App
 App copied to clipboard
App copied to clipboard
[$250] Search for emojis using a suffix tree instead of a trie to get smarter matches
If you haven’t already, check out our contributing guidelines for onboarding and email [email protected] to request to join our Slack channel!
Action Performed:
Start typing :smile
Expected Result:
The soon-to-be-implemented emoji suggestions UI should produce not only results that begin with smile, like smile and smiley, but also things that contain smile as a substring, such as sweat_smile.
Actual Result:
Only emoji that begin with smile will come up in the search results.
Workaround:
n/a
Platform:
All
Triggered auto assignment to @adelekennedy (External), see https://stackoverflow.com/c/expensify/questions/8582 for more details.
cc @stitesExpensify in case you want to be co-assigned on this one as well
Triggered auto assignment to Contributor-plus team member for initial proposal review - @rushatgabhane (External)
Current assignee @roryabraham is eligible for the External assigner, not assigning anyone new.
This is hinted at in the issue title, but I think that a suffix tree will be the appropriate data structure to use for this search, since the emoji dataset is so large (and will likely continue to grow over time)
Also, note that this does not necessarily have to be on HOLD for https://github.com/Expensify/App/issues/12188, because even though we don't have the UI yet, we should be able to verify the correct behavior with unit tests, which will be a hard requirement for any PR to implement this issue.
@adelekennedy I think $500 is an appropriate starting value for this issue
Not sure how to implement a suffix tree, but there are a few really good and fast fuzzy search libs out there. One that comes to mind is fuse.js
const list = [
{
"text": "smile",
"emoji": "🙂"
},
{
"text": "smiley",
"emoji": "😁"
},
{
"text": "sweat_smile",
"emoji": "😅"
},
{
"text": "cheese_wedge",
"emoji": "🧀"
},
]
const options = {
includeScore: true,
shouldSort: true,
includeMatches: true,
findAllMatches: true,
threshold: 0.6,
distance: 100,
keys: ["text"]
};
const fuse = new Fuse(list, options);
// Change the pattern
const pattern = "smile"
return fuse.search(pattern)
Result:
[
{
"item": {
"text": "smile",
"emoji": "🙂"
},
"refIndex": 0,
"matches": [
{
"indices": [
[
0,
4
]
],
"value": "smile",
"key": "text"
}
],
"score": 2.220446049250313e-16
},
{
"item": {
"text": "smiley",
"emoji": "😁"
},
"refIndex": 1,
"matches": [
{
"indices": [
[
0,
4
]
],
"value": "smiley",
"key": "text"
}
],
"score": 0.001
},
{
"item": {
"text": "sweat_smile",
"emoji": "😅"
},
"refIndex": 2,
"matches": [
{
"indices": [
[
0,
0
],
[
2,
2
],
[
6,
10
]
],
"value": "sweat_smile",
"key": "text"
}
],
"score": 0.06
}
]
there are a few really good and fast fuzzy search libs out there. One that comes to mind is fuse.js
i wouldn't call Fuse fast or good, exactly. but i've done a pretty broad comparison of fuzzy match libs in the course of building uFuzzy.
https://github.com/leeoniya/uFuzzy#performance
@xyclos quick thoughts: I don't think filtering a list of emojis is a good usecase for an approximate string match algorithm.
We're searching on the keywords array. And fuse.js uses the bittap algorithm, which computes similarity between two strings using levenshtein distance (source).
