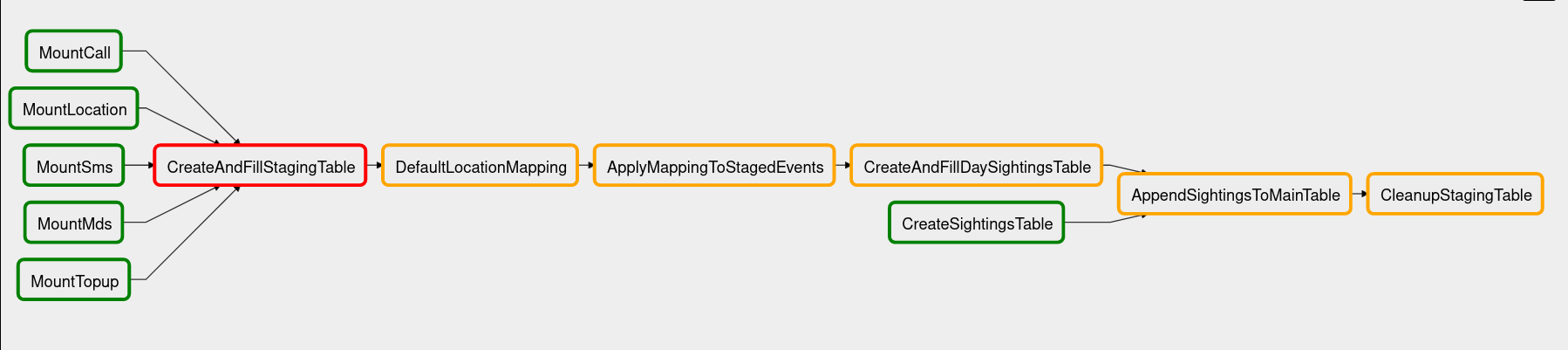 This adds the above facilities to create the above DAG to flowetl. The DAG is designed to be run on daily data, and the operators are as follows:
This adds the above facilities to create the above DAG to flowetl. The DAG is designed to be run on daily data, and the operators are as follows:
Mount{x]; Mounts that CSV as a foreign data wrapperCreateAndFillStagingTable; Creates a table containing data common to all events and populates it from the foreign data wrappersDefaultLocationMapping; Creates a table that maps cell tower IDs to themselves. May be replaced in the future by more sophisticated mappings.ApplyMappingToStagedEvents; Replaces the cell IDs in the staged events table with their counterparts from the location mapping table.CreateSightingsTable; Creates the reduced.sightings table (as designed by James) if it does not exist, to be filled by partitions.CreateAndFillDaySightingsTable; Reworks the data in the staging table into the sightings formatAppendSightingsToMainTable; Attaches the daily table to the reduced.sightings table as a partitionCleanupStagingTable; Drops the staging table fromCreateAndFillStagingTableand the foreign data wrappers fromMount[x]
It is built with the following assumptions (all env vars are in the flowetl container):
- That a set of CSVs of the naming format [yyyymmdd]_[event_type] are accessible to the flowdb container local filesystem
- That the CSVs have headings as set out in flowetl/flowetl/flowetl/operators/staging/event_columns.py
- That the path to these is set in the environment variable
FLOWDB_CSV_DIR - That the date to start running the DAG is set in
FLOWETL_CSV_START_DATE, in the format yyyy-mm-dd - That the events to be staged are in
FLOWETL_EVENT_TYPES, as a comma-seperated list.
What has been added
- A new subset of operators,
flowetl.operators.stagingthat are relevent to building this DAG. These are mainly wrappers around a set of Jinja-templated queries found inflowetl.operators.staging.sql, with the following exceptions: -mount_event_operator_factorycontains a function for creating the Mount operators - not every MNO will provide all of them. -create_and_fill_staging_tablecreates a Jinja template for mounting a set of event types. utils.create_staging_dag; a function that takes a start date and a list of event types, and returns a DAG defining the pipeline for that set of event types.- Unit tests (
test_staging_operators.py) and fixtures (added tounit/conftest.py). These are built on the postgresql_db fixture for building temporary databases, and a dummy one-task DAG. - An integration test of the new DAG, using a similar framework to existing DAG integration tests.
- Static correctly formatted CSVs for testing
What has changed
- Workaround for the missing postgres public key in the flowetl Dockerfile
- pytest-psql added to dev requirements
Open questions
- How should this DAG be triggered? Daily, on CSV creation, or by the other half of flowetl?
- The location mapping step has some holes; there's no facility to update the entire reduced table if the cell tower mapping is changed, and it might just be not needed
- How should we handle missing or empty CSVs? I'm leaning towards passing this problem off to the monitoring system.
Still to do
- Add the opt-out step
(there's a load of files from the benchmarking branch that have ended up in here, I'll sort them out tomorrow and get rid of this line)
![]()
Test summary
![]() 43 •
43 • ![]() 0 •
0 • ![]() 0 •
0 • ![]() 0 •
0 • ![]() 0
0
Run details
| Project | FlowAuth |
| Status | Passed |
| Commit | 17e8a5fc1c |
| Started | Apr 27, 2022 1:17 PM |
| Ended | Apr 27, 2022 1:24 PM |
| Duration | 07:47 💡 |
| OS | Linux Debian - 10.5 |
| Browser | Electron 94 |
View run in Cypress Dashboard ➡️
This comment has been generated by cypress-bot as a result of this project's GitHub integration settings. You can manage this integration in this project's settings in the Cypress Dashboard
Re @jc-harrison 's comments about splitting the DAG - would this eventually lead to three DAGs? CSV -> 'staging' (always used, can be run with subset of events) 'staging' -> 'sighting' (used for 'lite' queries, that don't need event-specific information, always happens) 'staging' -> 'full' (used for event-specific queries, only happens if that analysis is needed)
Re @jc-harrison 's comments about splitting the DAG - would this eventually lead to three DAGs? CSV -> 'staging' (always used, can be run with subset of events) 'staging' -> 'sighting' (used for 'lite' queries, that don't need event-specific information, always happens) 'staging' -> 'full' (used for event-specific queries, only happens if that analysis is needed)
I'm imagining two DAGS: CSV -> 'full' and 'full' -> 'sightings' (i.e. the 'full' events tables are always populated first, and the 'sightings' table is derived from the 'full' tables instead of from a staging table).
Done: Broken the CSV DAG into two Added 'analyse' tasks to the end of both DAGs Moved sightings table schema into flowdb Rewrote sighting table schema to add a constraint post-CREATE Changed schemas and test data to merge the 'caller' and 'callee' event types, and added a bool column to the CSV for is_incoming Still to do: A constraint to the dimension table in flowdb A staging sensor for the DAG DAG tests