Depth probably shouldn't be misused to return the current row index
https://github.com/ExcelDataReader/ExcelDataReader/blob/f2abb75d3b3063e97db9579723b798ef30f50ca7/src/ExcelDataReader/ExcelDataReader.cs#L37
The IDataReader.Depth property should return the depth of nesting for the current row which, I think, is not the same as row index.
https://docs.microsoft.com/en-us/dotnet/api/system.data.idatareader.depth?view=netframework-4.8
Would be a breaking change though.
Could a better explanation with an example be added. plz
Its not stopping me from doing anything, just for my own understanding.
I understood, Depth in regards to (rowReader.Depth) to be how deep it is in the Read().... So if its 0 based;
Read() Read() Read()
would be Depth: 2
Its basically is the row index, which is how it work now... from what i understand.
What im trying to understand, is an example of what the proper implementation would be:
depth of nesting for the current row
Thinking about it, does this become applicable when the sheet has some sort of complexity? beyond the norm, Like cells are merged or something?
what would the sheet need for the "Depth" if implemented "correctly" to be something other than the index.
Thanks
Depth is for readers that support nested results. I'm not aware of any implementation that support this. SQL Server and MySQL doesn't and their IDataReader.Depth implementations always return 0.
Wonder if its for something like subdatasheets in f.ex Access:
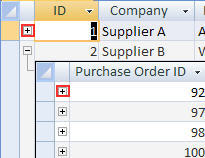
Seems the best fit per the the documentation remarks "The outermost table has a depth of zero."