This makes the result set have 522 results when entering smile (for eg: smirk is also in the result set because it has a levenshtein dist of 2 from smile).
Imo, 522 results would confuse the user. So something more predictable and exact would be nice. What do you think? I'm curious about your thoughts
@leeoniya 1,030 ms for uFuzzy vs 35,600 ms for fuse.js
That's pretty impressive! ✨
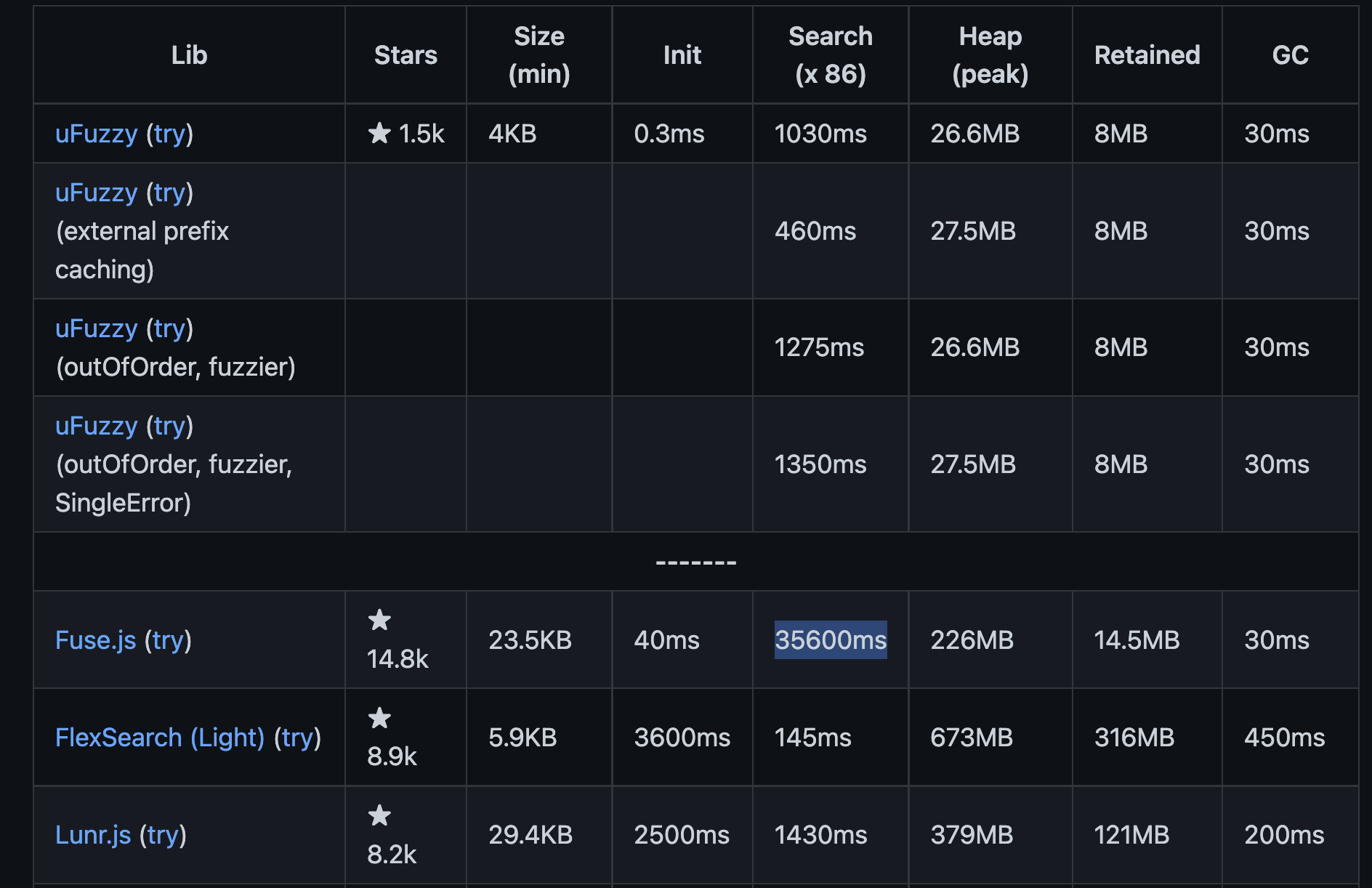
I agree with @rushatgabhane about not using a fuzzy search. For reference the Trie which is currently implemented finds emojis in 1-6ms.
I think a suffix tree as mentioned in the OP (which is very similar to a trie) is the correct data structure, and we should stick to that.
:+1: excited to see what you folks come up with! i'd be interested to add a Ukkonen suffix tree implementation to the bench table as well. btw, uFuzzy is not based on string distance metrics, since that typically produces garbage results!
out of curiosity i loaded up all the emoji keywords from https://github.com/Expensify/App/blob/main/assets/emojis.js and got 0.3ms matches, or 0.7ms for out-of-order partial terms. this is with 0 mem overhead, since there's no index.

@leeoniya those results are crazy fast! If you want to create a proposal, that sounds very promising!
I am a bit confused how there is 0 memory overhead since we would still have to create the data structure right? I'm also curious how long it takes to create that structure for our use case (seems like it should be fast using Ukkonen's algo).
the data structure is just the haystack string[]. if you dont have this array in mem already and have to concat/extract the keywords arrays, there would be some minimal additional allocs up front, but uFuzzy itself doesnt do anything to your haystack once it's made. the lib is regexp based and just processes that haystack in a linear/dumb fashion. pretty wild how fast it turned out! 🤯
EDIT: to be clear, there is obviously some overhead during searching but it's the lowest i've measured of any lib (about 20mb when searching 162k phrases, that haystack is an additional/persistent 8mb in mem but it's not an extra 8mb cause you at minimum need those strings in memory regardless)
@roryabraham we already have this feature because we are inserting the emoji name and its keywords into the Trie
i.e when inserting this emoji
{
code: '😀',
keywords: [
'face',
'grin',
],
name: 'grinning',
},
we aren't inserting a single emoji {name:'grinning', {code: '😀'}}
actually we are inserting something like this
{name:'grinning', {code: '😀'}}
{name:'face', {code: '', suggestions: [name:'grinning', {code: '😀'}]}
{name:'grin', {code: '', suggestions: [name:'grinning', {code: '😀'}]}
so when typing :fa in the composer we will see the grinning emoji
https://user-images.githubusercontent.com/108357004/199466664-d8475d43-95f9-4351-9fc4-389b739dfd9b.mov
@adelekennedy I'm going to snag this one from you if you don't mind, as I'd like to help with the broader tracking issue.
i grabbed your current Trie implementation to bench it against single terms: https://github.com/leeoniya/uFuzzy/tree/emojis-trie
i think @stitesExpensify's statement that your current code takes 1-6ms was likely measuring more than just the core search algorithm.
