How to filter by sets of values
Hi, new to Pilosa and was curious about a use case.
In the Getting Started example with GitHub repositories, I see a lot of example queries like Row(stargazer=14) to get the repositories that stargazer 14 starred.
What if I wanted to get the repositories for a large subset of users? Something like
Row(stargazer IN (14, 22, 23, 50, 52, 53, ...) )
Is an operation like this possible in Pilosa today? Would it be performant with large lists of thousands or millions of values?
The only way I can see to do a query like this today is to do a long list of unions like Union(Row(stargazer=14), Row(stargazer=22), ...)
@skokenes - you can compose Row queries with boolean operators, so in your case:
Union(Row(stargazer=14), Row(stargazer=22), Row(stargazer=23), ...)
Union, Intersect, Difference, Xor, Not - all of them return the Row call, so you can also compose them, e.g.
Union(Intersect(...), Intersect(...), ...)
Thanks. Higher level question: is Pilosa suited for a use case like this where the Union may be hundreds of thousands or millions of queries? Ie lets say I had a list of 100k stargazer ids that I wanted to filter by. Would Pilosa work well here or is not suited for high cardinality querying?
Million is not high ;)
But if we talk about query length, you an take a look into Range queries. It really depends on use case.
@skokenes I'd be curious to understand the use case. We've had a user that composed a query made up of the union of 30,000 Pilosa rows, and that worked, but it's not typically what we see. A normal use case might have a query composed of, say a few row filters, up to a few dozen. But putting a million filters into the query isn't normal. That's not to say it wouldn't work, but it's why I ask about your use case; maybe there's a different way to model the data that will give you the result you're looking for.
Sure, I'll explain. I'm not sure Pilosa is the right fit for my use-case but its interesting to think through.
I am trying to model associations between multiple tables of data, with the linkages being through some key field. Take an ERD like this:
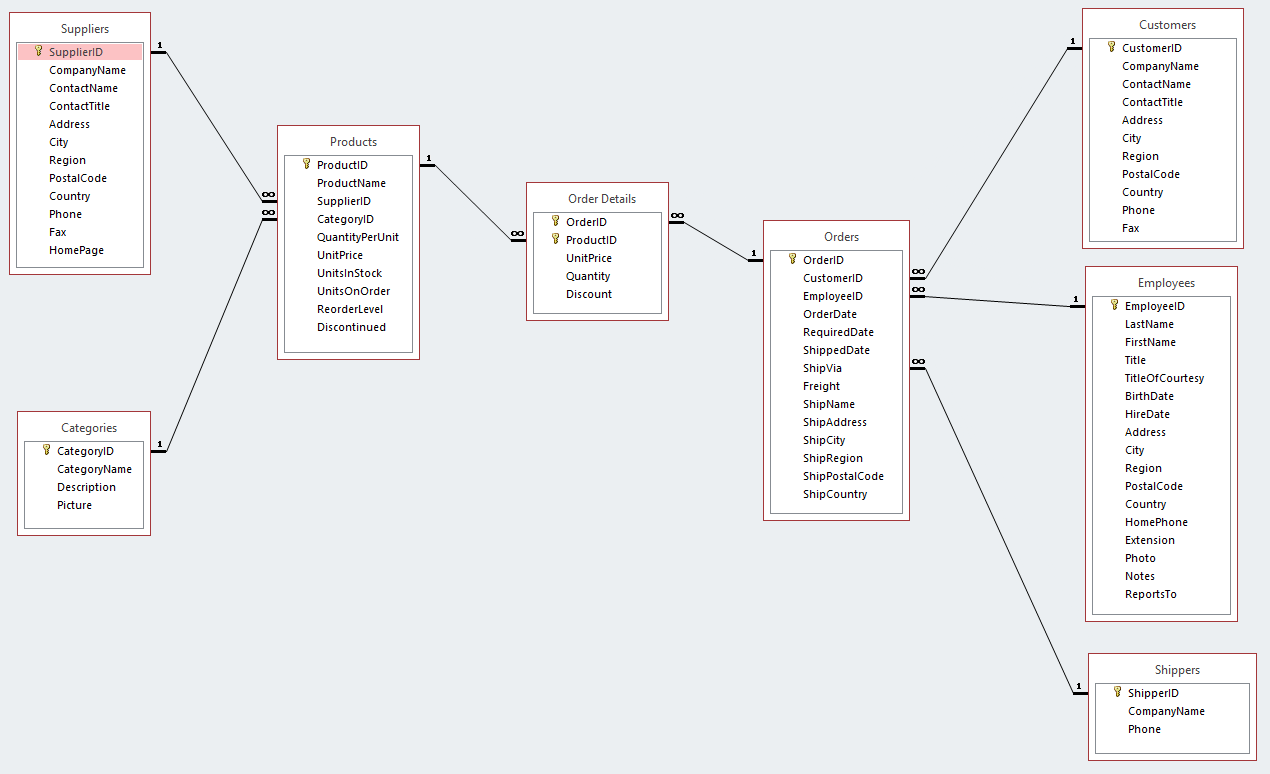
Suppose I filter the Products table with the predicate SupplierId=1. This would filter all the rows of the Products table that match that predicate, which would filter down the possible ProductId values. Then, those remaining ProductId values would be used as an input for filtering the linked Order Details table. So on and so forth until every linked table in the model has been filtered.
One idea I had is that each table in the model would get an index in Pilosa. Then, I was hoping to filter 1 table using an initial predicate, and then pass the key results to the other indices as filters. In my example above, its possible that list of possible key values to filter by could be in the thousands or millions.
How about one index per DB and field per Table (because you can merge bitmaps across fields from the same index).
In other words, imagine that you have one big table with all data and rotated as column DB. Then it may look as big boolean matrix (with ones on intersection value - record ID)