error When running SAM
When running SAM on any dataset I get the following error :
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [200, 1]], which is output 0 of TBackward, is at version 3; expected version 2 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck! A clear and concise description of what the bug is.
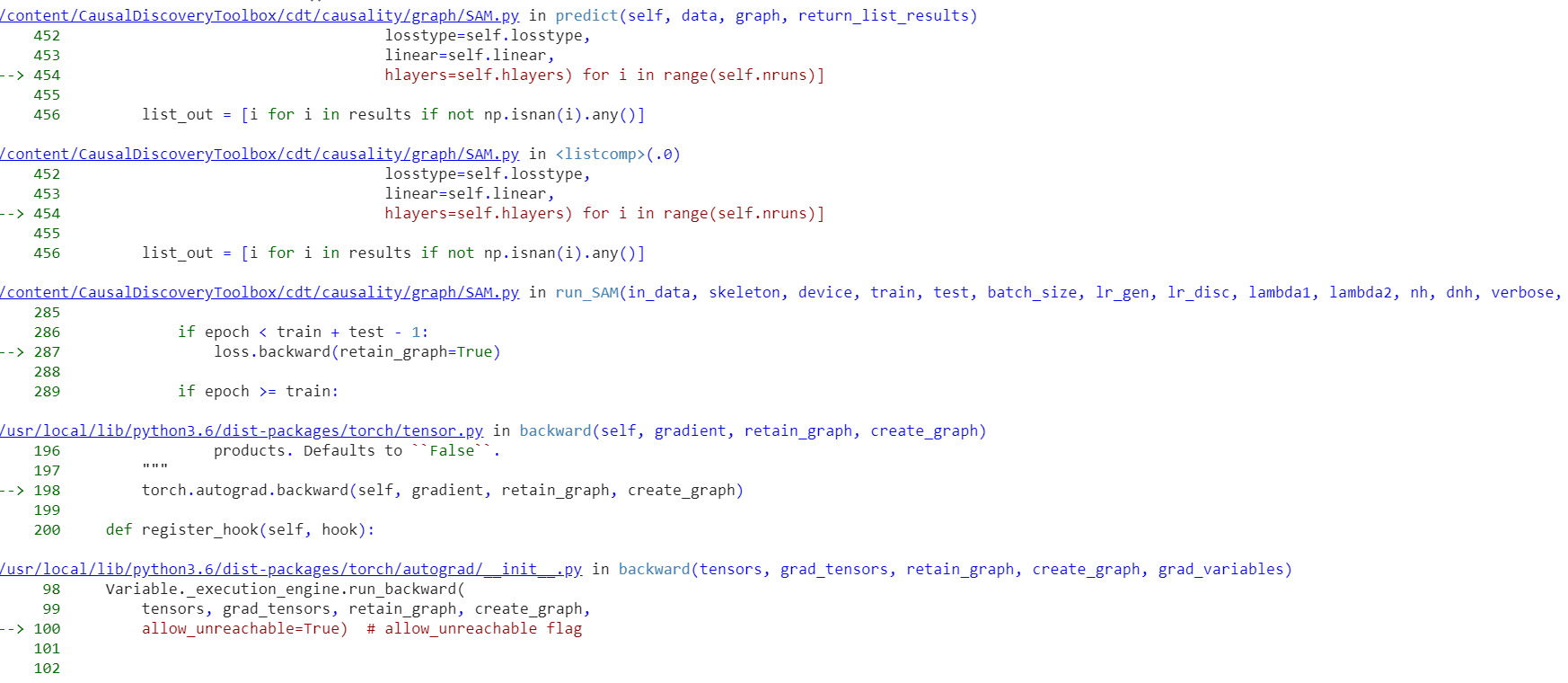
I tracked the error to the loss.backward() function in run_SAM() , there seems to be some operation that's being done inplace, couldn't find which one though, I'll dig deeper to see if there is some inconsistency.
Hi, Strange, this might come from the fact that we use an old version of PyTorch ; what version are you using ?
Hello, Pytorch version : '1.5.0+cu101' I did some further digging, and the error is being generated from the gen_loss part of the loss, I suspect it has something to do with the backward pass in the discriminator that's being done two times :
disc_vars_d = discriminator(generated_variables.detach(), batch)
disc_vars_g = discriminator(generated_variables, batch)
true_vars_disc = discriminator(batch)
if losstype == "gan":
disc_loss = sum([criterion(gen, _false.expand_as(gen)) for gen in disc_vars_d]) / nb_var \
+ criterion(true_vars_disc, _true.expand_as(true_vars_disc))
# Gen Losses per generator: multiply py the number of channels
gen_loss = sum([criterion(gen,
_true.expand_as(gen))
for gen in disc_vars_g])
elif losstype == "fgan":
disc_loss = sum([th.mean(th.exp(gen - 1)) for gen in disc_vars_d]) / nb_var - th.mean(true_vars_disc)
gen_loss = -sum([th.mean(th.exp(gen - 1)) for gen in disc_vars_g])
disc_loss.backward()
d_optimizer.step()
I did some digging with regards to the .detach() function and found the following description from the pytorch docs concerning the output of this function :
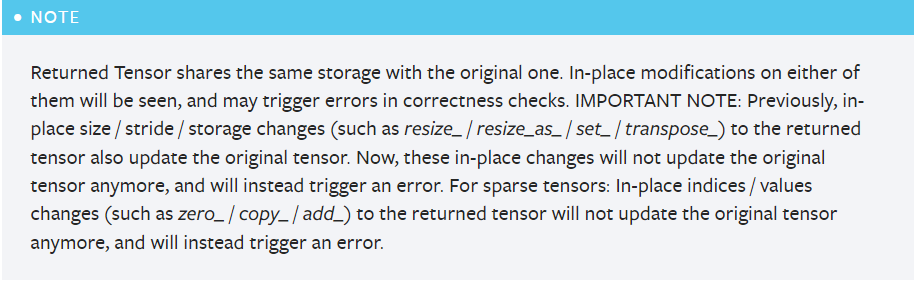
I tried replacing this with generated_variables.data and generated_variables.clone().detach() and i still get the same error. regards.
Thanks for your feedback, I will look into this next month as we are quite busy and thus unable to have a quick fix for this issue. please either use docker or rollback your Pytorch installation for the time being
This issue is due to your GAN implementation being incorrect. You update the discriminator after computing its predictions on generated data but before calling backward on the generator loss. The generator loss's graph involves the discriminator's forward pass (from before it's updated), so the update is an in-place op overwriting tensors that are needed for the generator loss backward, as the error message says.
PyTorch <= 1.4 masks the error because it doesn't register gradient updates as in-place ops during its pre-backward check (this should probably be considered a bug in PyTorch). So the code as it stands, when run on PyTorch <= 1.4, applies incorrect gradients to the generator.
Please fix the bug and update your publication with results from the corrected code.
Hello, the code is not up to date, the paper was modified with another implementation of SAM ; i still did not have time to repackage it into the CDT. I'll come back to it soon
Hello, The model has been updated taking account of this, and running using torch > 1.7.0 ; I took account of your remarks for the reimplementation, thanks @lagph !
Best, Diviyan