- the trie construction takes ~20ms (vs 0.5ms to boot uFuzzy)
- the trie retained ram use is ~2.9mb (vs 1.9mb for uFuzzy)
- the trie bench time is ~30ms (vs 110ms for uFuzzy)
so the trie is definitely faster than a regex match, at the cost of more mem and more index build time, as expected! when the overall numbers for a single match are this low in both cases (sub 1ms), the perf difference can probably be disregarded. no one will notice a 20ms boot time either. this may change significantly for much larger datasets since the trie size and init will grow more than linearly with dataset size.
the big difference of course is match quality. the trie only handles exact prefix matches and cannot handle multiple/combined partial terms, out of order matching, with minor misspellings. for that you need something more sophisticated. maybe that's not needed for this case, and that's a perfectly valid choice as well :+1:
EDIT: to be fair, you can actually implement out-of-order and multi-term matches by running several searches over the trie (one for each term/prefix in the needle) and intersecting those results.
you can run the bench locally on that branch via these urls after running http-server (from npm) in the repo root dir:
http://localhost:8080/demos/compare.html?libs=uFuzzy&lists=emojis&bench http://localhost:8080/demos/compare.html?libs=EmojisTrie&haystack=emojis&bench
to see the matches displayed, just remove &bench
@leeoniya Am I correct that a fuzzy search will get slower with larger datasets (which will certainly happen when we allow users to add custom emojis), whereas a suffix tree would not see any impact due to the search time being linear to the size of the search string rather than the size of the dataset?
I also wanted to mention that the suffix tree solution we recommended in the OP is both faster and takes less space than the trie we currently have implemented. You are correct that it still takes linear time to create though, so when the dataset grows that will be a bit slower.
As to your point about match quality it does seem like a fuzzy search could be the way to go (and similar to what slack does).

cc @quinthar in case you're interested, since I believe you wrote (or helped write?) our concierge fuzzy search.
I think fuzzy search makes sense, so typing things with small typos still gives you the match you're looking for, like @stitesExpensify last example
I'm less concerned about initialization time than search time, because that happens only once, on app initialization, and our current benchmarks for that are quite fast (~50ms). If if ever became a problem, we could also lazy-load the EmojiTrie so as not to block any UI except the emoji selector on its initialization.
quick thoughts: I don't think filtering a list of emojis is a good usecase for an approximate string match algorithm.
We're searching on the keywords array. And fuse.js uses the bittap algorithm, which computes similarity between two strings using levenshtein distance (source).
This makes the result set have 522 results when entering smile (for eg: smirk is also in the result set because it has a levenshtein dist of 2 from smile).
Imo, 522 results would confuse the user. So something more predictable and exact would be nice. What do you think? I'm curious about your thoughts
If we're deciding whether or not to use fuzzy search, we should give counter arguments to this comment first.
@leeoniya Am I correct that a fuzzy search will get slower with larger datasets (which will certainly happen when we allow users to add custom emojis), whereas a suffix tree would not see any impact due to the search time being linear to the size of the search string rather than the size of the dataset?
yeah, i would expect a trie or suffix tree to have better runtime scaling than fuzzy search, though by how much depends on how the fuzzy search is implemented (e.g. levenshtein in JS will scale worse than a regex that delegates to a C or asm backend).
If we're deciding whether or not to use fuzzy search, we should give counter arguments to https://github.com/Expensify/App/issues/12189#issuecomment-1296272527 first.
tl;dr; fuzzy !== levenshtein. relying on distance metrics alone for fuzzy search is guaranteed to produce poor results though it can do okay for single words with a distance of 1 or 2. there are many better ways to do it.
I'm less concerned about initialization time than search time, because that happens only once, on app initialization, and our current benchmarks for that are quite fast (~50ms). If if ever became a problem, we could also lazy-load the EmojiTrie so as not to block any UI except the emoji selector on its initialization.
tried with an emoji count of ~20k and get ~3.4ms per search, with out-of-order partial terms. but yes, a couple passes over a suffix tree would be faster than this. maybe in the range of 1-2ms?. not sure how much that matters in practice vs the other trade-offs.

tl;dr; fuzzy !== levenshtein. relying on distance metrics alone for fuzzy search is guaranteed to produce poor results though it can do okay for single words with a distance of 1 or 2. there are many better ways to do it
ooo im interested in how it works.
does it look for *s*m*i*l*e* ?
Still working through the ideal solution. @stitesExpensify for clarity, I'd imagine this is still not a priority until we close out the LHN API refactors?
Was chatting a bit with @JmillsExpensify and I think it might be a good idea to put this on HOLD so we can have a broader discussion about search features. I know emojis are the case-study here, but it's probably wise to take a step back here, evaluate our current and future needs, then design a performant, hopefully future-proof solution for search that will scale to meet our needs beyond just emojis.
@stitesExpensify This is probably perfect timing for you, now that the LHN API refactor is wrapped up. There isn't any immediate urgency for emoji search, so it'd be good to make sure where ever we land approximates the use cases we'll need across chats, requests, card transactions, attachments and similar biz/consumer flows.