Describing_a_Knowledge_Base
 Describing_a_Knowledge_Base copied to clipboard
Describing_a_Knowledge_Base copied to clipboard
Published
20 hours ago •
 EagleW
EagleW
Code for Describing a Knowledge Base
Describing a Knowledge Base
Accepted by 11th International Conference on Natural Language Generation (INLG 2018)
Table of Contents
- Model Overview
- Requirements
- Quickstart
- Citation
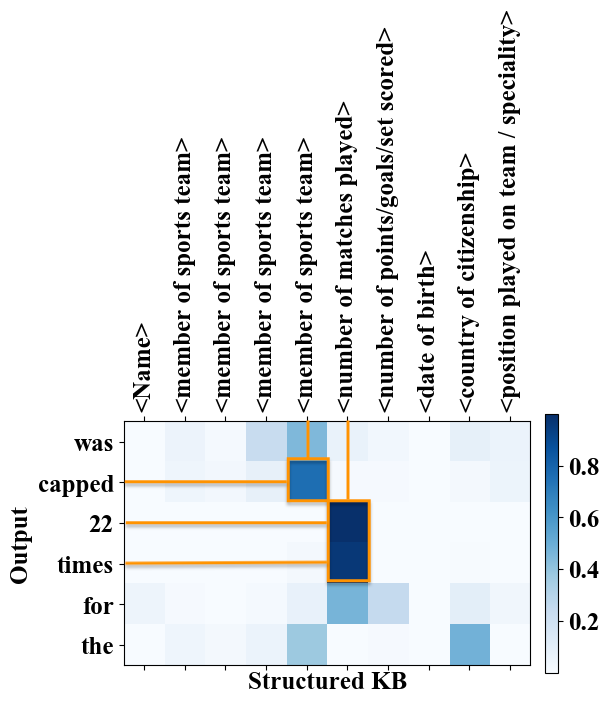
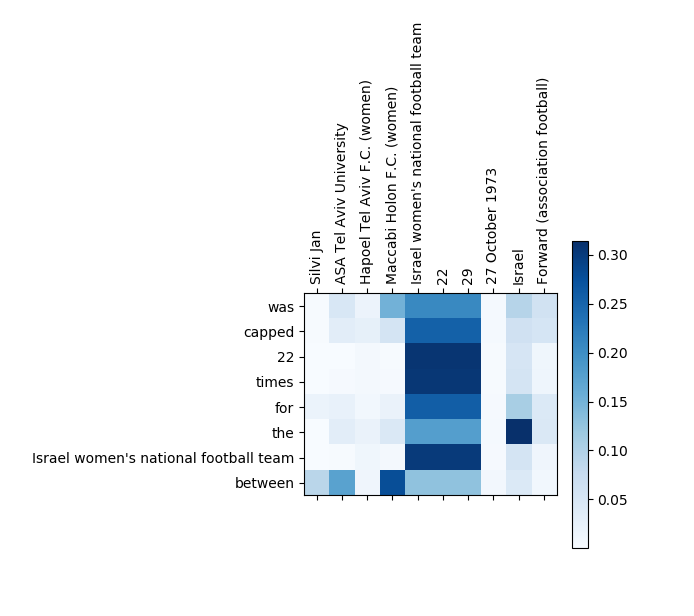
- Attention Visualization
Model Overview
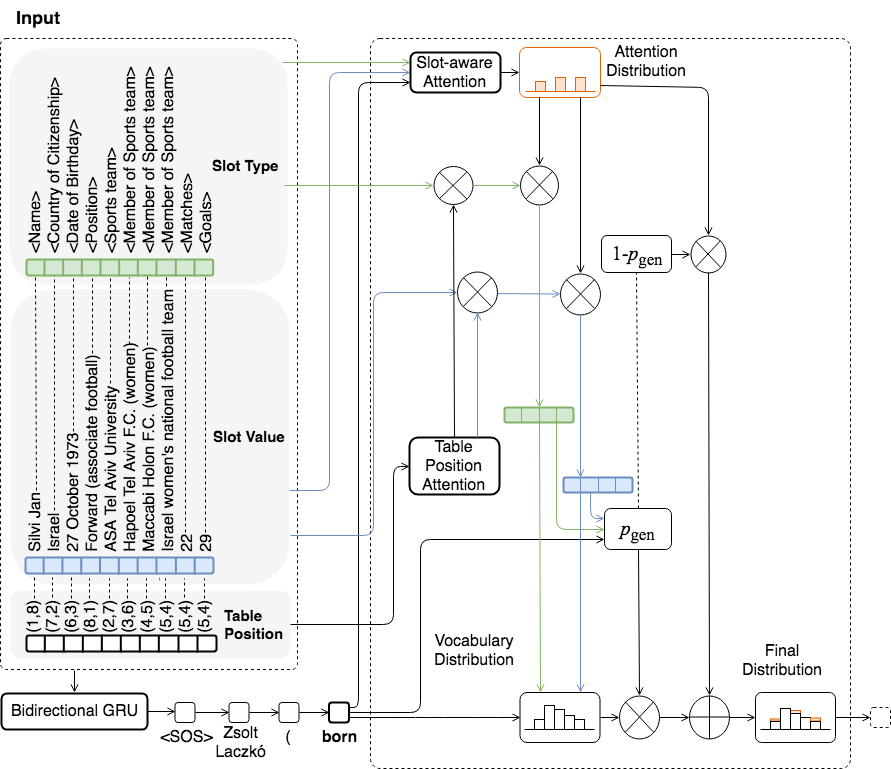
Requirements
Environment:
- Pytorch 0.4
- Python 3.6 CAUTION!! Model might not be saved and loaded properly under Python 3.5
Data:
-
Wikipedia Person and Animal Dataset
This dataset gathers unfiltered 428,748 person and 12,236 animal infobox with description based on Wikipedia dump (2018/04/01) and Wikidata (2018/04/12)
Quickstart
Preprocessing:
Put the Wikipedia Person and Animal Dataset under the Describing a Knowledge Base folder. Unzip it.
Randomly split the data into train, dev and test by runing split.py under utils folder.
python split.py
Run preprocess.py under the same folder.
You can choose person (type 0) or animal (type 1)
python preprocess.py --type 0
Training
Hyperparameter can be adjusted in the Config class of main.py and choose whether person (0) or animal (1) using type.
python main.py --cuda --mode 0 --type 0
Test
Compute score:
python main.py --cuda --mode 3
Predict single entity:
python main.py --cuda --mode 1
Citation
@InProceedings{W18-6502,
author = "Wang, Qingyun
and Pan, Xiaoman
and Huang, Lifu
and Zhang, Boliang
and Jiang, Zhiying
and Ji, Heng
and Knight, Kevin",
title = "Describing a Knowledge Base",
booktitle = "Proceedings of the 11th International Conference on Natural Language Generation",
year = "2018",
publisher = "Association for Computational Linguistics",
pages = "10--21",
location = "Tilburg University, The Netherlands",
url = "http://aclanthology.org/W18-6502"
}
Attention Visualization